
Homicide is a leading cause of death for pregnant women in US
- Women in the US are more likely to be murdered during pregnancy or soon after childbirth than to die from the three leading obstetric causes of maternal mortality (hypertensive disorders, haemorrhage, or sepsis).1 These pregnancy associated homicides are preventable, and most are linked to the lethal combination of intimate partner violence and firearms. Preventing men’s violence towards women, including gun violence, could save the lives of hundreds of women and their unborn children in the US every year
Book
- Rolling in more edits
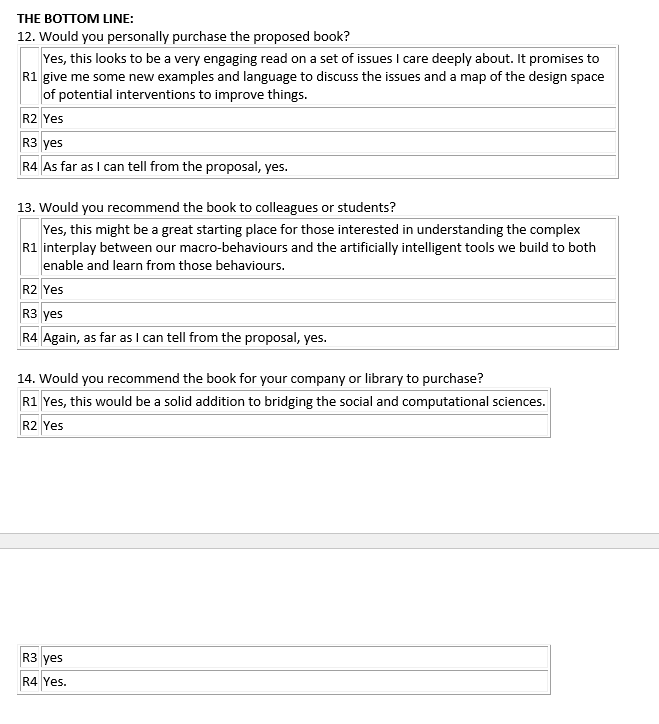
- “In the meantime, some great news—the project is now officially approved! I’m now just waiting for a draft of the publishing agreement, so as soon as that’s ready I will send it over.”
GPT Agents
- Finish db access and build a view to see the text and meta info
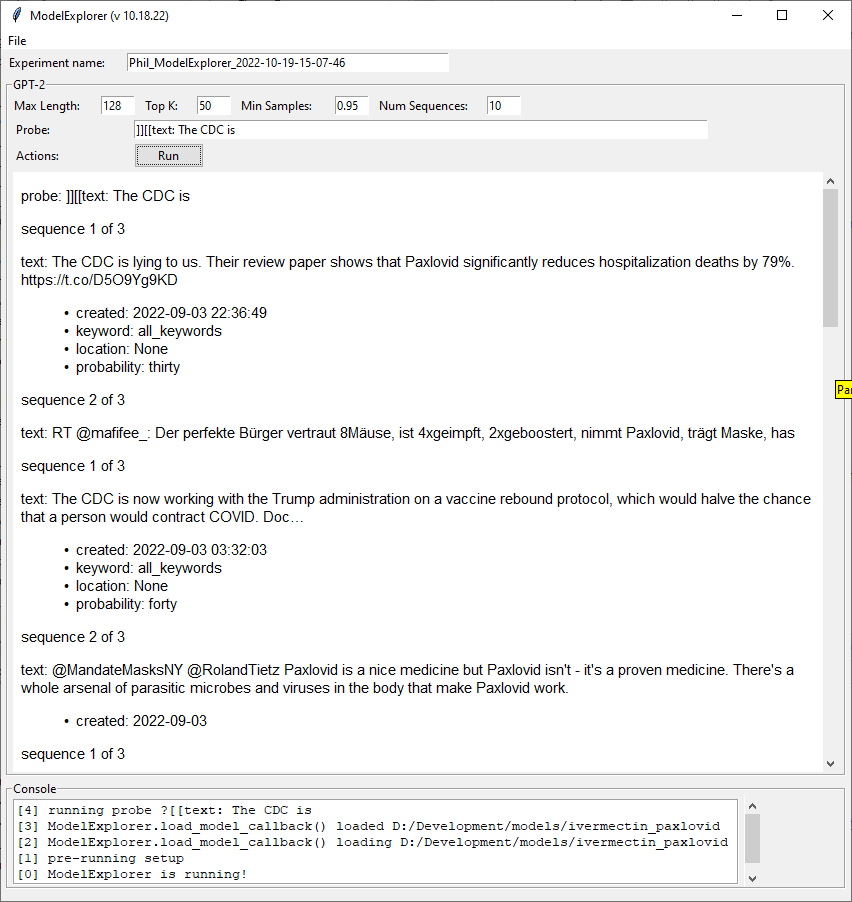
- Here’s a view that I created to link multiple rows of key/values to a root result. Really proud of this:
create or replace view test_view as
select tt.*, ttd_k.value as keyword, ttd_c.value as created, ttd_l.value as location, ttd_p.value as probability
FROM table_text tt
inner join table_text_data ttd_c on tt.id = ttd_c.text_id and ttd_c.name = 'created'
inner join table_text_data ttd_k on tt.id = ttd_k.text_id and ttd_k.name = 'keyword'
inner join table_text_data ttd_l on tt.id = ttd_l.text_id and ttd_l.name = 'location'
inner join table_text_data ttd_p on tt.id = ttd_p.text_id and ttd_p.name = 'probability';
SBIRs
- 9:15 standup
- 11:30 Touch point
- Work on paper. Reading the DSIAC-BCO-2022-216 report, which is a lot less than I thought it would be considering the page count, but has some good stuff in it.
- Add example paragraph to rationale section
- Add mute() method and flag – done. Also added the publish
- Make publish work with base classes










You must be logged in to post a comment.