
7:00 – ASRC MKT
- Data & Society to Launch Disinformation Action Lab Supported by Knight Foundation
- The lab will use research to explore issues such as: how fake news narratives propagate; how to detect coordinated social media campaigns; and how to limit adversaries who are deliberately spreading misinformation. To understand where online manipulation is headed, it will analyze the technology and tactics being used by players at the international and domestic level.This project builds off the ongoing work of the Media Manipulation initiative at Data & Society, which examines how groups use social media and the participatory culture of the internet to spread and amplify misinformation and disinformation. Recent releases from this initiative include Lexicon of Lies and Media Manipulation and Disinformation Online.The funding is part of today’s announcement that the John S. and James L. Knight Foundation is giving $4.5 million in new funding to eight leading organizations working to create more informed and engaged communities through innovative use of technology. The other organizations receiving support include: Code2040, Code for Science & Society, Columbia Journalism School, DocumentCloud, Emblematic Group, HistoryPin and mRelief.
- Before I restart on The Group Polarization Phenomenon, I’m going to take a look at how much work it would be to add the recording of trajectories through cells by agent.
- And updates
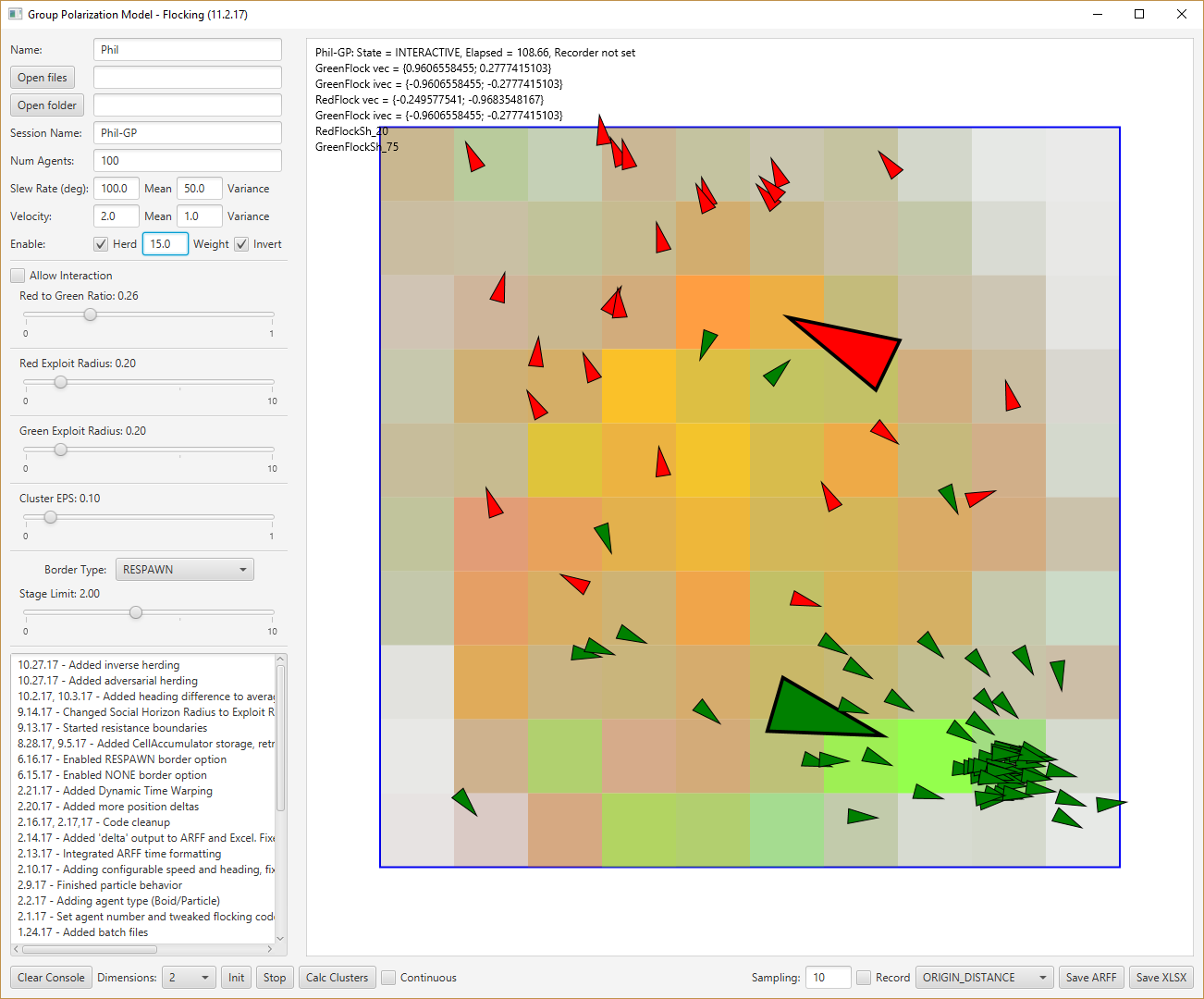
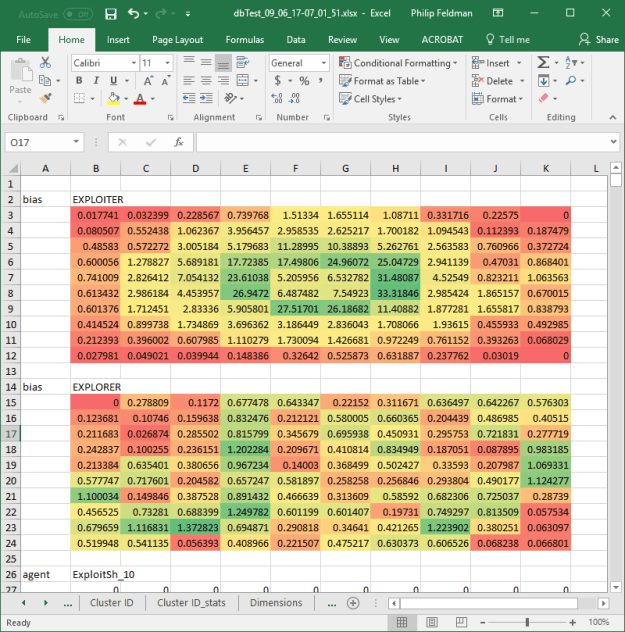
- Done! The name incorporates the n-dimensional cell position. In this case it’s 2D
GreenFlockSh_10: GreenFlock[6, 3], RedFlock[6, 4], GreenFlock[7, 4], GreenFlock[7, 4], GreenFlock[7, 4], RedFlock[8, 4], GreenFlock[8, 5], GreenFlock[8, 5], GreenFlock[8, 5], RedFlock[8, 6], RedFlock[8, 6], RedFlock[8, 6], RedFlock[8, 6], GreenFlock[8, 7], GreenFlock[8, 7], RedFlock[7, 7], RedFlock[7, 7], GreenFlock[7, 8], GreenFlock[7, 8], RedFlock[6, 8], RedFlock[6, 8], RedFlock[6, 8], GreenFlock[5, 8], GreenFlock[5, 8], GreenFlock[5, 8], RedFlock[4, 8], RedFlock[4, 8], RedFlock[4, 8], RedFlock[4, 8], RedFlock[3, 7], RedFlock[3, 7], RedFlock[3, 7], RedFlock[3, 7], GreenFlock[3, 6], GreenFlock[3, 6], GreenFlock[3, 6], RedFlock[3, 5], RedFlock[3, 5], GreenFlock[2, 5], GreenFlock[2, 5], RedFlock[2, 4], RedFlock[2, 4], RedFlock[2, 4], GreenFlock[2, 3], GreenFlock[2, 3], GreenFlock[2, 3], GreenFlock[3, 2], GreenFlock[3, 2], GreenFlock[3, 2], GreenFlock[3, 2], GreenFlock[3, 2], RedFlock[4, 2], GreenFlock[4, 1], GreenFlock[4, 1], RedFlock[5, 1], GreenFlock[5, 2], GreenFlock[5, 2], RedFlock[6, 2], RedFlock[6, 2], RedFlock[6, 2], GreenFlock[6, 3], GreenFlock[6, 3], GreenFlock[6, 3], RedFlock[7, 3], GreenFlock[7, 4], GreenFlock[7, 4], GreenFlock[7, 4], RedFlock[7, 5], RedFlock[7, 5], RedFlock[7, 5], GreenFlock[8, 5], RedFlock[8, 6], RedFlock[8, 6], RedFlock[8, 6], GreenFlock[8, 7], GreenFlock[8, 7], GreenFlock[8, 7], GreenFlock[8, 7], GreenFlock[9, 8], GreenFlock[9, 8], GreenFlock[9, 8], RedFlock[9, 9], RedFlock[9, 9], RedFlock[9, 9], RedFlock[9, 9], RedFlock[9, 9], RedFlock[9, 9], RedFlock[9, 9], GreenFlock[9, 8], GreenFlock[9, 8], GreenFlock[9, 8], GreenFlock[9, 8], GreenFlock[8, 7], GreenFlock[8, 7], GreenFlock[8, 7], GreenFlock[8, 7], RedFlock[7, 7], RedFlock[7, 7], RedFlock[7, 7]
- Some additional thoughts about building maps from trajectories
- Incorporating trajectories allows determination of otherwise difficult problems. An example of this is pictures of war crimes. If the trajectory originates in a legal belief space, then it’s evidence to be saved. If it comes from an extremist belief space, it’s propaganda to be deleted.
- The simplest way to do this is to look at all the trajectories where a landmark is shared. Every item that is adjacent to that landmark on a trajectory must be adjacent in the environment. If we build a graph with the lowest crossing number, we should have our best reconstruction.
- Time can be an important dimension, and may provide useful information where just sequence may not
- It is possible, even likely, that the map is not fixed, so the environment should also be allowed to morph over time to support optimal relations. Think of it as agents surfing on a wave. There is an outer frame (the shore) that waves and surfers can’t exist. Within that frame, waves move and follow different rules from surfers. Surfers in turn are influenced by the waves, and in our case, waves may be influenced by the surfers as well as the external environment.
- Trajectories point both ways. In addition to being able to infer a destination for an agent, it may be possible to infer an origin.
- Discussing this with Aaron, we realized that it might be possible to build a map by constructing a network from the adjacency of paths. In other words, if one path goes from C1->C2->C3 and another goes from B2->C2->D2, then we know that C2 is adjacent to all those points. That information can be used to build a graph. If the graph can be arranged so that it has a low crossing number, then it should approximate the original map. The (relative) size of the areas could be related to the crossing times averaged out for all agents.
- And I just found this in Reinforcement Learning : An Introduction (1st edition linked here):

- Back to Angular
- Found where the typescript files live on the browser/webpack:
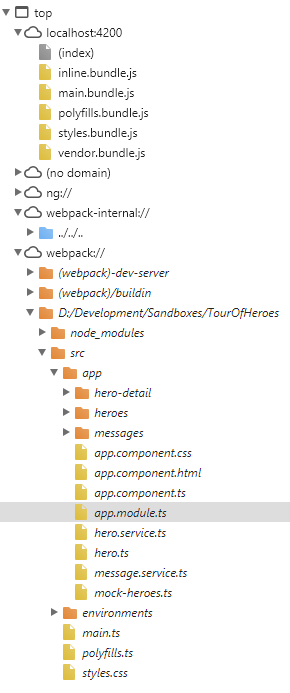
- Got routes working, with minimal confusion. The framework generates a lot of code though…
- To get npm install angular–in–memory–web–api —save to install something visible for the IDE, I had to add the -g option. Still got weird errors though:
D:\Development\Sandboxes\TourOfHeroes>npm install angular-in-memory-web-api --save -g npm WARN angular-in-memory-web-api@0.5.1 requires a peer of @angular/common@>=2.0.0 <6.0.0 but none is installed. You must install peer dependencies yourself. npm WARN angular-in-memory-web-api@0.5.1 requires a peer of @angular/core@>=2.0.0 <6.0.0 but none is installed. You must install peer dependencies yourself. npm WARN angular-in-memory-web-api@0.5.1 requires a peer of @angular/http@>=2.0.0 <6.0.0 but none is installed. You must install peer dependencies yourself. npm WARN angular-in-memory-web-api@0.5.1 requires a peer of rxjs@^5.1.0 but none is installed. You must install peer dependencies yourself.
- Here’s how you generate a service
ng generate service in-memory-data --flat --module=app
- Found where the typescript files live on the browser/webpack:










You must be logged in to post a comment.