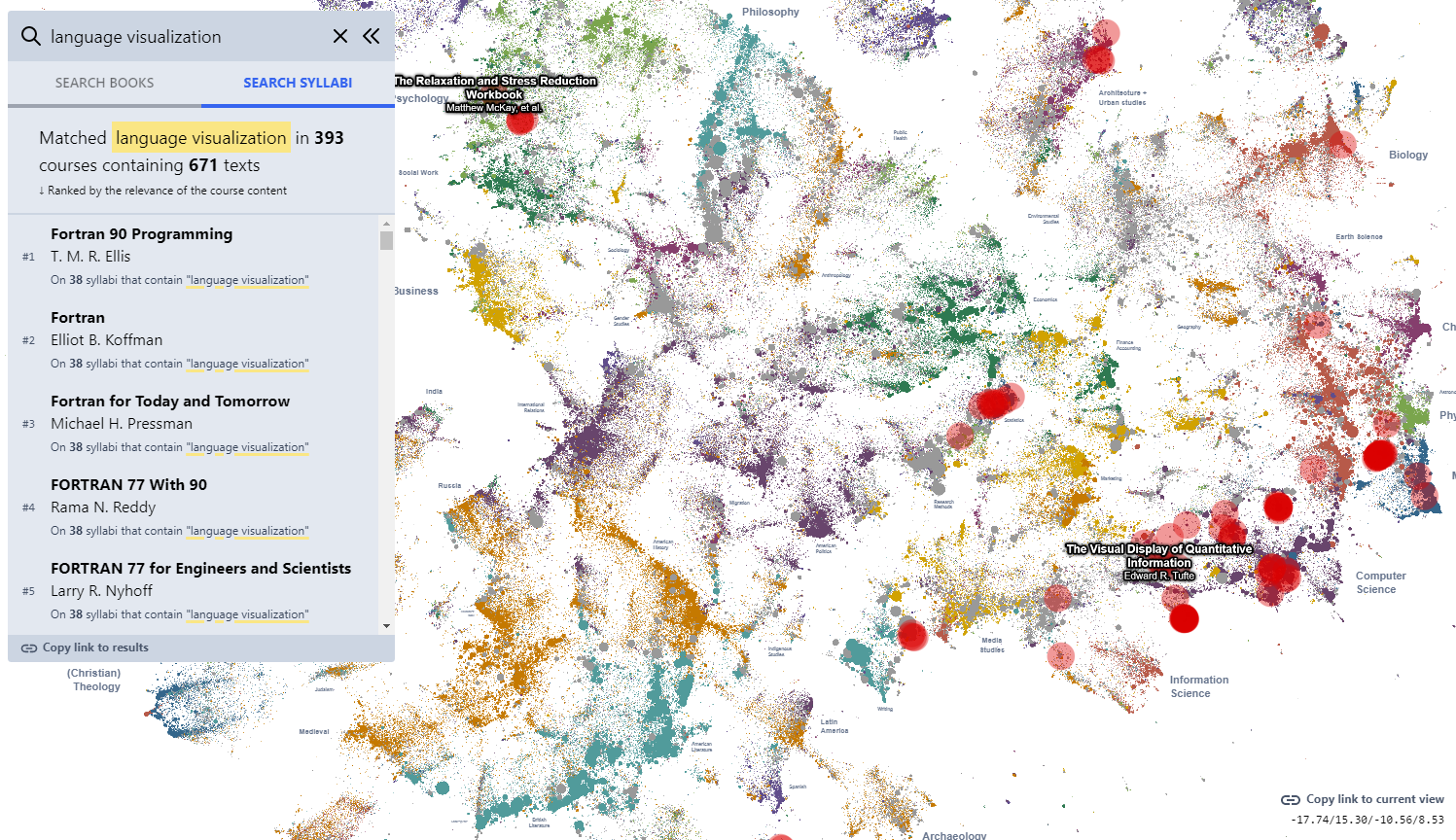
Today we’re excited to release a big update to the Galaxy visualization, an interactive UMAP plot of graph embeddings of books and articles assigned in the Open Syllabus corpus! (This is using the new v2.5 release of the underlying dataset, which also comes out today.) The Galaxy is an attempt to give a 10,000-meter view of the “co-assignment” patterns in the OS data – basically, which books and articles are assigned together in the same courses. By training node embeddings on the citation graph formed from (syllabus, book/article) edges, we can get really high-quality representations of books and articles that capture the ways in which professional instructors use them in the classroom – the types of courses they’re assigned in, the other books they’re paired with, etc.
Run Sim’s Queries and add to spreadsheet (need to create a view that uses text from extended tweet if available):
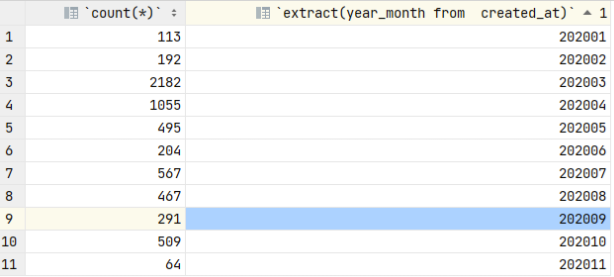
#to get week number (in range 0-53 ) from date
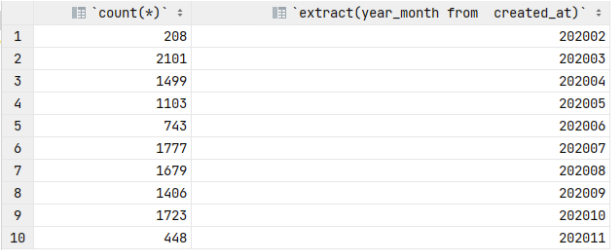
select count(*) as COUNT, extract(WEEK from created_at) as WEEK from twitter_root where text like “%chinavirus%” group by extract(WEEK from created_at) order by extract(WEEK from created_at);
#to drill down from month to week and week to day for March and April since they have significantly larger volume of data
select count(*) as COUNT, date(created_at) as DATE from twitter_root where text like “%chinavirus%” and (month(created_at) = 3 or month(created_at) = 4) and year(created_at) = 2020 group by date(created_at) order by date(created_at);
Figured out how to do this:
create or replace view long_text_view as select tr.row_id, tr.created_at, case when extended_tweet_row_id <> 0 then et.full_text else tr.text end as long_text from twitter_root tr left join extended_tweet et on tr.extended_tweet_row_id = et.row_id;
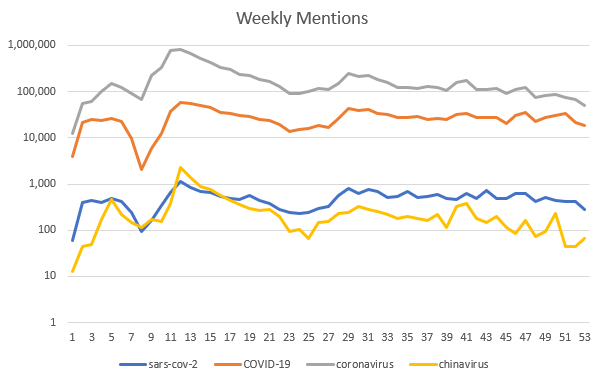
This is kind of cool. The chinavirus is most peaky but low volume. The sars-cov-2 is low volume but flatter, and the more common terms are pretty similar with gentler peaks and slower falloff. I want to know what that dip isaround week nine, and the peak at week 5 in the chinavirus plot.
Mass vaccine clinics have been added by the State of Maryland. You can register at: https://massvax.maryland.gov
Book
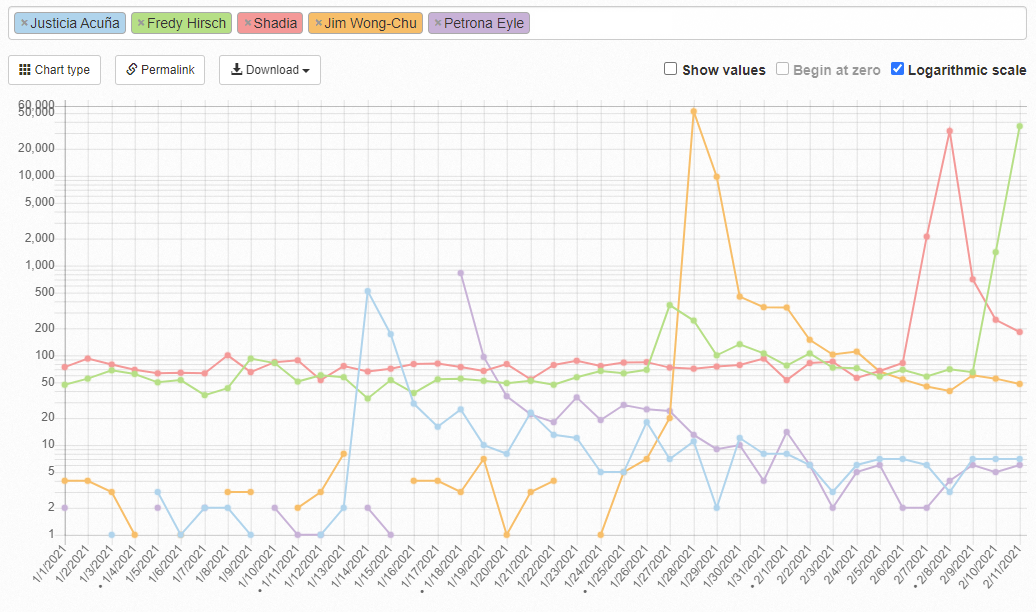
Google Doodle and some other diversity injection? I’d love to fine a Maker example
GPT Agents
Create training data
3:30 Meeting. Nice progress. This is pretty cool:
Counts by month for “chinavirus”Counts by month for “coronavirus”Counts by month for “sars-cov-2”
These haven’t been normalized, but there seems to be a big spike for chinavirus early in the pandemic, which is what I’d expect for stampede-like behavior. Coronavirus has more mentions, and it’s also more spread out and slowly starts to die out as it is incorporated into daily life and other things grab our attention. Sars-Cov-2 follows a different pattern of periodic relative higher and lower interest but doesn’t seem to change that much which is what I would expect for explorer behavior.
GOES
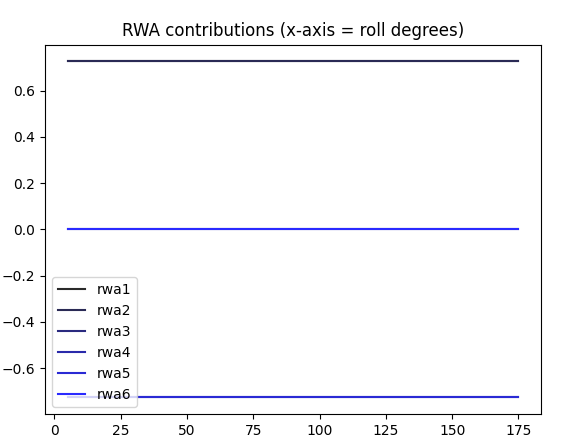
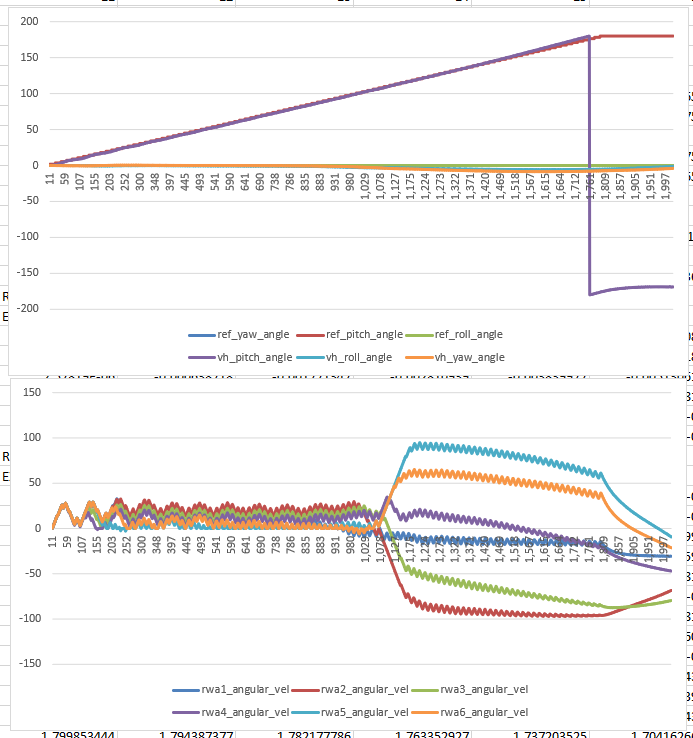
11:00 Meeting with Vadim. I’d like to work out the best way to adjust the reaction wheel efficiency. Currently it’s done by adjusting angular velocity in AngleController but I think that the efficiency should be adjusted in the sim code. Also, we need to have the “reset” code that can move the vehicle back to the start position without using physics.
Nice little number sequence of a day. For the US at least.
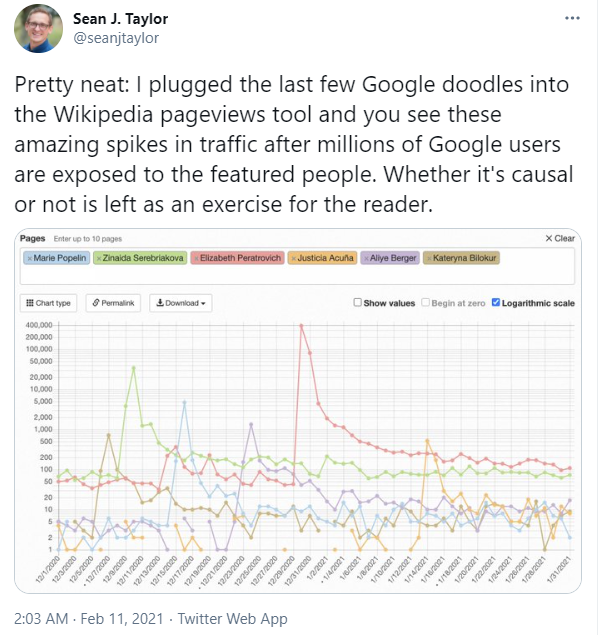
Cool thing! This is pageviews.toolforge.org, that lets you look at and compare Wikipedia page views. These are subjects of recent Google Doodles, which shows the power of diversity injection using ‘random’ prompts.
Add code to AngleController for RW efficiency – done. Not sure if the scripted reaction wheel efficiency failures is being applied correctly. Right now it’s in AngleController as a commanded value to the Rwheels. I think it should probably be handled in the simulation proper
Add padding to DictionaryEntries for variables that are added later – done
A graph is hypothetical structure that does not exist in the real world. Any real world data representation may be reduced to a graph, but it is NOT a graph. A network topology can be first reduced to a graph and then algorithms like Dijkstra’s and Kruskal’s can be applied to it for various purposes like routing. All real world situations are subsets of graph problems (of that domain). Most problems of networking, especially those concerning routing reduce to a graph based problem. You will never find a graph in real world scenario. But you will find its subsets or derivatives in practical applications.
Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the input sequence length has limited its application to longer sequences — a topic being actively studied in the community. To address this limitation, we propose Nyströmformer — a model that exhibits favorable scalability as a function of sequence length. Our idea is based on adapting the Nyström method to approximate standard self-attention with O(n) complexity. The scalability of Nyströmformer enables application to longer sequences with thousands of tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard sequence length, and find that our Nyströmformer performs comparably, or in a few cases, even slightly better, than standard Transformer. Our code is at this https URL.
Book – Working on snippets
GPT Agents
10:00 Meeting with Jay Alammar – that went *really* well!
3:00 Meeting that I’m going to be a bit late for
GOES
11:00 Meeting with Vadim
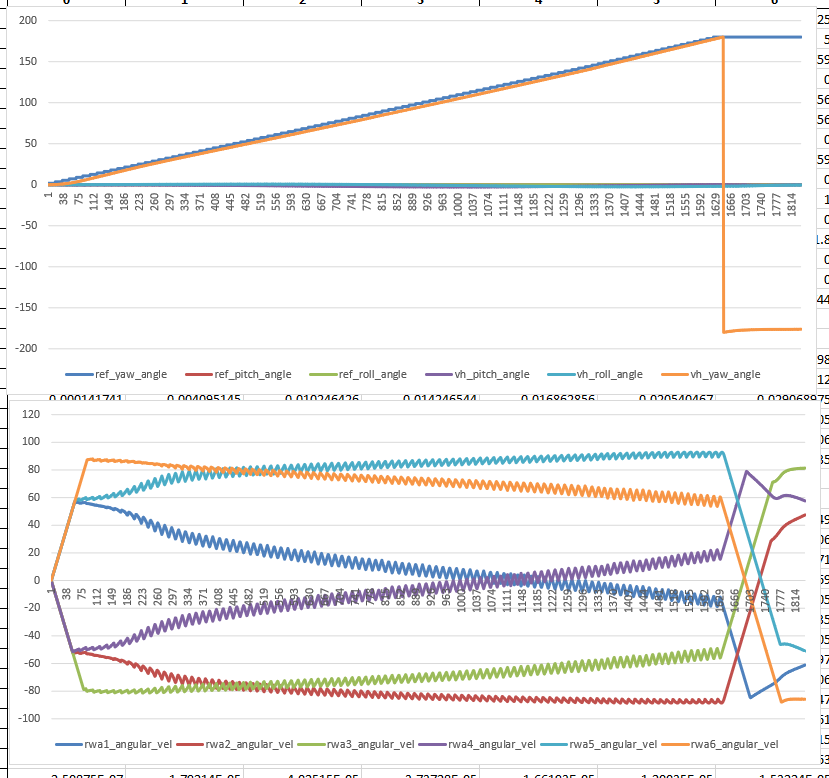
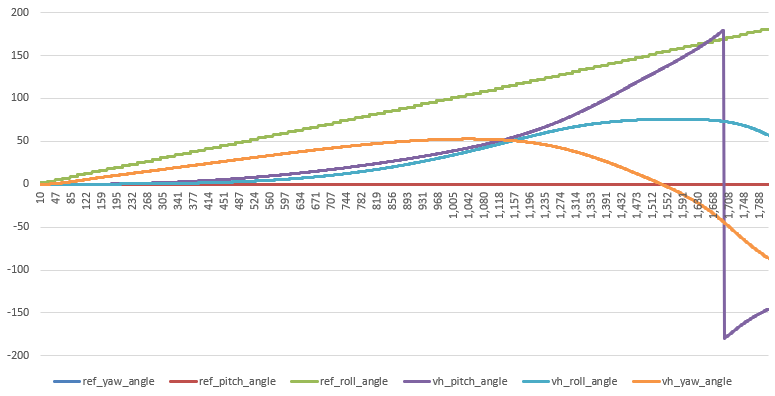
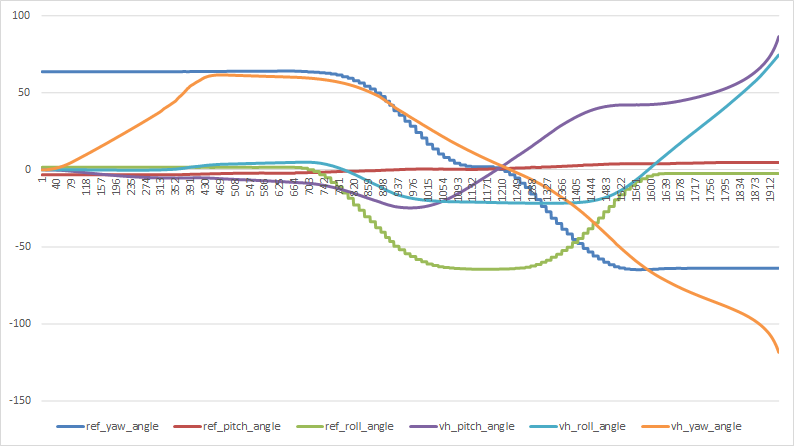
Nothing obvious about the roll problems, but that shouldn’t stop the work on getting the pitch maneuver running and generating data
Add rwheel efficiencies to the script in some kind of loop
Adjust AngleController to use rwheel efficiency from the ddict
Got my intersection code running well
10:00 Meeting for first period report. Hopefully we’ll be able to get a meeting with the TPOC next week to see what he wants?
As for the party’s base, what policy issues are MAGA rally-goers wound up about? Not the deficit or taxes, and not the ACA. In the past, those issues gave expression to their underlying grievances, but no longer. After the election, one GOP polling firm asked Republicans about their biggest concerns for a post-Trump Republican Party. Forty-four percent wanted a party that would “fight like Donald Trump,” while only 19 percent worried that a post-Trump GOP would “abandon Donald Trump’s policies.”
Book
Work on short descriptions
GPT Agents
More Ecco. Set up meeting for tomorrow morning? Yes! 10:00
GOES
11:00 Meeting with Vadim. Rescheduled for tomorrow
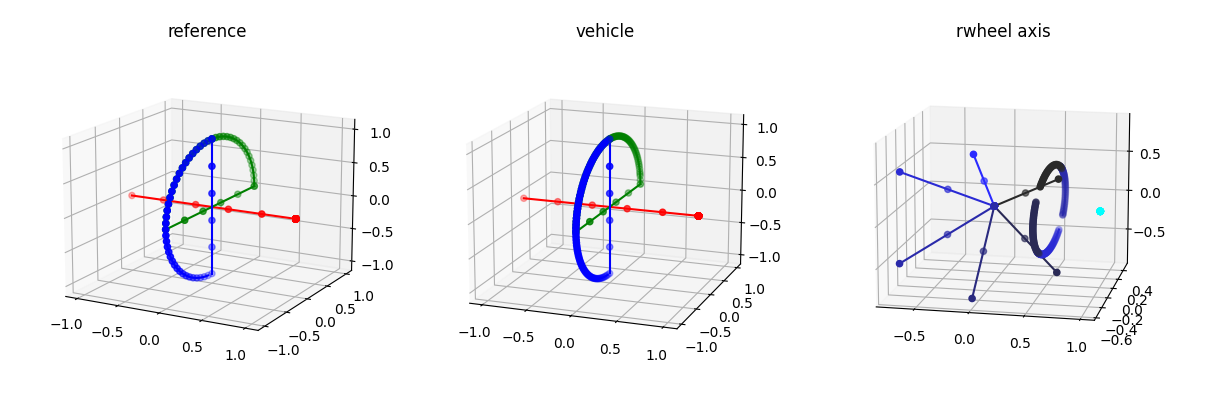
Verified that the rotations are working right in the testbed:
Without gravity, bullets travel in a straight line at constant velocity. To determine where to shoot, imagine shooting an infinite number of bullets simultaneously in all directions, forming an expanding sphere of death. While the sphere is expanding, the target is moving along a straight line (or standing still). If we can determine the instant at which this expanding sphere touches the moving target, we know where to aim: at the target’s position when it gets hit by the expanding sphere of death.
Hooray!
# based on this blog post: https://playtechs.blogspot.com/2007/04/aiming-at-moving-target.html def calc_intersect_time(p:np.array, v:np.array, s:float) -> float: print("calc_intersect_time()") a = s * s - np.sum(np.square(v)) bv = p * v b = np.sum(bv) cv = np.square(p) c = np.sum(cv)
disc = b*b + a*c
t = 0 if disc >= 0: t = (b + np.sqrt(disc)) / a return max(0, t)
While there were no names or phone numbers in the data, we were once again able to connect dozens of devices to their owners, tying anonymous locations back to names, home addresses, social networks and phone numbers of people in attendance. In one instance, three members of a single family were tracked in the data.
Have the code running locally (the NVIDIA update worked too!):
Messaged Jay Alamar on twitter. Working on setting up a video chat
Woohoo!
The IJCAI-21 summary reject phase has now ended and we are pleased to inform you that your submission #1558 "Navigating Human Language Models with Synthetic Agents" will enter the full-paper review phase.
Datasets are not only resources for training accurate, deployable systems, but are also benchmarks for developing new modeling approaches. While large, natural datasets are necessary for training accurate systems, are they necessary for driving modeling innovation? For example, while the popular SQuAD question answering benchmark has driven the development of new modeling approaches, could synthetic or smaller benchmarks have led to similar innovations?
This counterfactual question is impossible to answer, but we can study a necessary condition: the ability for a benchmark to recapitulate findings made on SQuAD. We conduct a retrospective study of 20 SQuAD modeling approaches, investigating how well 32 existing and synthesized benchmarks concur with SQuAD — i.e., do they rank the approaches similarly? We carefully construct small, targeted synthetic benchmarks that do not resemble natural language, yet have high concurrence with SQuAD, demonstrating that naturalness and size are not necessary for reflecting historical modeling improvements on SQuAD. Our results raise the intriguing possibility that small and carefully designed synthetic benchmarks may be useful for driving the development of new modeling approaches.
Book
Finished the Charles Dawson and Alfred Wegoner bits. Working on play
GOES
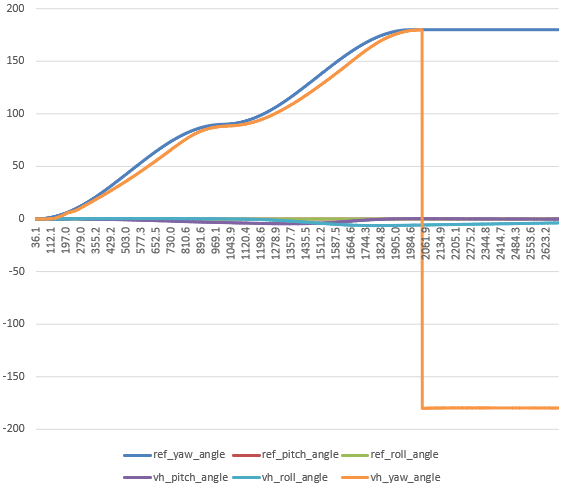
Finally got the sim working again! Now back to getting the scriptreader in






You must be logged in to post a comment.