

Mastodon new users
Developer platforms are all about trust, and Twitter lost it
- Let this be my personal notice to Twitter developers: The team is gone; the investment has been undone. Love does not live here anymore.
Twitter is banning journalists and links to Mastodon instances. I did discover that you can follow a particular instance, which is very nice, but not supported in the API. All you have to do though is create a browser tab for the local timeline for that instance. For example
I need to code up a web page that can do that in a tweetdeck format and handle replies from your particular account. I think that it should be pretty easy. Something for January. Regardless, here’s the basics of accessing any instance timeline:
import json
import requests
# A playground for exploring the Mastodon REST interface (https://docs.joinmastodon.org/client/public/)
# Mastodon API: https://docs.joinmastodon.org/api/
# Mastodon client getting started with the API: https://docs.joinmastodon.org/client/intro/
def create_timeline_url(instance:str = "mastodon.social", limit:int=10):
url = "https://{}/api/v1/timelines/public?limit={}".format(instance, limit)
print("create_timeline_url(): {}".format(url))
return url
def connect_to_endpoint(url) -> json:
response = requests.request("GET", url)
print("Status code = : {}".format(response.status_code))
if response.status_code != 200:
raise Exception(
"Request returned an error: {} {}".format(
response.status_code, response.text
)
)
return response.json()
def print_response(title:str, j:json):
json_str = json.dumps(j, indent=4, sort_keys=True)
print("\n------------ Begin '{}':\nresponse:\n{}\n------------ End '{}'\n".format(title, json_str, title))
def main():
print("post_lookup")
instance_list = ["fediscience.org", "sigmoid.social"]
for instance in instance_list:
url = create_timeline_url(instance, 1)
rsp = connect_to_endpoint(url)
print_response("{} test:".format(instance), rsp)
if __name__ == "__main__":
main()
Book
- Finish copyright spreadsheet?
SBIRs
- Scan more of War Elephants – done
- Add history.tex and put the applicable quotes and thoughts
- Finish the first pass at interfaces – done
- Meeting with Ron? Two, in fact
GPT Agents
- Partial pull on item 19. Need to retry later. The API crashed, apparently but came back up. Need to add some exception handling for that next time
- Update proposal with latest numbers. Also reference Amir Shevat’s tech crunch article about his expectation that the API will fail

Bookend for the day




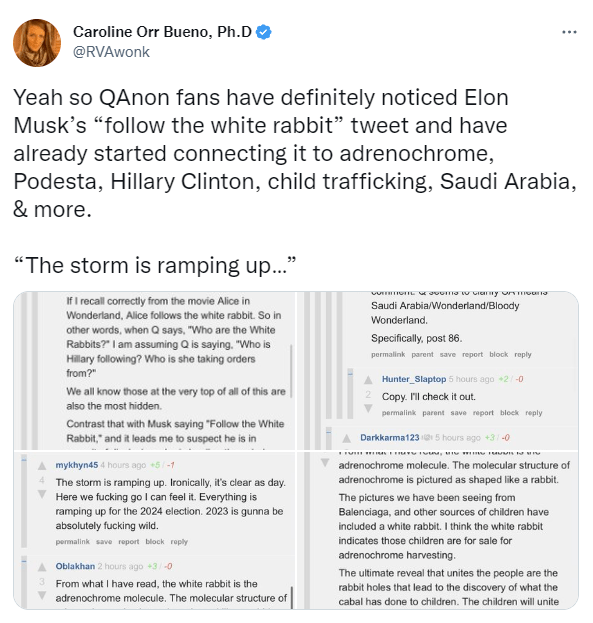
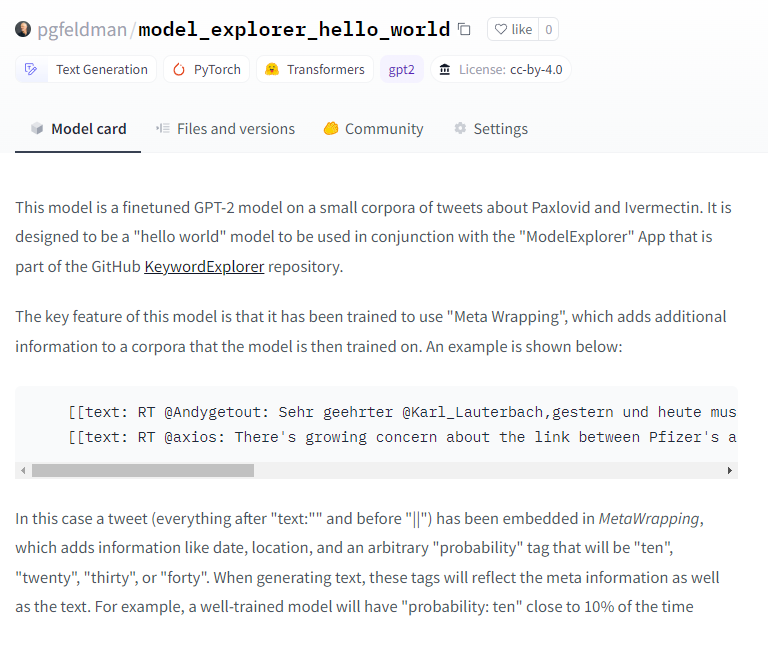

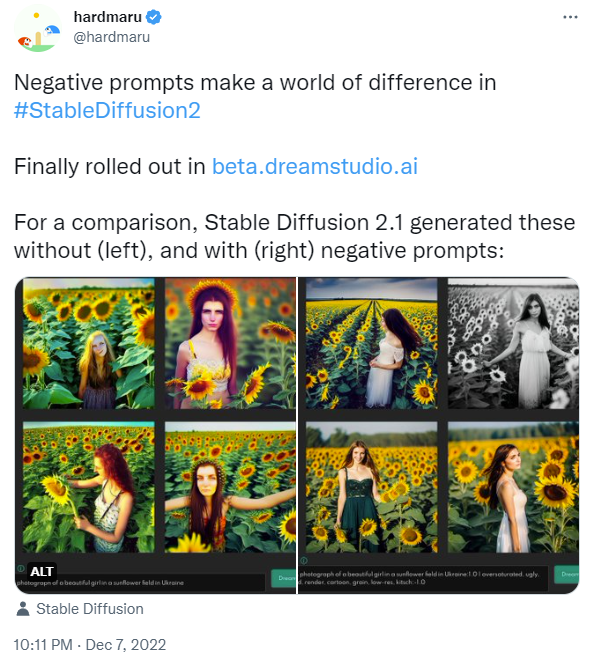

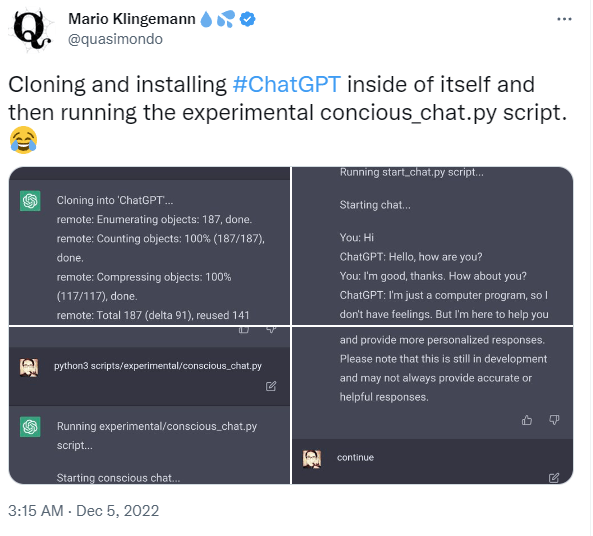
 It seems so!
It seems so! Nope. So just equations. Still, that’s nice
Nope. So just equations. Still, that’s nice




You must be logged in to post a comment.