
7:00 – 8:00, 4:00 – 5:00 Research
- Redid the paper in the ACM format. I have to say, LaTex did make that pretty easy…
- Got the gridded population data. Now I have to find a Python reader for arcGIS .asc files. This looks like it might work (ASCII to Raster)
- Chat with Helena
- Now in CSCW
- “In the field of CSCW there are emergent trends”. Starbird & etc. Check mail
- Abstract due on Thursday!
8:30 – 3:30 BRC
- Discussion with Aaron about spatial organization and dimension reduction.
- Went looking for reasons about the ordering of ICD10 codes and got here: List ICD-10 codes in correct order to preserve medical necessity
- Found this: ICD-10-CM Official Guidelines for Coding and Reporting
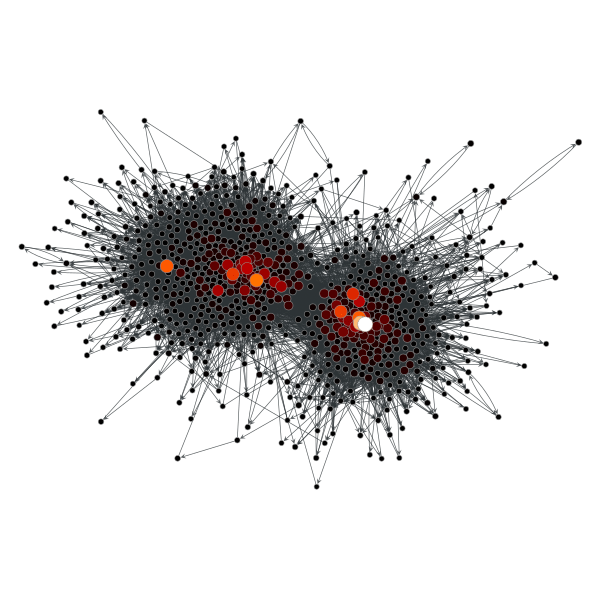
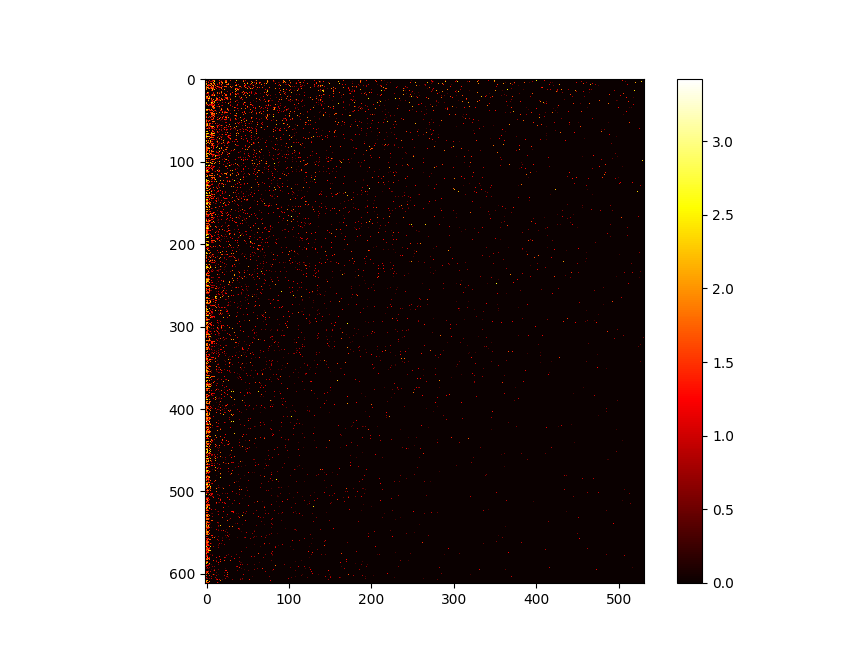
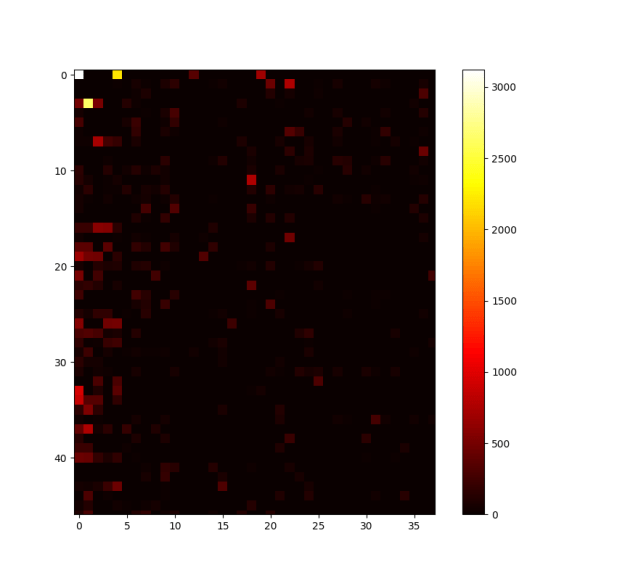
- Working on cluster similarity
- Built a dictionary of all clusters in a sample. Need to compare them next







You must be logged in to post a comment.