
Groceries today. In the Before Time, this meant swinging by the store for fresh fruit and veggies while picking up something interesting for dinner that night. Now it means going to two stores (because shortages) standing in separated lines and getting two weeks of food. Very not fun
A Comprehensive guide to Fine-tuning Deep Learning Models in Keras (Part I)
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Collective Intelligence 2020 explores the impact of technology and big data on the ways in which people come together to communicate, combine knowledge and get work done. (Thursday June 18)

Attention seq2seq example
#COVID
- Tried to get the HuggingFace translator (colab here) to download and run, but I got this error: ‘Helsinki-NLP/opus-mt-en-ROMANCE’ ‘Unable to load vocabulary from file. Please check that the provided vocabulary is accessible and not corrupted‘ I’m going to try downloading the model and vocab into a folder within the project to see if something’s missing using these calls:
# to put the model in a named directory, load the model and tokenizer and then save (as per https://huggingface.co/transformers/quickstart.html): tokenizer.save('pretrained/opus-mt-en-ROMANCE') model.save('pretrained/opus-mt-en-ROMANCE')
GPT-2 Agents
- Read in multiple games
- Handled unconventional names
- Handling moves split across lines – done
- Need to handle promotion (a8=Q+), with piece change and added commentary. This is going to be tricky because the ‘Q’ is detected as a piece even though it appears after the location. Very special case.
- Rule: A pawn promotion move has =Q =N =R or =B appended to that.
- Create a short intro
- Save to txt file
GOES
- Read the GAN chapter of Generative Deep Learning last night, so now I have a better understanding of Oscillating Loss, Mode Collapse, Wasserstein Loss, the Lipschitz Constraint, and Gradient Penalty Loss. I think I also understand how to set up the callbacks to implement
- Since the MLP probably wasn’t the problem, go back to using that for the generator and focus on improving the discriminator.
- That made a big difference!



- The trained version is a pretty good example of mode collapse. I think we can work on improving the discriminator 🙂
- This approach is already better at finding the amplitude in the noise samples from last week!
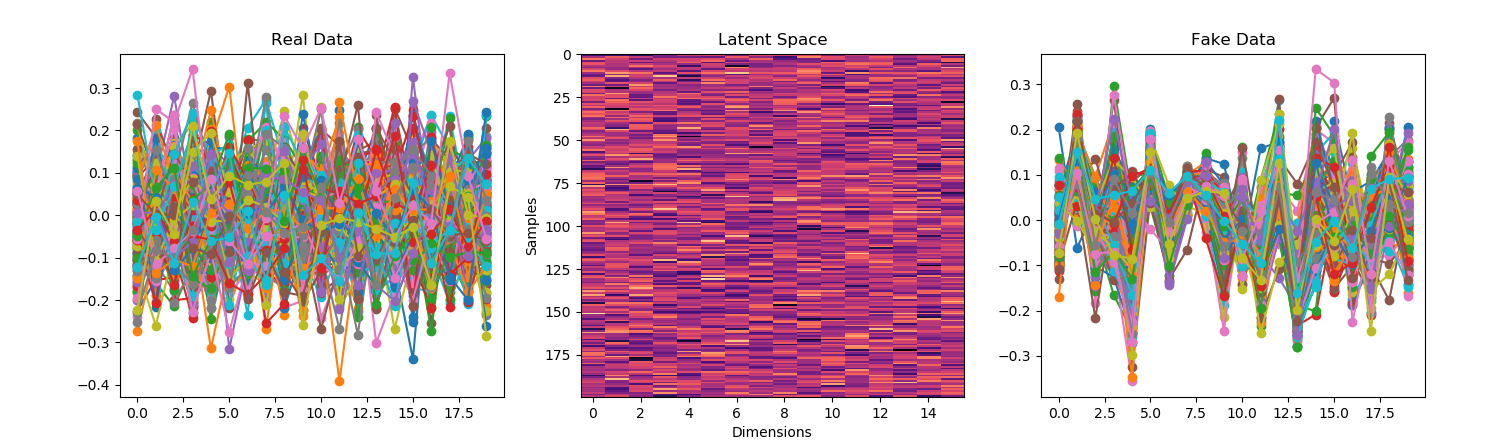
- Ok, going back to the sin waves to work on mode collapse. I’m going to have lower-amplitude sin waves as well
- That seems like a good place to start
- Conv1D(filters=self.vector_size, kernel_size=4, strides=1, activation=’relu’, batch_input_shape=(self.num_samples, self.vector_size, 1))


- Conv1D(filters=self.vector_size, kernel_size=6, strides=2, activation=’relu’, batch_input_shape=(self.num_samples, self.vector_size, 1)):


- Conv1D(filters=self.vector_size, kernel_size=8, strides=2, activation=’relu’, batch_input_shape=(self.num_samples, self.vector_size, 1))


- The input vector size here is only 20 dimensions. So this means that the kernel size is 80% of the vector! Conv1D(filters=self.vector_size, kernel_size=16, strides=2, activation=’relu’, batch_input_shape=(self.num_samples, self.vector_size, 1))


- Upped the vector size from 20 to 32
- Tried using MaxPool1D but had weird reshape errors. Doing one more pass with two layers before starting to play with Wasserstein Loss, which i think is a better way to go. First though, let’s try longer trainings.
- 10,000 epochs:


- 20,000 epochs:
