
In a fake battle for Taiwan, U.S. forces lost network access almost immediately.
Curation Bubbles: Domain Versus URL Level Analysis of Partisan News Sharing on Social Media
- Empirical inquiries of political news consumption are typically based on analysis at the level of the news source: a given web domain can be assigned a partisanship score reflective of its relative tendency to be shared by Democrats or Republicans. This practical, tractable approach represents an important methodological advance which has allowed for large-scale empirical studies of how democratic citizens consume political information online. However, despite strong evidence that information sharing is dominated by in-group bias, previous work has also found that most users are exposed to information from a balanced variety of mainstream sources. Such conflicting findings around filter bubbles and echo chambers highlights the need to be able to estimate partisanship at the more fine-grained level of individual stories. It may be that individuals tend to consume politically homogeneous content which originates from a relatively heterogeneous collection of sources. Rather than never sharing stories associated with their political opponents, partisans may selectively share out-group content precisely when that information is favorable to them. Using a panel of 1.6 million Twitter users linked to administrative data, we test this dynamic by examining within-domain sharing patterns by user partisanship over time. Consistent with previous work, we find that, in aggregate, partisans do consume news from a variety of sources. However, we find notable story-level differences suggesting that, despite the heterogeneity of sources, the news curated from partisan’s social networks contains politically homogeneous information. Our findings suggest that domain-level analyses of information sharing gives a false impression of exposure to politically diverse content, and raises new concerns regarding polarization in the consumption and sharing of digital media
- This really fits with my experience, where Fox News viewers share links to the NYTimes that are mentioned on Fox, often without reading them
GPT-Agents
- Add 200k data to rollup spreadsheet
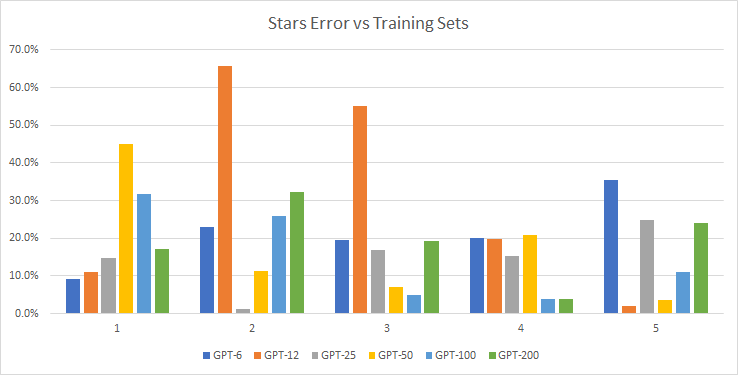
- Here’s the 200k added to the stars counts for each model vs the Yelp 75k ground truth

- It seems to be better at the lower star counts, but worse at 5. To make sure this wasn’t an artifact of the training data, here’s a measure of the error vs the specific data used to create the training corpora:
- 3:30 Meeting
- Have the same size corpora (100k) and the same number of training steps, and prompt with “stars = “.
- Fine-tuning a pretrained model: In this tutorial, we will show you how to fine-tune a pretrained model from the Transformers library. In TensorFlow, models can be directly trained using Keras and the
fitmethod. In PyTorch, there is no generic training loop so the 🤗 Transformers library provides an API with the classTrainerto let you fine-tune or train a model from scratch easily. Then we will show you how to alternatively write the whole training loop in PyTorch.
SBIRs:
- 9:15 Standup
- More proposal?
- Loop back to the simulator and Rukan
- Start working on LAIC tasking splits for IP
