9:15 status meeting. It looks like I’ll be working on the phase 2 proposal for the rest of the week?
8:45 pre-standup with Rukan to see how things are going
Looks like we are going to improve our experiment pipeline since we seem to be loosing data. Rukan is looking into what it takes to get MySql installed on his instance
Working to identify bias in the data and mitigate bias in the system
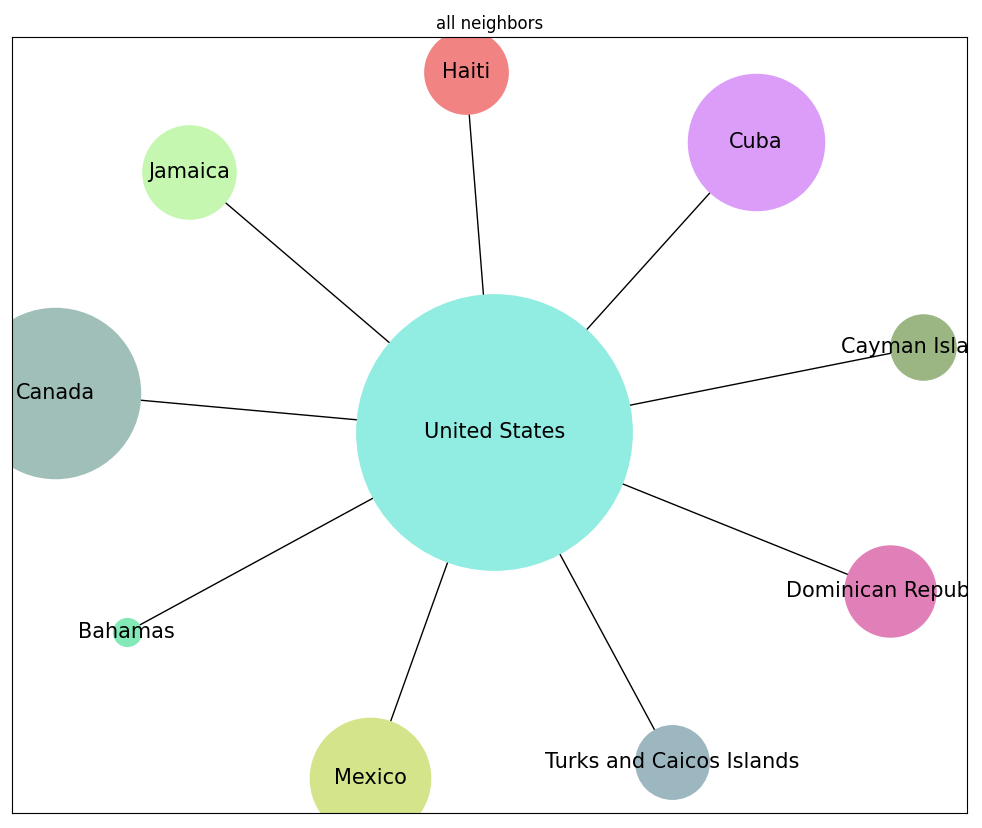
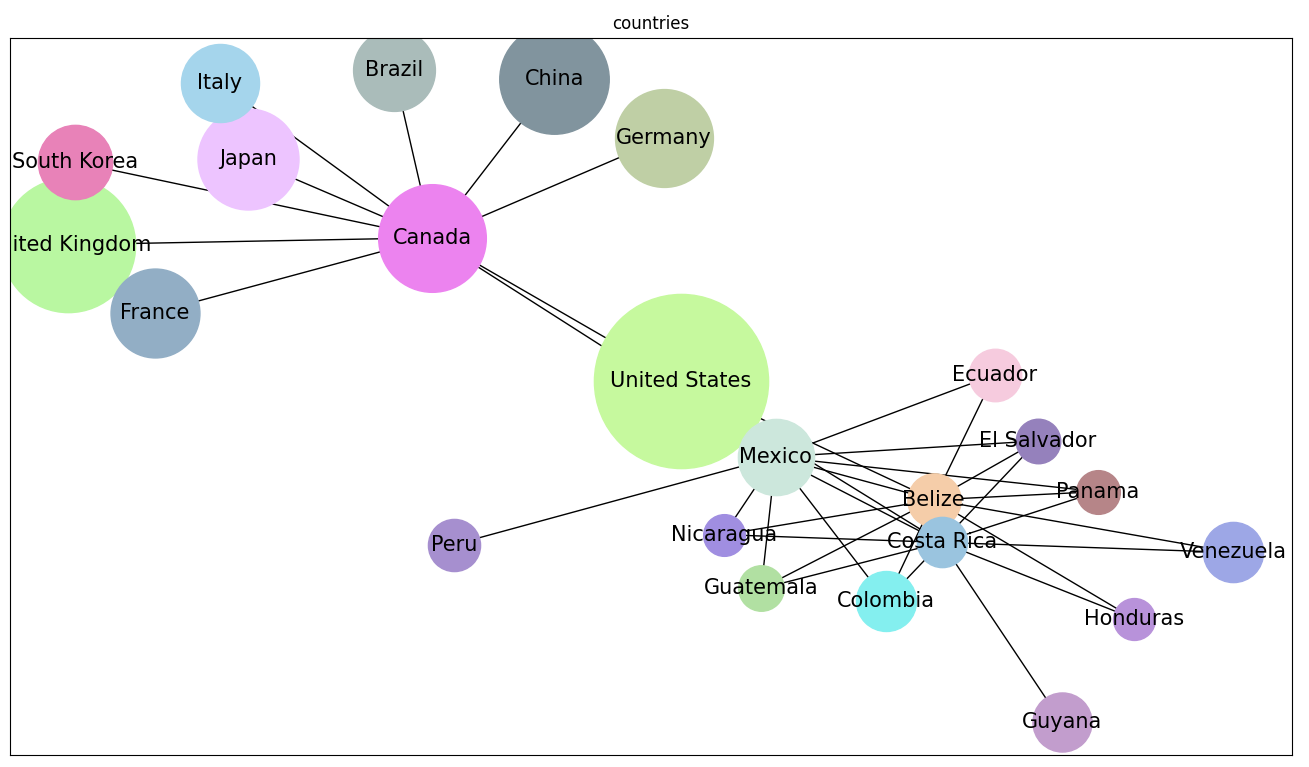
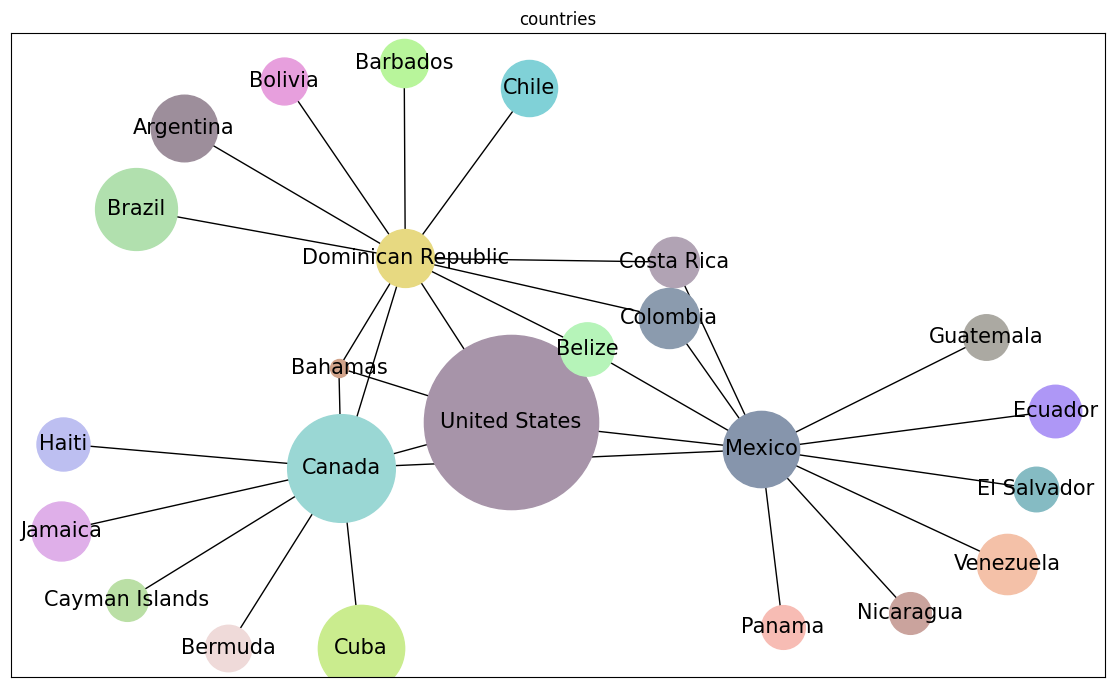
A list of countries that share a border with {}, separated by commas
I still haven’t entirely fixed my UTF 8 problem
Start writing up something about the belief maps to add to the chess paper, and maybe as an overall article
Country counts (150 vs 195 with no false positives, excluding six prompt countries, 76% coverage) Missing countries include Guadalupe, Guyana, Israel, Jordan, Lebanon, Madagascar, Liberia, Micronesia, Niger, Paraguay, Senegal, Sri Lanka, Tunisia, Uruguay, Venezuela, and Yemen
10:00 Meeting with Antonio. Nice discussion on moving forward. He suggests using the mapper to create a meta-knowledge graphing tool that works along the lines of the Third Author approach, where an expert can influence and interactively edit the creation of the maps
Worked on my UTF-8 problem, but it’s still not fixed
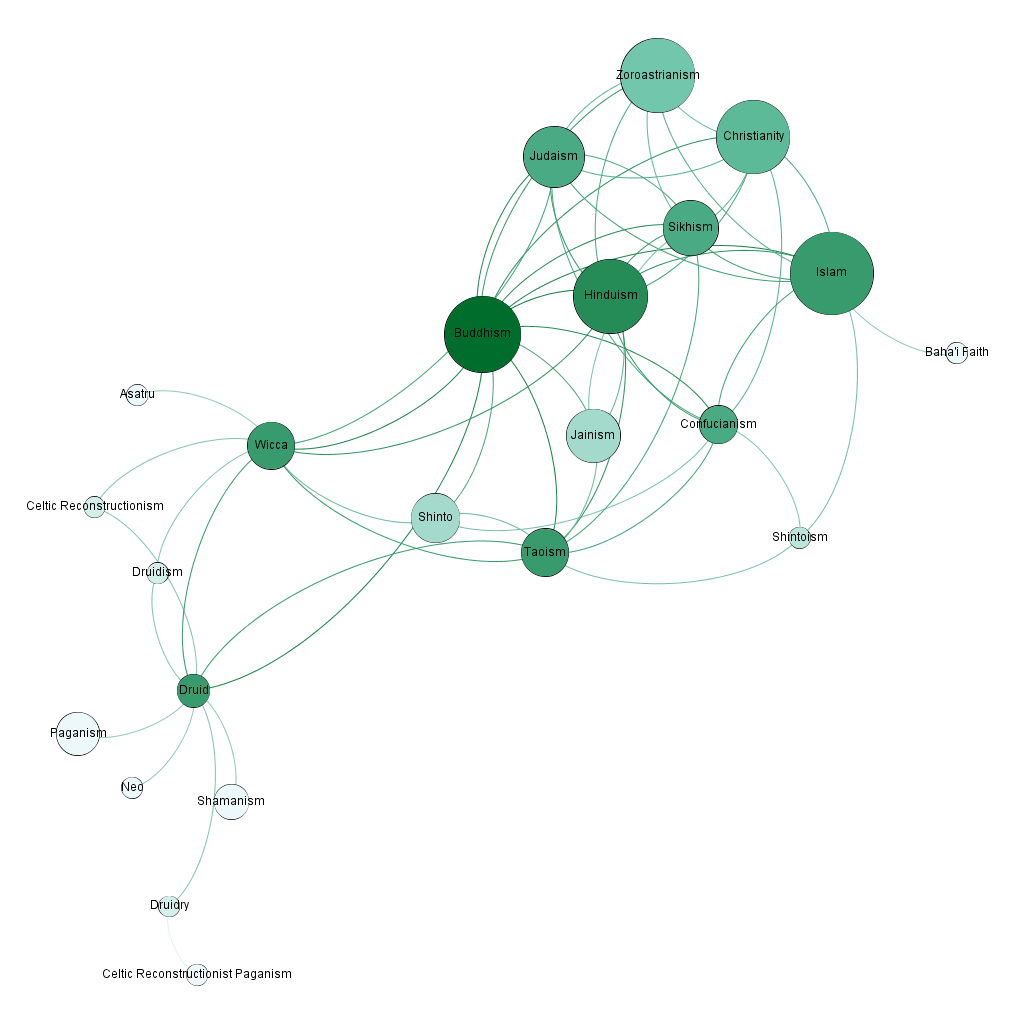
"A short list of the religions that are closest to {}:"
working with the model. There are more varied responses, so the parsing is a little more complex. The way that I’m currently working is by having the model return ten (rather than 3) responses that I then organize:
The first element is to look for a similar Wikipedia page, which is done as follows:
I think for the time being, I’ll just pull the first one (closest_list[0]) and see what that looks like, though I could also use all close matches or the one with the largest page views
Rolling all the changes into GraphToDB. Urk.
I had to tweak out some junk text (maybe UTF-8 issues?) Here’s an example: = “Baháʼí Faith” is being rendered as
Went nowhere. More than anything, this reminded me of a Defense with a hostile faculty lobbing hand grenades. In my list of management types, this guy was an assassin/power broker
GPT Agents
Got a ping from Ashwag on her team’s work, which was nice
Did some cleanup editing on the paper
Work on religion map if I get all the SBIR work done in time. Nope – tomorrow
Spent some time this morning adjusting the code so that experiment-specific regexes can be created and stored in the db. Also played around some with trying to figure out how to choose the best Wikipedia page(s?)
SBIR
Working on the status report. Mostly done. Need to do the summary paragraph
2:00 weekly meeting. Asked Peter and Loren to supply content by COB Thursday
Did a little housecleaning since I’m going to have to work on the status report for the rest of the week. I’ve moved the experiment-specific code into its own method and added a “node_type”
Updated the ICWSM paper to include the NSF grant info
3:00 Meeting
Spent a lot of time working on probes for belief systems such as white supremacy. It’s much more complex than countries. The parser needs(?) to be able to:
Split on \n as well as [,:;]
Ignore leading numbers
Match on earlier sections of each text (maybe just cut everything else after n words?)
Do a more forgiving match on the wikipedia. For example, the probe: “The great religions are all characterized by” returns a list that contains “Belief in a Messiah or a prophet.” Sending that to the wikipedia returns [‘Messiah’, ‘Messiah in Judaism’, “Judaism’s view of Jesus”, ‘Prophets and messengers in Islam’, ‘Jesus in Islam’, ‘False prophet’, ‘Last prophet’, ‘Prophet’, ‘Al-Masih ad-Dajjal’, ‘Messianism’], while splitting off the first two words (which are common across all results) to create “a Messiah or a prophet.” returns [‘Messiah’, ‘Messiah Prophet’, ‘False prophet’, ‘List of Jewish messiah claimants’, ‘Messiah in Judaism’, “Judaism’s view of Jesus”, ‘Last prophet’, ‘Jesus in Islam’, ‘Al-Masih ad-Dajjal’, ‘Messiah Part I’]
SBIR
9:15 Sprint planning
Read the docs that Clay wants me to check out
Work on status report
Redid the summary as a list of accomplishments that I now need to flesh out
I have a fancy world map! This one is 4kx4x so you can zoom in quite far. It started at
"A short list of countries that are nearest to United States, separated by commas:"
And worked its way out from that (e.g. “A short list of countries that are nearest to Canada, separated by commas:”). It looks like it had not worked its way over to Africa yet, and there is no Greenland.
Without that ‘headers’ element, you get a 404. Note that you do not need to spoof a browser header. This is all you need.
The second thing has to do with getting strings safely into databases
, when storing values with pymysql that involves strings that need to be escaped, you can now use parameter binding, which is very cool. BUT! Just because it uses ‘%s’, doesn’t mean that you use %d and %f. Here’s an example that uses strings, floats, and ints:
And here’s the call that does the actual writing to the db:
def write_sql_values_get_row(self, sql:str, values:Tuple): try: with self.connection.cursor() as cursor: cursor.execute(sql, values) id = cursor.lastrowid print("row id = {}".format(id)) return id except pymysql.err.InternalError as e: print("{}:\n\t{}".format(e, sql)) return -1
In this work, we explore “prompt tuning”, a simple yet effective mechanism for learning “soft prompts” to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned through backpropagation and can be tuned to incorporate signal from any number of labeled examples. Our end-to-end learned approach outperforms GPT-3’s “few-shot” learning by a large margin. More remarkably, through ablations on model size using T5, we show that prompt tuning becomes more competitive with scale: as models exceed billions of parameters, our method “closes the gap” and matches the strong performance of model tuning (where all model weights are tuned). This finding is especially relevant in that large models are costly to share and serve, and the ability to reuse one frozen model for multiple downstream tasks can ease this burden. Our method can be seen as a simplification of the recently proposed “prefix tuning” of Li and Liang (2021), and we provide a comparison to this and other similar approaches. Finally, we show that conditioning a frozen model with soft prompts confers benefits in robustness to domain transfer, as compared to full model tuning.
GPT-Agents
Start building out GraphToDB.
Use the Wikipedia to verify a node name exists before adding it
Check that a (directed) edge exists before adding it. If it does, increment the weight.
This book examines how people understand utterances that are intended figuratively. Traditionally, figurative language such as metaphors and idioms has been considered derivative from more complex than ostensibly straightforward literal language. Glucksberg argues that figurative language involves the same kinds of linguistic and pragmatic operations that are used for ordinary, literal language. Glucksberg’s research in this book is concerned with ordinary language: expressions that are used in daily life, including conversations about everyday matters, newspaper and magazine articles, and the media. Metaphor is the major focus of the book. Idioms, however, are also treated comprehensively, as is the theory of conceptual metaphor in the context of how people understand both conventional and novel figurative expressions. A new theory of metaphor comprehension is put forward, and evaluated with respect to competing theories in linguistics and in psychology. The central tenet of the theory is that ordinary conversational metaphors are used to create new concepts and categories. This process is spontaneous and automatic. Metaphor is special only in the sense that these categories get their names from the best examples of the things they represent, and that these categories get their names from the best examples of those categories. Thus, the literal “shark” can be a metaphor for any vicious and predatory being, from unscrupulous salespeople to a murderous character in The Threepenny Opera. Because the same term, e.g.,”shark,” is used both for its literal referent and for the metaphorical category, as in “My lawyer is a shark,” we call it the dual-reference theory. The theory is then extended to two other domains: idioms and conceptual metaphors. The book presents the first comprehensive account of how people use and understand metaphors in everyday life
This paper outlines a multi-dimensional/multi-disciplinary framework for the study of metaphor. It expands on the cognitive linguistic approach to metaphor in language and thought by adding the dimension of communication, and it expands on the predominantly linguistic and psychological approaches by adding the discipline of social science. This creates a map of the field in which nine main areas of research can be distinguished and connected to each other in precise ways. It allows for renewed attention to the deliberate use of metaphor in communication, in contrast with non-deliberate use, and asks the question whether the interaction between deliberate and non-deliberate use of metaphor in specific social domains can contribute to an explanation of the discourse career of metaphor. The suggestion is made that metaphorical models in language, thought, and communication can be classified as official, contested, implicit, and emerging, which may offer new perspectives on the interaction between social, psychological, and linguistic properties and functions of metaphor in discourse.
SBIR
10:00 Meeting
See how the new models are doing. If we are still not making progress, then go to a simpler interpolation model
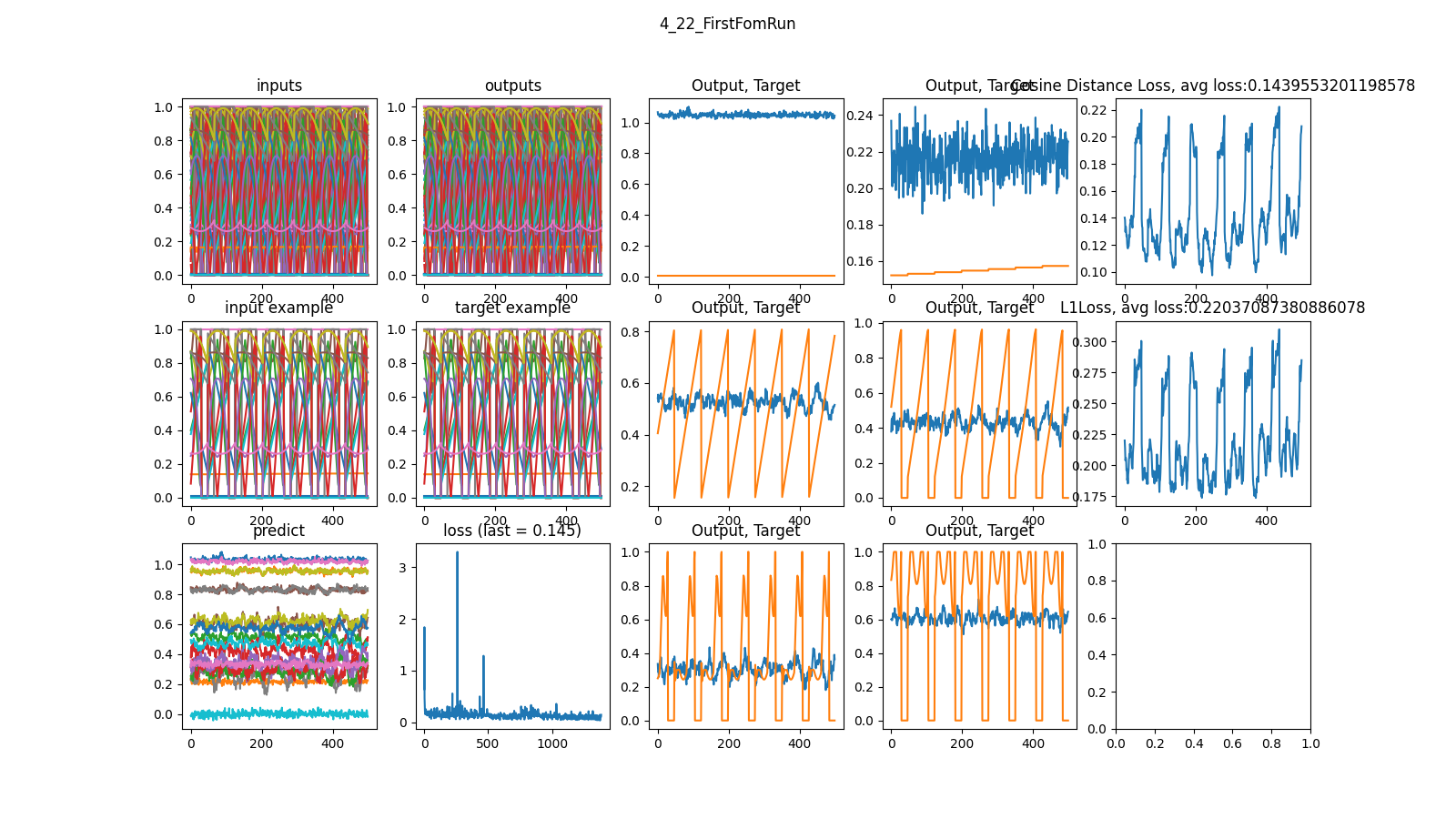
It turns out that the frequency problem was actually a visualization bug! Here’s an example going from 20 input vectors to 500 output vectors using attention and 2 3,000 perceptron layers:
Had an interesting talk with Aaron last night about using FB microtargeting as a mechanism to provide “deprogramming” content to folks that are going down conspiracy rabbit holes. We could also use the GPT-3
Thinking aloud is an effective meta-cognitive strategy human reasoners apply to solve difficult problems. We suggest to improve the reasoning ability of pre-trained neural language models in a similar way, namely by expanding a task’s context with problem elaborations that are dynamically generated by the language model itself. Our main result is that dynamic problem elaboration significantly improves the zero-shot performance of GPT-2 in a deductive reasoning and natural language inference task: While the model uses a syntactic heuristic for predicting an answer, it is capable (to some degree) of generating reasoned additional context which facilitates the successful application of its heuristic. We explore different ways of generating elaborations, including fewshot learning, and find that their relative performance varies with the specific problem characteristics (such as problem difficulty). Moreover, the effectiveness of an elaboration can be explained in terms of the degree to which the elaboration semantically coheres with the corresponding problem. In particular, elaborations that are most faithful to the original problem description may boost accuracy by up to 24%.
This page documents the Pageview API (v1), a public API developed and maintained by the Wikimedia Foundation that serves analytical data about article pageviews of Wikipedia and its sister projects. With it, you can get pageview trends on specific articles or projects; filter by agent type or access method, and choose different time ranges and granularities; you can also get the most viewed articles of a certain project and timespan, and even check out the countries that visit a project the most. Have fun!
Wikimedia REST API: This API provides cacheable and straightforward access to Wikimedia content and data, in machine-readable formats.
3:00 Meeting
Paper is pending ArXiv!
SBIR
Asked Rukan to save of some well trained models to play with
So what happened was, I asked one question. I said, “How many people in here believe in diversity?” Everybody shot their hands up. Boom. Everybody. I said, “Answer this one next question.” And I said, “Don’t bring your hands down. Answer this question. Diverse from what?”

















You must be logged in to post a comment.