

- The successes of deep learning critically rely on the ability of neural networks to output meaningful predictions on unseen data — generalization. Yet despite its criticality, there remain fundamental open questions on how neural networks generalize. How much do neural networks rely on memorization — seeing highly similar training examples — and how much are they capable of human-intelligence styled reasoning — identifying abstract rules underlying the data? In this paper we introduce a novel benchmark, Pointer Value Retrieval (PVR) tasks, that explore the limits of neural network generalization. While PVR tasks can consist of visual as well as symbolic inputs, each with varying levels of difficulty, they all have a simple underlying rule. One part of the PVR task input acts as a pointer, giving the location of a different part of the input, which forms the value (and output). We demonstrate that this task structure provides a rich testbed for understanding generalization, with our empirical study showing large variations in neural network performance based on dataset size, task complexity and model architecture. The interaction of position, values and the pointer rule also allow the development of nuanced tests of generalization, by introducing distribution shift and increasing functional complexity. These reveal both subtle failures and surprising successes, suggesting many promising directions of exploration on this benchmark.
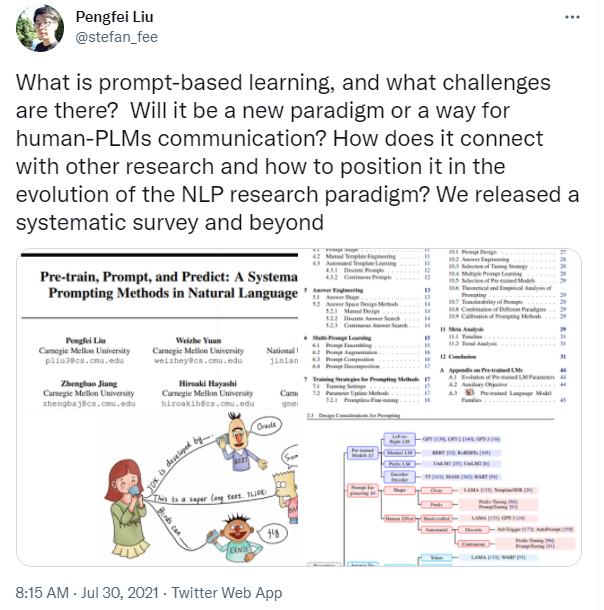
- This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub “prompt-based learning”. Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x’ that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website this http URL including constantly-updated survey, and paperlist.
GPT Agents
- This looks interesting for paragraph clustering: Sentence Transformers in the Hugging Face Hub
- Sentence Transformers is a framework for sentence, paragraph and image embeddings. This allows to derive semantically meaningful embeddings (1) which is useful for applications such as semantic search or multi-lingual zero shot classification. As part of Sentence Transformers v2 release, there are a lot of cool new features:
- Finished the 6k epoch tests yesterday. Maybe finish creating models for 100k today?
SBIR
- Abstract! Done!
- See how Rukan is doing. Tell him about cubes and other shapes – done. Looks good
Book
- Meeting with Michelle at 2:00. Worked on the positioning statement. It’s almost ready to go to an agent!
4:00 NLP Meeting – cancelled
