Went grocery shopping yesterday. I go a little less than once every two weeks, and every time I go, the world has changed. Now, everyone wears masks. We wait in a spread-out line to enter the store. I bring everything home and stage it in the basement before cleaning it and bringing it to the kitchen. And yet it’s also spring, and the world is sunny and smells of growing things. I wake up to birds chirping in the morning, and opened the windows a couple of times this week.
D20
- Trying to get ahold of Zach. Finally connected in the late afternoon and made some tweaks. Leaflet might be a good map API
GOES
- I think today’s goal is to build a little python app that I can run from the command line that loads samples in real time into the InfluxDB. Square waves (SqW), sin waves (SiW), and noisy sin waves (NoW). Then I want to build one network that produces NoW from SqW, and another that tries to detect the difference between an actual NsW and a synthesized one.
- Working!
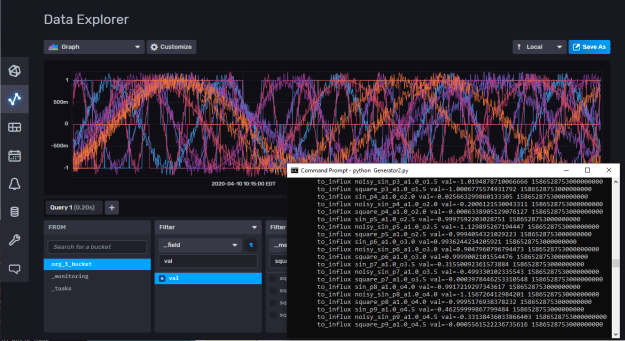
- Queries are returning as well. Here’s the last ten seconds from sin_p1_a1.0_o0.5:
FluxTable() columns: 8, records: 8
{'result': '_result', 'table': 0, '_start': datetime.datetime(2020, 4, 10, 14, 34, 53, 868766, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2020, 4, 10, 14, 35, 3, 868766, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2020, 4, 10, 14, 34, 54, tzinfo=datetime.timezone.utc), '_value': 0.9690184703994814, '_field': 'val', '_measurement': 'sin_p1_a1.0_o0.5'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2020, 4, 10, 14, 34, 53, 868766, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2020, 4, 10, 14, 35, 3, 868766, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2020, 4, 10, 14, 34, 55, tzinfo=datetime.timezone.utc), '_value': 0.9395197317147641, '_field': 'val', '_measurement': 'sin_p1_a1.0_o0.5'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2020, 4, 10, 14, 34, 53, 868766, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2020, 4, 10, 14, 35, 3, 868766, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2020, 4, 10, 14, 34, 56, tzinfo=datetime.timezone.utc), '_value': 0.9006336224346869, '_field': 'val', '_measurement': 'sin_p1_a1.0_o0.5'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2020, 4, 10, 14, 34, 53, 868766, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2020, 4, 10, 14, 35, 3, 868766, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2020, 4, 10, 14, 34, 57, tzinfo=datetime.timezone.utc), '_value': 0.8527486797091374, '_field': 'val', '_measurement': 'sin_p1_a1.0_o0.5'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2020, 4, 10, 14, 34, 53, 868766, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2020, 4, 10, 14, 35, 3, 868766, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2020, 4, 10, 14, 34, 58, tzinfo=datetime.timezone.utc), '_value': 0.7963433540571716, '_field': 'val', '_measurement': 'sin_p1_a1.0_o0.5'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2020, 4, 10, 14, 34, 53, 868766, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2020, 4, 10, 14, 35, 3, 868766, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2020, 4, 10, 14, 34, 59, tzinfo=datetime.timezone.utc), '_value': 0.7319812288475823, '_field': 'val', '_measurement': 'sin_p1_a1.0_o0.5'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2020, 4, 10, 14, 34, 53, 868766, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2020, 4, 10, 14, 35, 3, 868766, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2020, 4, 10, 14, 35, tzinfo=datetime.timezone.utc), '_value': 0.6603053891601736, '_field': 'val', '_measurement': 'sin_p1_a1.0_o0.5'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2020, 4, 10, 14, 34, 53, 868766, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2020, 4, 10, 14, 35, 3, 868766, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2020, 4, 10, 14, 35, 1, tzinfo=datetime.timezone.utc), '_value': 0.5820319962922194, '_field': 'val', '_measurement': 'sin_p1_a1.0_o0.5'}
-
- Now I need to extract the useful info for ML processing. That was easy:
for table in tables:
print(table)
rd:Dict
for record in table.records:
rd = record.values
print("time = {}, name = {}, value = {}".format(rd["_time"], rd["_measurement"], rd["_value"]))
- Hmmm. I can do a specific query:
tables = query_api.query('from(bucket:"{}") |> range(start: -10s) |> filter(fn:(r) => r._measurement == "sin_p1_a1.0_o0.5")'.format(bucket))
but using wildcards like * chokes
tables = query_api.query('from(bucket:"{}") |> range(start: -10s) |> filter(fn:(r) => r._measurement == "sin_*")'.format(bucket))
- Time to RTFM.
- The syntax is specified using Extended Backus-Naur Form (“EBNF”). EBNF is the same notation used in the Go programming language specification, which can be found here. Not so coincidentally, InfluxDB is written in Go.
- I wonder if these folks are ex-Googlers?
- Wrong manual – the link above is for version 1.7. The query reference for 2.0 is here.
- Basically, it’s a very simple query language, which is why you need all the tags. So here’s how it works.
- First, create well-tagged data:
def write_point(self, name:str, val:float, tags: Dict = {}):
p = Point(name).field(self.keyfield, val).time(self.current_time)
for key, val in tags.items():
p.tag(key, val)
self.write_api.write(bucket=self.bucket_name, record=p)
print("\tto_influx {}".format(p.to_line_protocol()))
def sin_wave(self, t:float, period:float = 1.0, amplitude:float = 1.0, offset:float = 0,name:str = None):
tags = {"type": "sin", "period":period, "amplitude": amplitude, "offset":offset}
if name == None:
name = "sin_p{}_a{}_o{}".format(period, amplitude, offset)
val = math.sin(t/period + offset)*amplitude
self.write_point(name, val, tags)
Here we have two methods, one that creates a value for a point of a sin wave, and one that writes the point. In this case, all the tags are stored as a Dict and passed as an argument to write_point, which is used by all the various functions. The output looks like this:
to_influx noisy_sin_p7_a1.0_o3.5,amplitude=1.0,offset=3.5,period=7,type=noisy_sin val=0.13146298019922603 1586545970000000000
to_influx square_p7_a1.0_o3.5,amplitude=1.0,offset=3.5,period=7,type=square val=0.0006153287497587468 1586545970000000000
to_influx sin_p8_a1.0_o4.0,amplitude=1.0,offset=4.0,period=8,type=sin val=0.8523503891730094 1586545970000000000
to_influx noisy_sin_p8_a1.0_o4.0,amplitude=1.0,offset=4.0,period=8,type=noisy_sin val=0.717585870814358 1586545970000000000
- To query this, we do the following:
query_api = self.client.query_api()
# Queries have these basic components, connected by the forward operator (|>) which applies each step in sequence:
# source 'from (bucket: "my-bucket")
# range (relative): range(start: -1h, stop: -10m). The stop is optional. If left out, all results up to the present will be returned
# range (absolute): range(start: 2018-11-05T23:30:00Z, stop: 2018-11-06T00:00:00Z)
# filter : an anonymous function that compares string values with >, <, and == comparitors. There are no wildcards. This is why tagging is important tables =
Just remember that all tags are regarded as strings (as you can see in the filter_func string below), so be careful in generating them if they represent floating point values!
filter_func = 'r.type == "sin" and r.period == "4"'
tables = query_api.query('from(bucket:"{}") |> range(start: -10s) |> filter(fn:(r) => {})'.format(bucket, filter_func))
- This query gives the following result:
FluxTable() columns: 12, records: 7
type = sin period = 4, time = 2020-04-10 19:16:44+00:00, name = sin_p4_a1.0_o2.0, value = -0.7178200203799832
type = sin period = 4, time = 2020-04-10 19:16:45+00:00, name = sin_p4_a1.0_o2.0, value = -0.7349996180484573
type = sin period = 4, time = 2020-04-10 19:16:46+00:00, name = sin_p4_a1.0_o2.0, value = -0.7517198648809216
type = sin period = 4, time = 2020-04-10 19:16:47+00:00, name = sin_p4_a1.0_o2.0, value = -0.7679703112673733
type = sin period = 4, time = 2020-04-10 19:16:48+00:00, name = sin_p4_a1.0_o2.0, value = -0.7837408012077955
type = sin period = 4, time = 2020-04-10 19:16:49+00:00, name = sin_p4_a1.0_o2.0, value = -0.7990214786593275
type = sin period = 4, time = 2020-04-10 19:16:50+00:00, name = sin_p4_a1.0_o2.0, value = -0.8138027936959693
- And that’s enough for the day/week, I think



























You must be logged in to post a comment.