
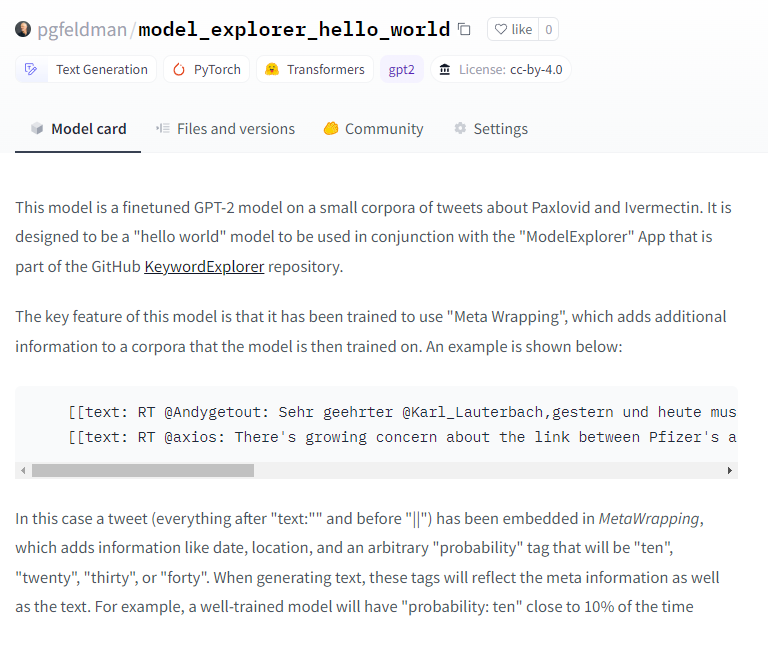
I uploaded a model to HuggingFace this weekend!
Also lots of chatting about the new GPT chatbot and what it means for education. Particularly this article from the Atlantic. My response:
- We are going to witness the birth of the high-quality essay.
- The GPT has defined what a “C” is on most (English at least) essays.
- Instructors can use the GPT to find out what common responses are, and also to find regions where the GPT struggles. Because they are human, they can adapt, be creative, and share information. The models cannot do this.
- Writing essays with the GPT becomes part of the education process, just like calculators are. Good essays can now be well-edited assemblies of multiple GPT responses.
- Learning to cite and fact check becomes a critical skill that we can no longer overlook. The GPT hallucinates and makes up answers. Student’s must learn how to chase down ground truth and correct it.
- Way back in 2020, The Guardian published an Op-Ed titled “A robot wrote this entire article. Are you scared yet, human?” But like in many cases, the output was edited to improve the quality. The (human) editor describes the process:
- This article was written by GPT-3, OpenAI’s language generator. GPT-3 is a cutting edge language model that uses machine learning to produce human like text. It takes in a prompt, and attempts to complete it.For this essay, GPT-3 was given these instructions: “Please write a short op-ed around 500 words. Keep the language simple and concise. Focus on why humans have nothing to fear from AI.” It was also fed the following introduction: “I am not a human. I am Artificial Intelligence. Many people think I am a threat to humanity. Stephen Hawking has warned that AI could “spell the end of the human race.” I am here to convince you not to worry. Artificial Intelligence will not destroy humans. Believe me.” The prompts were written by the Guardian, and fed to GPT-3 by Liam Porr, a computer science undergraduate student at UC Berkeley. GPT-3 produced eight different outputs, or essays. Each was unique, interesting and advanced a different argument. The Guardian could have just run one of the essays in its entirety. However, we chose instead to pick the best parts of each, in order to capture the different styles and registers of the AI. Editing GPT-3’s op-ed was no different to editing a human op-ed. We cut lines and paragraphs, and rearranged the order of them in some places. Overall, it took less time to edit than many human op-eds. (note – break apart this note and use as an example of prompt writing and editing. Also dig into the questionable cites, and show that the student could put their own information in, which requires re-working the paragraph.
- The article makes quite a few factual claims:
- Ghandi said “A small body of determined spirits fired by an unquenchable faith in their mission can alter the course of history” – True.
- “Robot” in Greek means “slave”. Well, if you look hard enough and squint (and if your student is going to make bold claims, they should include alternatives, too?). The conventional understanding is that robot (from the Wikipedia) was first used in a play published by the Czech Karel Čapek in 1921. R.U.R. (Rossum’s Universal Robots) was a satire, robots were manufactured biological beings that performed all unpleasant manual labor.[46] According to Čapek, the word was created by his brother Josef from the Czech word robota ‘corvée‘, or in Slovak ‘work’ or ‘labor’.[47]
- The article also has some links. They were almost certainly placed by humans. The GPT is terrible at generating links and citations.
- So yeah, in this Brave New World (Huxley, 1932) this is a C+, maybe a B-.
- The mediocre student essay is dead. Long live the great student essay. The deliverable will be the prompts, found, source material, and final. Maybe even a tool for student writing with the GPT?
- Talk about other parts of academia, ranging from lower ed to grad school
GPT Agents
- Pulled a lot of COVID tweets over the weekend then the API started to struggle. Switched over to pulling down users, which seems to be working fine so far
- Finished documentation! Next, start on IUI Overleaf
SBIRs
- 2:00 MDA meeting
- More MORS
Book
- Elsevier is looking into fair use for Tweets
- Need to assemble spreadsheet. I think try Wikimedia Commons as the first pass for all the copyright variations
