With these challenges in mind, we built and open-sourced the Language Interpretability Tool (LIT), an interactive platform for NLP model understanding. LIT builds upon the lessons learned from the What-If Tool with greatly expanded capabilities, which cover a wide range of NLP tasks including sequence generation, span labeling, classification and regression, along with customizable and extensible visualizations and model analysis. (GitHub)
Read and annotate Michelle’s outline, and add something about attention. That’s also the core of my response to Antonio
More cults
2:00 Meeting
Thinking about how design must address American Gnosticism, and the danger and opportunities of online “research”, and also how things like maps and diversity injection can potentially make profound impacts
GOES
Update test code to use least squares/quaternion technique
Looks like we are getting close to ingesting all the new data
Had a meeting with Ashwag last night (Note – we need to move the time), and the lack of ‘story-ness’ in the training set is really coming out in the model. The meta information works perfectly, but it’s wrapped around stochastic tweets, since there is no threading. I think there needs to be some topic structure in the meta information that allows similar topics to be grouped sequentially in the training set.
3:30 Meeting
GOES
9:30 meeting
Update code with new limits on how small a step can be. Done, but I’m still having normal problems. It could be because I’m normalizing the contributions?
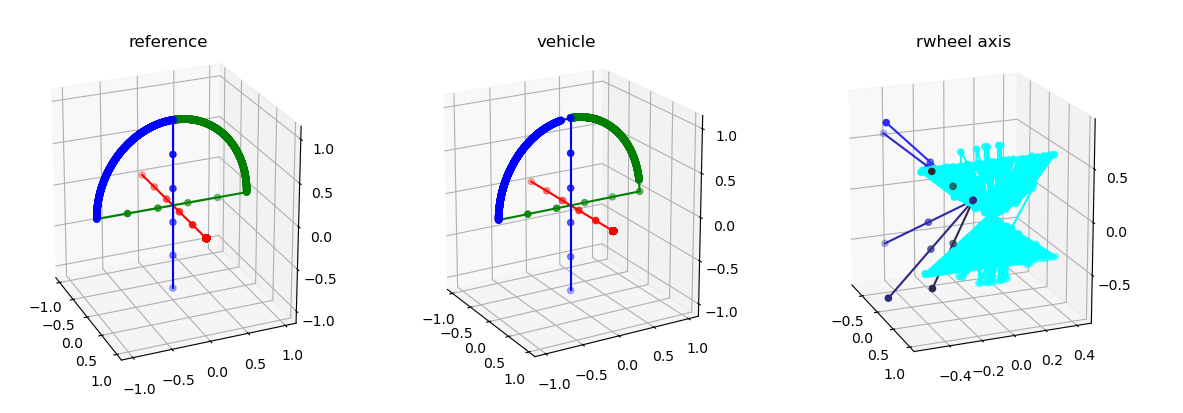
Need to fix the angle rollover in vehicle (and reference?) frames. I don’t think that it will fix anything though. I just don’t get why the satellite drifts after 70-ish degrees:
There is something not right in the normal calculation?
Got my panda3D text positioning working. I create a node and then attach the text to it. I think that’s not needed, that all you have to do is use render rather than the a2* options. Here’s how it works:
for n in self.tuple_list: ls:LineSegs = self.lp.get_LineSeg(n) node = TextNode(n) node.setText(n) tnp:NodePath = self.render.attachNewNode(node) #tnp.set_pos(-1, ypos, 1) tnp.setScale(0.1) self.text_node_dict[n] = tnp
I then access the node paths through the dict
Book
Spent a good chunk of the morning discussing the concept of dominance hierarchies and how they affect networks with Antonio
Need to write some, dammit!
GOES
My abstract has been accepted at the Military Operations Research Symposium’s (MORS) 4 day workshop in November!
More Replayer. Working on text nodes. Done! It looks good, and is pointing out some REALLY ODD THINGS . I mean, the reaction wheel axis are not staying with the vehicle frame…
10:00 meeting with Vadim
The (well, a) problem was that the reaction wheel vectors weren’t being reset each time, so the multiplies accumulated. Fixed! Now we have some additional problems, but these may be more manageable:
Got the points moving based on the spreadsheet. I need to label them. It looks pretty straightforward to use 3D positions? I may have to use Billboards to keep things pointing at the camera
Look into Prof. Kristin Du Mez (Calvin College – @kkdumez)’s book (Jesus and John Wayne)?
More writing
Meeting with Michelle. Came up with an interesting tangent about programming/deprogramming wrt software development and cults
GPT-2 Agents
Adding an optional split regex to parse_substrings. Here’s how I wound up doing it. This turns out to be slightly trickey, because the matches don’t include the text we’re interested in, so we have a step that splits out all the individual texts. We also throw away the text that leads to the first line and the last line of text since both can be assumed to be incomplete
split_regex = re.compile(r"(?=On [a-zA-Z]+ of [0-9]+,)") split_iter = split_regex.finditer(tweet_str) start = 0 tweet_list = [] for s in split_iter: t = tweet_str[start: s.start()] tweet_list.append(t) start = s.start()
Shimei’s presentation went well!
Work on translation
GOES
Start on playback of the vehicle and reference frames
A historian believes he has discovered iron laws that predict the rise and fall of societies. He has bad news.
GPT-2 Agents
Tried Sim’s model, it’s very nice!
Created a base class for creating and parsing tweets
Found a regex that will find any text between two tokens. Thanks, stackoverflow!
Here’s an example. I need to look into how large the meta information should be before it starts affecting the trajectory
On July of 2020, @MikenzieCromwell (screen name "Mikenzie Cromwell", 838 followers) posted a tweet from Boston, MA. They were using Twitter Web App. The post had 0 replies, 0 quotes, 1 retweets, and 3 favorites. "An example of the importance of the #mentalhealth community's response to #COVID19 is being featured in the @WorldBank survey. Check out the latest #MentalHealthResponse survey data on the state of mental health services in the wake of the pandemic. https://t.co/9qrq4G4XJi"
GOES
More Replayer
Got the vertex manipulation! It’s hard to get at it though the geometry, but if you just save the LineSegs object,
ls = LineSegs(name) self.prim_dict[name] = ls
you can manipulate that directly
ls:LineSegs = self.lp.get_LineSeg("test_line") ls.setVertex(1, x, y, z)
Meeting with Vadim at 10:00. We found some pretty bad code that sets the torques on the reaction wheels
Splitting the results on the probes. It looks like the second tweet in a series is better formed. That kind of makes sense, because the second tweet is based on the first. That leads to an interesting idea. Maybe we should try building chains of text using the result from the previous
Generating text with 1000 chars and parsing it, throwing away the first and last element in the list. I can also parse out the tweet, location, and sentiment:
[1]: In December of 2019, @svsvzz (21046 followers, 21784 following) posted a retweet, mentioning @ArticleSpot. It was sent from Saudi Arabia. @svsvzz wrote: "RT @ArticleSpot New update # Comment_study is coming..". The retweet was categorized as "Neutral".
Location = Saudi Arabia
Sentiment = Neutral
Tweet = RT @ArticleSpot New update # Comment_study is coming..
[2]: In December of 2019, @HussainALhamad (2340 followers, 29 following) posted a retweet, mentioning @ejazah_ksa. It was sent from Riyadh, Saudi Arabia. @HussainALhamad wrote: "RT @ejazah_ksa Poll: Do you support #Suspension of studying in #Riyadh tomorrow, Monday? If you support (Retweet) If you do not support (Like)". The retweet was categorized as "Positive".
Location = Riyadh, Saudi Arabia
Sentiment = Positive
Tweet = RT @ejazah_ksa Poll: Do you support #Suspension of studying in #Riyadh tomorrow, Monday? If you support (Retweet) If you do not support (Like)
[3]: In December of 2019, @mahfouz_nour (11 followers, 57 following) posted a tweet. She wrote: "♪ And the rest of the news about a news that the study was suspended in the study ♪ ♪ And God bless you ♪ ♪ Now ♪". The tweet was categorized as "Negative".
Location = None
Sentiment = Negative
Tweet = ♪ And the rest of the news about a news that the study was suspended in the study ♪ ♪ And God bless you ♪ ♪ Now ♪
[4]: In December of 2019, @tansh99huda99 (1211 followers, 519 following) posted a retweet, mentioning @HashKSA. @tansh99huda99 wrote: "RT @HashKSA # comments on Monday at all schools for students in #Dahan, and the decision does not include teachers' and teachers' levels.". The retweet was categorized as "Neutral".
Location = None
Sentiment = Neutral
Tweet = RT @HashKSA # comments on Monday at all schools for students in #Dahan, and the decision does not include teachers' and teachers' levels.
Created some slides. I think they look pretty good:
Nearly half of the voters have seen Trump in all of his splendor—his infantile tirades, his disastrous and lethal policies, his contempt for democracy in all its forms—and they decided that they wanted more of it.
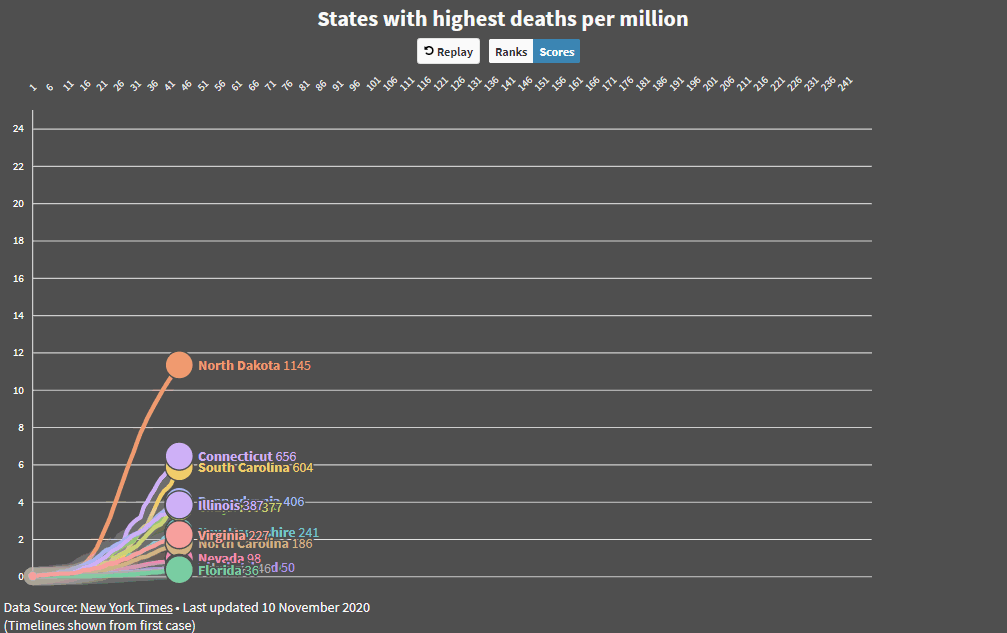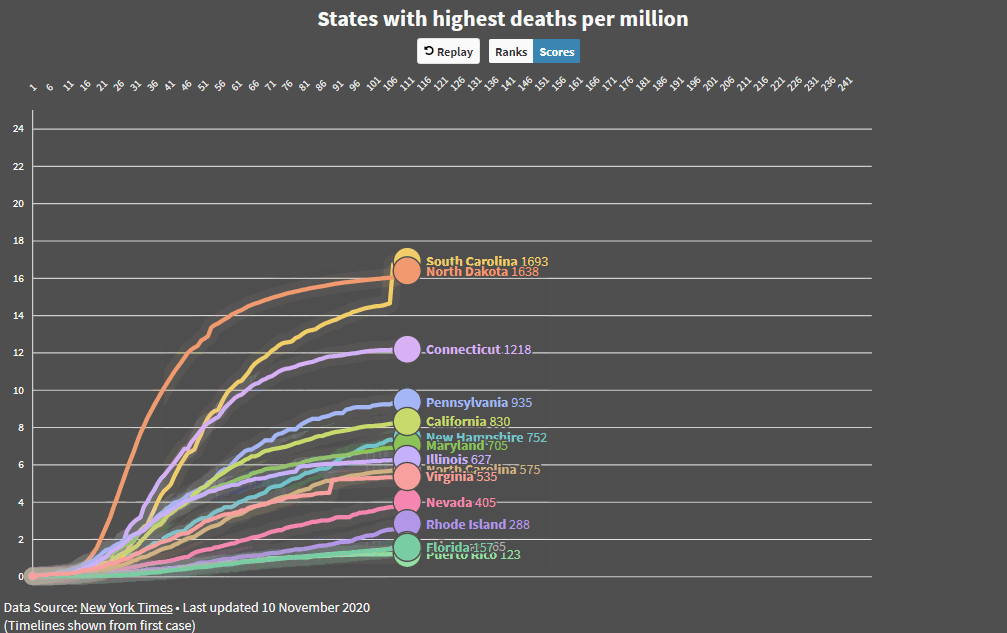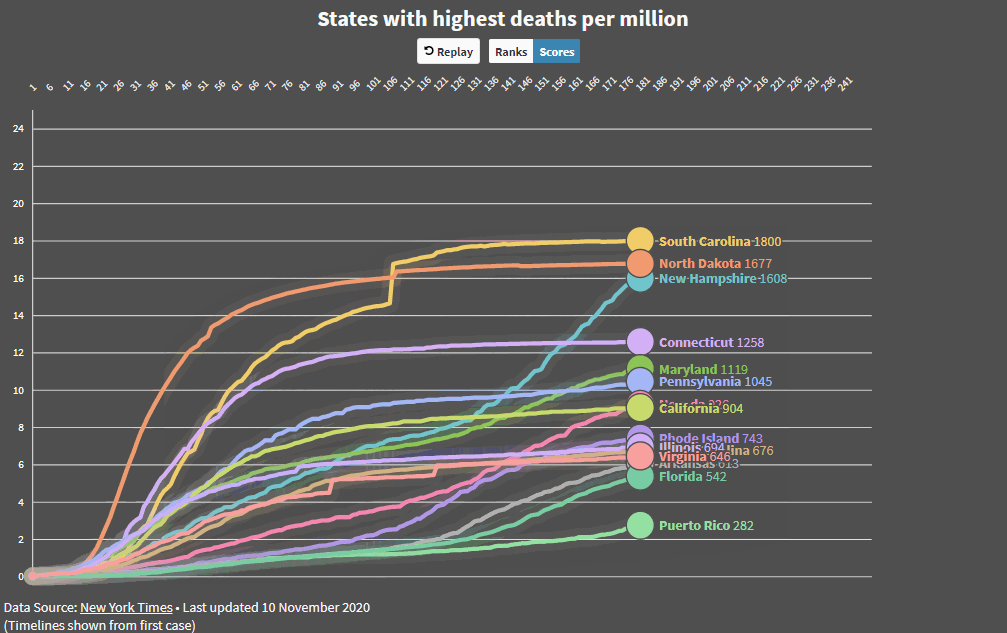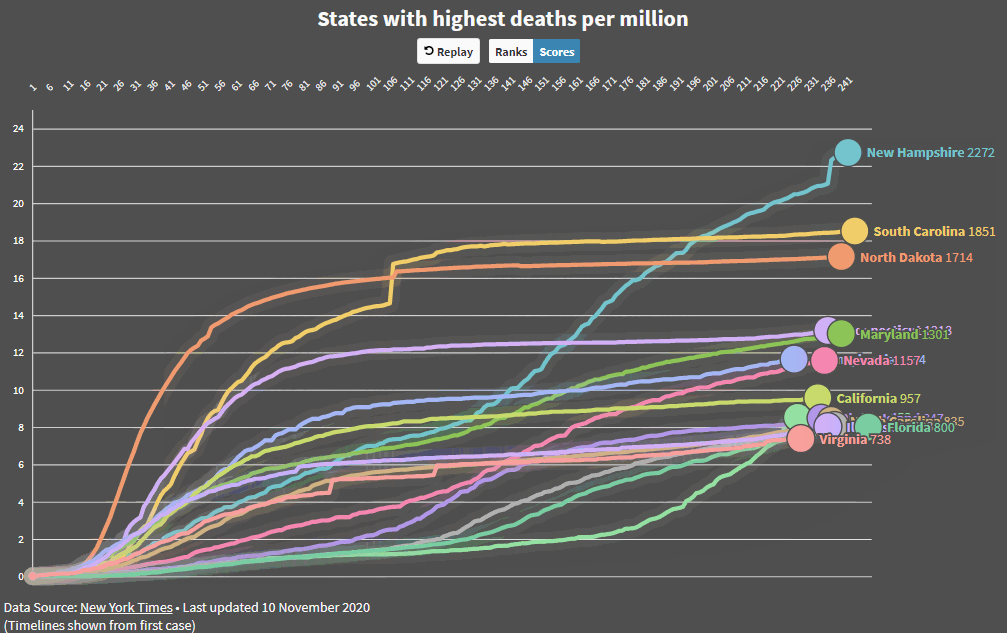
Added some code that makes it easier to compare countries and states and produced an animated GIF. I’m more concerned about Maryland now!
Went down to DC yesterday. So weird to see the White House behind multiple sets of walls, like a US base in Afghanistan
Dentist at 3:00
GPT-2 Agents
Working on generating a new normalized data set. It needs to be mush smaller to get results by the end of the week. Done. It takes a couple of passes through the data to get totals needed for percentages, but it seems to be working well
Restarted training
Topic extraction from Tweet content
GOES
Started working on 3D view of what’s going on with the two frames. I think I’m just going to have to start over with a a smaller codebase though, if Vadim can’t find what’s going on in his code.
I went on a long ride yesterday and the Trump signs that I’ve seen since 2015 are largely gone. The “Don’t tread on me” flags were still there. I wonder if it’s Trump fatigue?
GPT-2 Agents
I had a brief flicker of a power failure that killed the training. I need to figure out how to restart from a checkpoint
Need to normalize tweets by month and also subsample
Took off yesterday and had a great time enjoying the weather and riding up to Gettysburg. And not thinking too much
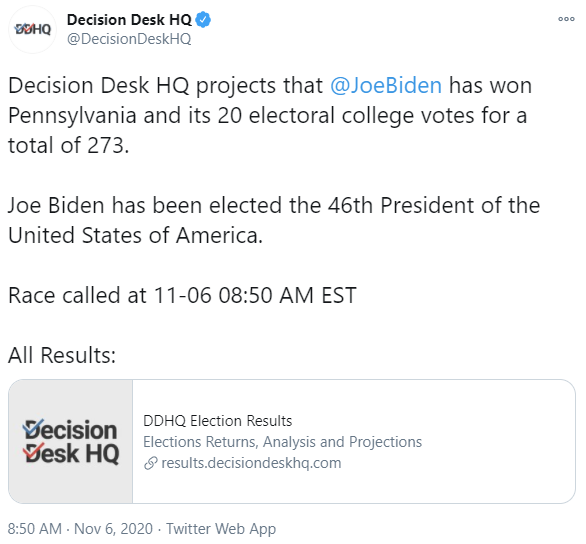
Via Washington Post (Captured 11.6.2020 0600 EST
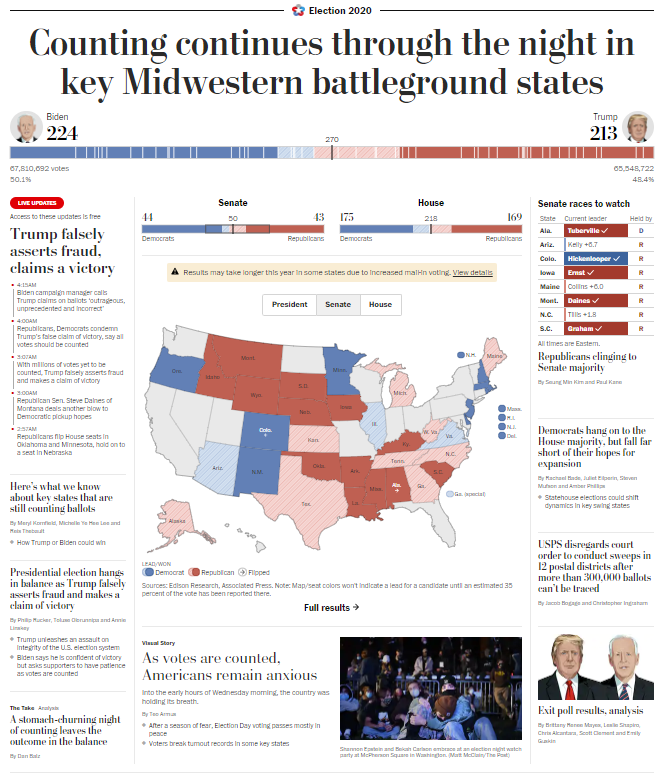
There is also this
And later, this
GOES
10:00 Meeting with Vadim. If there is no progress, I’m going to build a display that plays back the recorded data so we can see what’s going on. He can’t make it, so postponed to Monday. I’ll start on the app after my other paperwork
NESDIS
More paperwork
GPT-2 agents
Respond to JF’s email and set up a meeting – done
Hopefully finish the current training run.
Adjust the code so that a query for the count of each month is made, and the results are normalized over each month. That means a query that gets the count and min/max row_ids
Work on NMF and LDA topics for MER tweets. Do topics for the whole dataset (just the tweets), then select the ones that seem to make sense, and use them on the model-generated text. Create wordclouds from the topic labels
Got the NMF and LDA code into separate files. Need to change the get_content() method to pull directly from the db
..when when this came up with my students so my students they’re just an awesome group. I had this is two years ago i would say you know probably 18 of them probably 15 of them identified as like gun rights people right so they were they they owned guns themselves or they were all in favor of gun rights. And like every time the AR-15 came up and they’re just like “that’s this is just stupid culture war like that’s why people buy the gun.” These are like these are students who themselves are like gun rights people or gun owners and like that’s why people buy it it’s a culture war thing. I mean look at that guy in St Louis right who who pulled out his AR-15 and was aiming it at the protesters. Like what the hell is that guy doing with that gun? It’s total culture war stuff. It’s you know as we’d say like virtue signaling or something like that and that that’s what it is it’s saying. Like this it’s it’s it’s voting by buying a gun.”
Adding some content from Chimpanzee Politics and working with the Moby Dick section. I think that’s coming together now. Need to talk about how Starbuck continues to have his own thoughts, but goes along with the consensus of the ship, even though he suspects that this will kill him
GPT-2 Agents
Meeting with Sim and Shimei. We’re going to focus on getting some preliminary results for the 13th
Looked at the results for the medium model and all agree that it looks much better. Going to train the





















You must be logged in to post a comment.