
Fridays are hard. I feel like I need a break from pushing this rock up hill alone. Nice day for a ride tomorrow, so a few of us will probably meet up.
D20
- Zach seems to be making progress in fits and starts. No word from Aaron
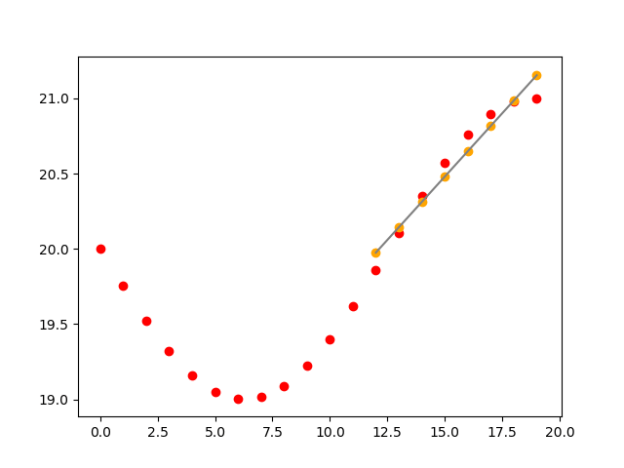
- One way to make the system more responsive is to see if the rates are above or below the regression. Above can be flagged.
GPT-2 Agents
- More PGNtoEnglish. Getting close I think.
- Added pawn attack moves (diagonals)
- Adding comment regex – done
- Some problem handling this:
Evaluating move [Re1 Qb6] search at (-6, -6) for black queen out of bounds search at (6, -6) for black queen out of bounds search at (0, -6) for black queen out of bounds search at (7, 7) for black queen out of bounds search at (-7, -7) for black queen out of bounds search at (7, -7) for black queen out of bounds search at (7, 0) for black queen out of bounds search at (0, -7) for black queen out of bounds raw: white: Re1, black: Qb6 expanded: white: Fred Van der Vliet moves white rook from f1 to e1. black: unset
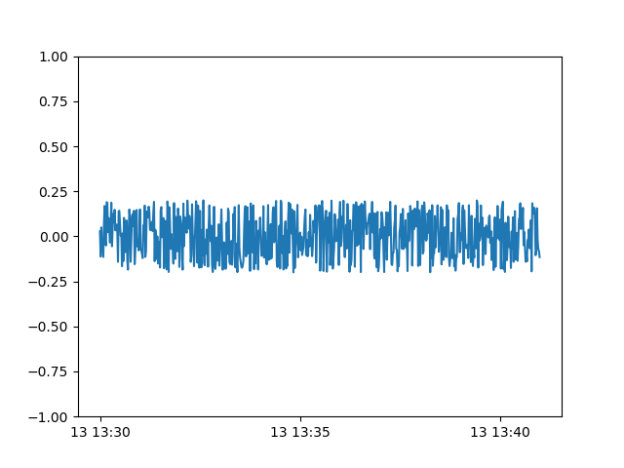
GOES
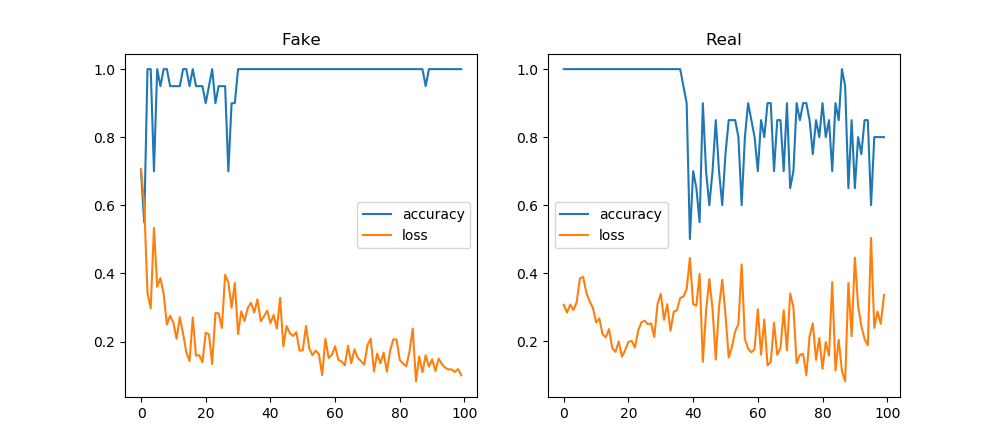
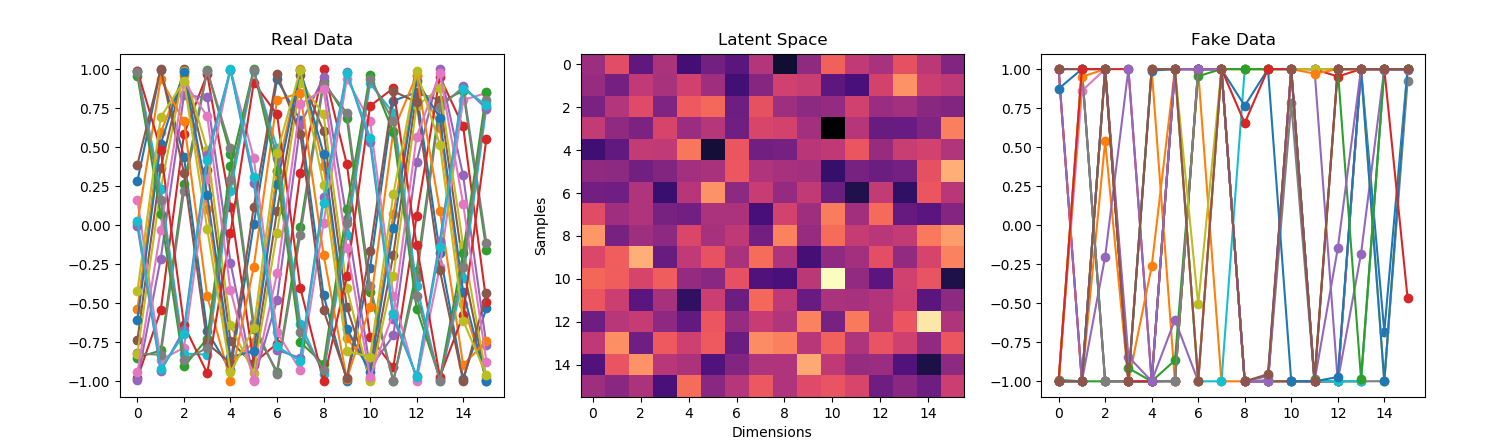
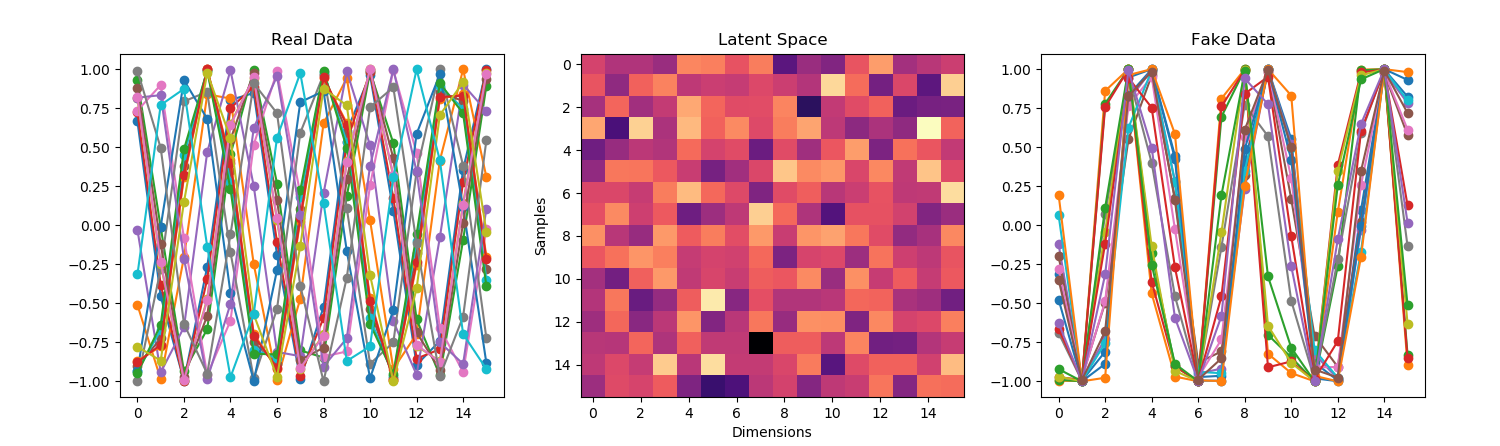
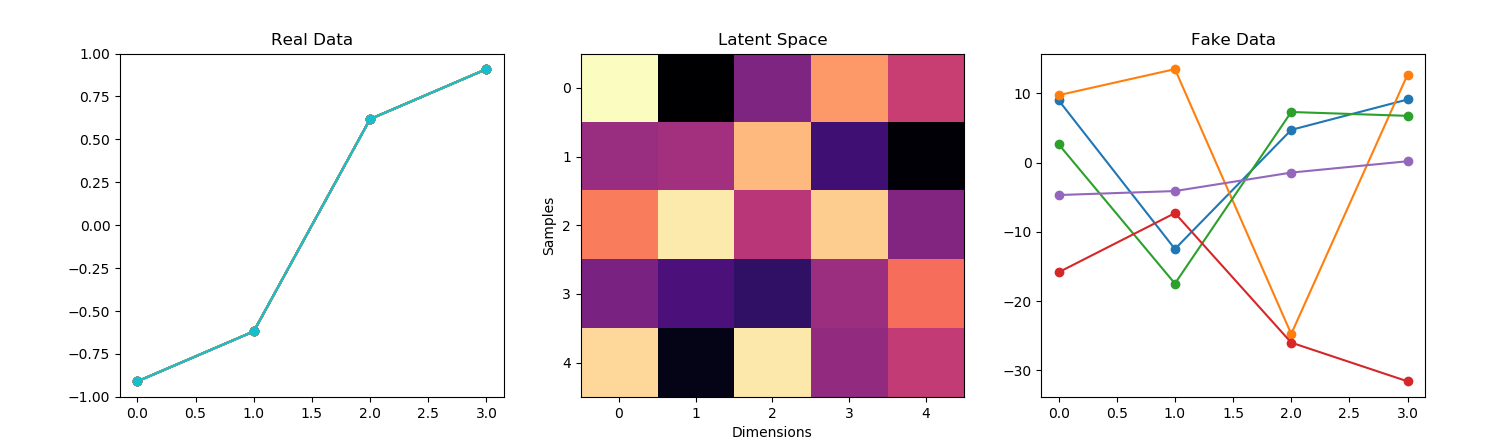
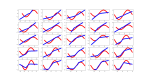
- Need to make the output of the generator work as input to the discriminator.
- So I need to get to the input vector of latent noise to an output that is the size of the real data. It’s easy to do with Dense, but Dense and Conv1D don’t get along. I think I can get around that by reshaping the dense layer to something that a Conv1D can take. But that probably looses a lot of information, since each neuron will have some of each noise sample in it. But the information is noise in the first place, so it’s just resampled noise? The other option is to upsample, but that requires the latent vector to divide evenly into the input vector for the discriminator.
- Here’s my code that does the change from a dense to Conv1D:
self.g_model.add(Dense(self.vector_size*self.num_samples, activation='relu', batch_input_shape=(self.latent_dim, self.num_samples))) self.g_model.add(Reshape(target_shape=(self.vector_size, self.num_samples))) self.g_model.add(Conv1D(filters=self.vector_size, kernel_size=5, activation='tanh', batch_input_shape=(self.vector_size, self.num_samples, 1)))
- The code that produces the latent noise is:
def generate_latent_points(self, span:float=1.0) -> np.array:
x_input = np.random.randn(self.latent_dim * self.num_samples)*self.span
# reshape into a batch of inputs for the network
x_input = x_input.reshape(self.latent_dim, self.num_samples)
return x_input
- The “real” values are:
real_matrix = [[-0.34737792 -0.7081109 0.93673414 -0.071527 -0.87720268] [ 0.99876073 -0.46088645 -0.61516785 0.97288676 -0.19455964] [ 0.97121222 -0.18755778 -0.81510907 0.8659679 0.09436946] [-0.72593361 -0.32328777 0.99500398 -0.50484775 -0.57482239] [ 0.72944027 -0.92555418 0.04089262 0.89151951 -0.78289867] [ 0.79514567 -0.88231211 -0.06080288 0.93291797 -0.71565884] [ 0.78083404 -0.89301473 -0.03758353 0.92429527 -0.73170157] [ 0.08266474 -0.94058595 0.70017899 0.3578314 -0.9979998 ] [-0.39534886 -0.67069473 0.95356385 -0.12295042 -0.85123299] [ 0.73424796 0.31175013 -0.99371562 0.5153131 0.56482379]]
- The latent values are (note that the matrix is transposed):
latent_matrix = [[ 8.73701754 6.10841293 9.31566343 -2.00751851 0.10715919 6.94580853 -6.95308374 6.97502697 -11.09777023 -8.79311041] [ -3.61789323 0.11091496 10.94717459 3.14579647 -13.23974342 2.78914476 9.40101397 -17.75756896 2.87461527 6.65877192] [ 5.77331701 7.71326491 9.9877786 -3.81972802 -5.86490109 -6.68585542 -13.59478633 -7.66952834 -10.78863284 5.9248856 ] [ -3.05226511 -5.36347909 1.3377953 14.87752343 -0.21993387 -13.47737126 1.39357385 -1.85004465 6.83400948 1.21105276]] - The values created by the generator are:
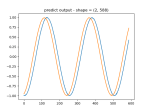
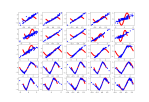
predict_matrix = [[[-0.9839389 0.18747564 -0.9449842 -0.66334486 -0.9822154 ]] [[ 0.9514655 -0.9985579 0.76473945 -0.9985249 -0.9828463 ]] [[-0.58794653 -0.9982161 0.9855345 -0.93976855 -0.9999758 ]] [[-0.9987122 0.9480774 -0.80395573 -0.999845 0.06755089]]]
- So now I need to get the number of rows up to the same value as the real data
- Ok, so here’s how that works. We use tf.Keras.Reshape(), which is pretty simple. You simply put the most of shape you want as the single argument and it. So for these experiments, I had ten rows of 5 features, plus an extra dimension. So you would think that reshape(10,5,1) would be what you want.
- Au contraire! Keras wants to be able to have flexibility, so one dimension is left to vary. The argument is actually (5, 1). Here are two versions. First is a generator using a Dense network:
def define_generator_Dense(self) -> Sequential: self.g_model_Dense = Sequential() self.g_model_Dense.add(Dense(4, activation='relu', kernel_initializer='he_uniform', input_dim=self.latent_dim)) self.g_model_Dense.add(Dropout(0.2)) self.g_model_Dense.add(Dense(self.vector_size, activation='tanh')) # activation was linear self.g_model_Dense.add(Reshape((self.vector_size, 1))) print("g_model_Dense.output_shape = {}".format(self.g_model_Dense.output_shape)) # compile model loss_func = tf.keras.losses.BinaryCrossentropy() opt_func = tf.keras.optimizers.Adam(0.001) self.g_model_Dense.compile(loss=loss_func, optimizer=opt_func) return self.g_model_Dense - Second is a network using Conv1D layers
def define_generator_Dense_to_CNN(self) -> Sequential: self.g_model_Dense_CNN = Sequential() self.g_model_Dense_CNN.add(Dense(self.num_samples * self.vector_size, activation='relu', batch_input_shape=(self.num_samples, self.latent_dim))) self.g_model_Dense_CNN.add(Reshape(target_shape=(self.num_samples, self.vector_size))) self.g_model_Dense_CNN.add(Conv1D(filters=self.vector_size, kernel_size=self.num_samples, activation='tanh', batch_input_shape=(self.num_samples, self.vector_size, 1))) # activation was linear self.g_model_Dense_CNN.add(Reshape((self.vector_size, 1))) #self.g_model.add(UpSampling1D(size=2)) # compile model loss_func = tf.keras.losses.BinaryCrossentropy() opt_func = tf.keras.optimizers.Adam(0.001) self.g_model_Dense_CNN.compile(loss=loss_func, optimizer=opt_func) return self.g_model_Dense_CNN:
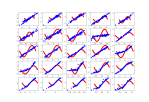
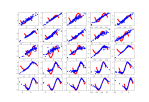
- Both evaluated correctly against the discriminator, so I should be able to train the whole GAN, once it’s assembled. But that is not something to start at 4:30 on a Friday afternoon!
real predict = (10, 1)[[0.42996567] [0.55048925] [0.56003207] [0.40951794] [0.5600004 ] [0.5098837 ] [0.4046895 ] [0.41493616] [0.4196912 ] [0.5080263 ]] gdense_mat predict = (10, 1)[[0.48928624] [0.5 ] [0.4949373 ] [0.5 ] [0.5973854 ] [0.61968124] [0.49698165] [0.5 ] [0.5183723 ] [0.4212265 ]] gdcnn_mat predict = (10, 1)[[0.48057705] [0.5026125 ] [0.51943815] [0.4902147 ] [0.5988 ] [0.39476413] [0.49915075] [0.49861506] [0.55501187] [0.54503495]]






































You must be logged in to post a comment.