
This looks interesting: www.oreilly.com/library/view/natural-language-processing/9781098103231/
Book
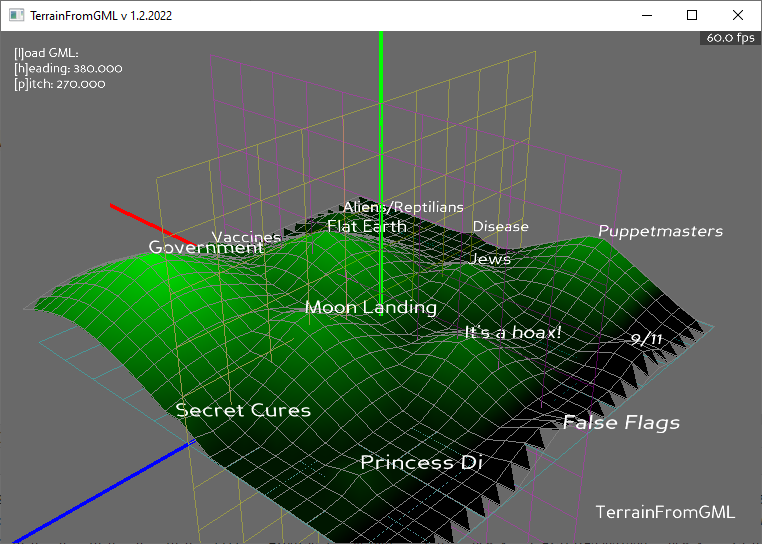
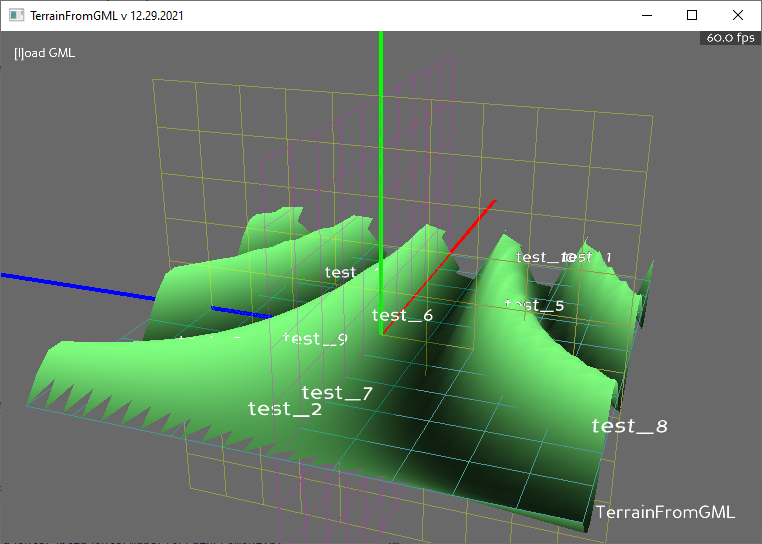
- After a few false starts, I have the terrain extended:

- I still need to:
- add a ‘lit’ and ‘unlit’ node for terrain and labels – done
- add a height scalar – done
- toggle grids and axis – done
- Shift keys to move the lights the other direction, plus lambda functions for the parameters – done
- Maybe add fog? docs.panda3d.org/1.10/python/programming/render-attributes/fog – nope, can’t get the fog to be relative to the terrain center
Today’s progress:

GPT Agents
- Get the number of POSITIVE and NEGATIVE sentiment for each isolated model and compare to ground truth. Make a chart and add to the draft. This is the part that shows that creating models for a population captures that population’s patterns, and that this method is more accurate and reliable than assuming that one general model has all the information needed in an accessible way. Done







You must be logged in to post a comment.