info: {'title': 'Google Custom Search - Feldman', 'totalResults': '3', 'searchTerms': 'Feldman', 'count': 3, 'startIndex': 1, 'inputEncoding': 'utf8', 'outputEncoding': 'utf8', 'safe': 'off', 'cx': '814dff357c3d046aa', 'sort': 'date:r:20140815:20140931', 'siteSearch': "'twitter.com'"}
result: {'kind': 'customsearch#result', 'title': 'Lee Feldman (@socialname) / Twitter', 'htmlTitle': 'Lee <b>Feldman</b> (@socialname) / Twitter', 'link': 'https://twitter.com/socialname', 'displayLink': 'twitter.com', 'snippet': 'The movie is a story about guns, the actors play with guns, the filmmakers film the actors playing with guns, people pay money to watch actors shoot each\xa0...', 'htmlSnippet': 'The movie is a story about guns, the actors play with guns, the filmmakers film the actors playing with guns, people pay money to watch actors shoot each ...', 'cacheId': 'ikO6smL2LU8J', 'formattedUrl': 'https://twitter.com/socialname', 'htmlFormattedUrl': 'https://twitter.com/socialname', 'pagemap': {'cse_thumbnail': [{'src': 'https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcQf5Fy-jP0AucDWFoXHgEe-hdNYkWXZRaHMEtZeX8-1Cbpix4XyimvI', 'width': '48', 'height': '48'}], 'imageobject': [{'contenturl': 'https://pbs.twimg.com/media/Eq5vt8SW4AE2x6y.png', 'width': '526', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/Eq5vt8SW4AE2x6y?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/EpIuQ5wXIAA7J9z.jpg', 'width': '2320', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/EpIuQ5wXIAA7J9z?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/Ef-VpbUXsAQ5hu4.jpg', 'width': '640', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/Ef-VpbUXsAQ5hu4?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/EdxhcAKWsAIOpbn.jpg', 'width': '1435', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/EdxhcAKWsAIOpbn?format=jpg&name=thumb'}], 'person': [{'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '472264728', 'givenname': 'Rockwood Music Hall', 'additionalname': 'RockwoodNYC'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '472264728', 'givenname': 'Rockwood Music Hall', 'additionalname': 'RockwoodNYC'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}, {'identifier': '17959954', 'givenname': 'Lee Feldman', 'additionalname': 'socialname'}], 'interactioncounter': [{'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1530016637235109888/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1530016637235109888/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1530016637235109888/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1530016637235109888'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1499384946405916677/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1499384946405916677/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1499384946405916677/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1499384946405916677'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1484668397723992067/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1484668397723992067/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1484668397723992067/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1484668397723992067'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1484668131805122565/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1484668131805122565/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1484668131805122565/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1484668131805122565'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1484667880826445825/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1484667880826445825/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1484667880826445825/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1484667880826445825'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1484667602928644096/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1484667602928644096/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1484667602928644096/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1484667602928644096'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1484667380529778689/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1484667380529778689/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1484667380529778689/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1484667380529778689'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1453643457034076161/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1453643457034076161/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1453643457034076161/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1453643457034076161'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1445932140831690754/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1445932140831690754/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1445932140831690754/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1445932140831690754'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/RockwoodNYC/status/1443313381570719750/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/RockwoodNYC/status/1443313381570719750/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/RockwoodNYC/status/1443313381570719750/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/RockwoodNYC/status/1443313381570719750'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/RockwoodNYC/status/1441066576594317313/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/RockwoodNYC/status/1441066576594317313/retweets'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/RockwoodNYC/status/1441066576594317313/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/RockwoodNYC/status/1441066576594317313'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1436460302728667143/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1436460302728667143/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1436460302728667143/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1436460302728667143'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1424076841808277514/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1424076841808277514/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1424076841808277514/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1424076841808277514'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1410132480489922560/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1410132480489922560/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1410132480489922560/retweets/with_comments'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1410132480489922560'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1408177757876543494/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1408177757876543494/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1408177757876543494/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1408177757876543494'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1401631392115609600/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1401631392115609600/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1401631392115609600/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1401631392115609600'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1399479911740579845/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1399479911740579845/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1399479911740579845/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1399479911740579845'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1396943555785072640/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1396943555785072640/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1396943555785072640/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1396943555785072640'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1396808849596760066/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1396808849596760066/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1396808849596760066/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1396808849596760066'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1396275518413099011/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1396275518413099011/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1396275518413099011/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1396275518413099011'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1396267736288858114/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1396267736288858114/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1396267736288858114/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1396267736288858114'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1393954195909267457/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1393954195909267457/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1393954195909267457/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1393954195909267457'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1382968363803148291/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1382968363803148291/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1382968363803148291/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1382968363803148291'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1382506160520101889/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1382506160520101889/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1382506160520101889/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1382506160520101889'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1375568476673351683/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1375568476673351683/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1375568476673351683/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1375568476673351683'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1346136240664563713/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1346136240664563713/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1346136240664563713/retweets/with_comments'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1346136240664563713'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1338183208094097411/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1338183208094097411/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1338183208094097411/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1338183208094097411'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1325837162844205056/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1325837162844205056/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1325837162844205056/retweets/with_comments'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1325837162844205056'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1312178361049903104/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1312178361049903104/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1312178361049903104/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1312178361049903104'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1311129736467415042/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1311129736467415042/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1311129736467415042/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1311129736467415042'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1307845832012685318/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1307845832012685318/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1307845832012685318/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1307845832012685318'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1306213933922086913/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1306213933922086913/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1306213933922086913/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1306213933922086913'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1299528850800627714/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1299528850800627714/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1299528850800627714/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1299528850800627714'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1298023868347617285/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1298023868347617285/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1298023868347617285/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1298023868347617285'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1296919767400550401/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1296919767400550401/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1296919767400550401/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1296919767400550401'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1287011341425942528/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1287011341425942528/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1287011341425942528/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1287011341425942528'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1284272610768027649/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1284272610768027649/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1284272610768027649/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1284272610768027649'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1283524349983588353/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1283524349983588353/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1283524349983588353/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1283524349983588353'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1281770776199335937/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1281770776199335937/retweets'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1281770776199335937/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1281770776199335937'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/socialname/status/1280658620934492160/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/socialname/status/1280658620934492160/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/socialname/status/1280658620934492160/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/socialname/status/1280658620934492160'}], 'metatags': [{'og:image': 'https://pbs.twimg.com/profile_images/556845044854829058/rUuJKTvx_normal.jpeg', 'theme-color': '#ffffff', 'og:type': 'profile', 'og:site_name': 'Twitter', 'al:ios:app_name': 'Twitter', 'apple-mobile-web-app-title': 'Twitter', 'og:title': 'Lee Feldman (@socialname) / Twitter', 'al:android:package': 'com.twitter.android', 'al:ios:url': 'twitter://user?screen_name=socialname', 'og:description': 'i make a living . . .', 'al:ios:app_store_id': '333903271', 'facebook-domain-verification': 'x6sdcc8b5ju3bh8nbm59eswogvg6t1', 'al:android:url': 'twitter://user?screen_name=socialname', 'fb:app_id': '2231777543', 'apple-mobile-web-app-status-bar-style': 'white', 'viewport': 'width=device-width,initial-scale=1,maximum-scale=1,user-scalable=0,viewport-fit=cover', 'mobile-web-app-capable': 'yes', 'og:url': 'https://twitter.com/socialname', 'al:android:app_name': 'Twitter'}], 'collection': [{'name': 'Profile Tweets'}], 'creativework': [{'name': 'Expanded Tweet URLs', 'url': 'https://t.co/H0JWHiCyhM'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/PGBIiesb9c'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/pzaFA5afro'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/sUzDXEUFEK'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/PdYNeWnRuJ'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/vELggHgdfG'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/L5oZ0gmHcI'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/WWvAdsStmh'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/WWvAdsStmh'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/PdYNeWnRuJ'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/dD8rYle5qv'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/pALK9miIxF'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/klx4HJ7fxo'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/d4GStmfdNx'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/1ja2M4Gmzw'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/GlswaaGF6N'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/quxv2EjO9o'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/Oj9Y1lOfyV'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/1Sm64N6RHu'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/wgRZe6b3d0'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/iArOXgnboD'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/TarjpL9qtS'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/zW7sVY05JX'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/ROGjpHAgtJ'}], 'cse_image': [{'src': 'https://pbs.twimg.com/profile_images/556845044854829058/rUuJKTvx_normal.jpeg'}], 'socialmediaposting': [{'identifier': '1530016637235109888', 'commentcount': '1', 'articlebody': 'Note to self: There\'s no "I" in brain . . .', 'position': '1', 'datecreated': '2022-05-27T02:42:47.000Z', 'datepublished': '2022-05-27T02:42:47.000Z', 'url': 'https://twitter.com/socialname/status/1530016637235109888'}, {'identifier': '1499384946405916677', 'commentcount': '0', 'articlebody': 'Grateful, yet mourning. Hello to you all . .', 'position': '2', 'datecreated': '2022-03-03T14:03:23.000Z', 'datepublished': '2022-03-03T14:03:23.000Z', 'url': 'https://twitter.com/socialname/status/1499384946405916677'}, {'identifier': '1484668397723992067', 'commentcount': '0', 'articlebody': '"Anybody have a tampon?" #patter #awkward #periods #leefeldman', 'position': '3', 'datecreated': '2022-01-21T23:25:04.000Z', 'datepublished': '2022-01-21T23:25:04.000Z', 'url': 'https://twitter.com/socialname/status/1484668397723992067'}, {'identifier': '1484668131805122565', 'commentcount': '1', 'articlebody': 'This next song is from my opera "Con Ed, Thank You for Your Years of Service." #conedison #opera #patter #leefeldman #awkward', 'position': '4', 'datecreated': '2022-01-21T23:24:01.000Z', 'datepublished': '2022-01-21T23:24:01.000Z', 'url': 'https://twitter.com/socialname/status/1484668131805122565'}, {'identifier': '1484667880826445825', 'commentcount': '0', 'articlebody': '"My family is on a new diet . . only venison." "Oh, dear." #patter #leefeldman #venison #diet #awkward', 'position': '5', 'datecreated': '2022-01-21T23:23:01.000Z', 'datepublished': '2022-01-21T23:23:01.000Z', 'url': 'https://twitter.com/socialname/status/1484667880826445825'}, {'identifier': '1484667602928644096', 'commentcount': '1', 'articlebody': '"How\'s everybody doing . . . financially?" #patter #leefeldman #Finance #awkward', 'position': '6', 'datecreated': '2022-01-21T23:21:54.000Z', 'datepublished': '2022-01-21T23:21:54.000Z', 'url': 'https://twitter.com/socialname/status/1484667602928644096'}, {'identifier': '1484667380529778689', 'commentcount': '0', 'articlebody': 'This next song is from my ballet "People Have Problems." #patter #awkward #leefeldman #ballet', 'position': '7', 'datecreated': '2022-01-21T23:21:01.000Z', 'datepublished': '2022-01-21T23:21:01.000Z', 'url': 'https://twitter.com/socialname/status/1484667380529778689'}, {'identifier': '1453643457034076161', 'commentcount': '0', 'articlebody': 'The movie is a story about guns, the actors play with guns, the filmmakers film the actors playing with guns, people pay money to watch actors shoot each other with guns while Americans kill...', 'position': '8', 'datecreated': '2021-10-28T08:43:02.000Z', 'datepublished': '2021-10-28T08:43:02.000Z', 'url': 'https://twitter.com/socialname/status/1453643457034076161'}, {'identifier': '1445932140831690754', 'commentcount': '0', 'position': '9', 'datecreated': '2021-10-07T02:01:01.000Z', 'datepublished': '2021-10-07T02:01:01.000Z', 'url': 'https://twitter.com/socialname/status/1445932140831690754'}, {'identifier': '1443924931893415940', 'position': '10', 'datecreated': '2021-10-01T13:05:05.000Z', 'datepublished': '2021-10-01T13:05:05.000Z'}, {'identifier': '1443313381570719750', 'commentcount': '0', 'articlebody': 'Saturday w/ @socialname! . https://youtube.com/watch?v=Yr-DOwjs5Iw&ab_channel=LeeFeldman…', 'datecreated': '2021-09-29T20:35:00.000Z', 'isbasedon': 'https://twitter.com/RockwoodNYC/status/1441066576594317313', 'datepublished': '2021-09-29T20:35:00.000Z', 'url': 'https://twitter.com/RockwoodNYC/status/1443313381570719750'}, {'identifier': '1442188873438793732', 'position': '11', 'datecreated': '2021-09-26T18:06:36.000Z', 'datepublished': '2021-09-26T18:06:36.000Z'}, {'identifier': '1441066576594317313', 'commentcount': '0', 'articlebody': '#NewShow ⭐️ Lee Feldman (@socialname) 🎤 Stage (3) October 2, 2021 | 7PM TICKETS: https://seetickets.us/LeeFeldmanOct0221…', 'datecreated': '2021-09-23T15:47:00.000Z', 'datepublished': '2021-09-23T15:47:00.000Z', 'url': 'https://twitter.com/RockwoodNYC/status/1441066576594317313'}, {'identifier': '1436460302728667143', 'commentcount': '0', 'articlebody': 'LEE FELDMAN / Save the Date! - https://mailchi.mp/b0d83d5bf644/edge-keep-me-around-vinyl-release-website-8035173…', 'position': '12', 'datecreated': '2021-09-10T22:43:18.000Z', 'datepublished': '2021-09-10T22:43:18.000Z', 'url': 'https://twitter.com/socialname/status/1436460302728667143'}, {'identifier': '1424076841808277514', 'commentcount': '0', 'articlebody': 'Other people call themselves a singer-songwriter, but I prefer the term “dentist.” http://leefeldman.com', 'position': '13', 'datecreated': '2021-08-07T18:35:51.000Z', 'datepublished': '2021-08-07T18:35:51.000Z', 'url': 'https://twitter.com/socialname/status/1424076841808277514'}, {'identifier': '1410132480489922560', 'commentcount': '2', 'articlebody': '"Happy teeth, happy wallet . . "', 'position': '14', 'datecreated': '2021-06-30T07:05:57.000Z', 'datepublished': '2021-06-30T07:05:57.000Z', 'url': 'https://twitter.com/socialname/status/1410132480489922560'}, {'identifier': '1408177757876543494', 'commentcount': '1', 'articlebody': 'My attorney asked me why I would record a song that uses my social security number as part of the lyrics, so I used his instead. Now he won’t return my calls . .', 'position': '15', 'datecreated': '2021-06-24T21:38:34.000Z', 'datepublished': '2021-06-24T21:38:34.000Z', 'url': 'https://twitter.com/socialname/status/1408177757876543494'}, {'identifier': '1401631392115609600', 'commentcount': '0', 'articlebody': 'My childhood friend Josh Feldstein\'s mother, Ellie, once said "Josh, if you can get through life, you can get through anything."', 'position': '16', 'datecreated': '2021-06-06T20:05:39.000Z', 'datepublished': '2021-06-06T20:05:39.000Z', 'url': 'https://twitter.com/socialname/status/1401631392115609600'}, {'identifier': '1399479911740579845', 'commentcount': '0', 'articlebody': 'It Was a Terrible Thing https://fb.watch/5R45XZdK79/ via @FacebookWatch', 'position': '17', 'datecreated': '2021-05-31T21:36:26.000Z', 'datepublished': '2021-05-31T21:36:26.000Z', 'url': 'https://twitter.com/socialname/status/1399479911740579845'}, {'identifier': '1396943555785072640', 'commentcount': '0', 'articlebody': 'Fuck antisemitism #fuckantisemitism', 'position': '18', 'datecreated': '2021-05-24T21:37:52.000Z', 'datepublished': '2021-05-24T21:37:52.000Z', 'url': 'https://twitter.com/socialname/status/1396943555785072640'}, {'identifier': '1396808849596760066', 'commentcount': '0', 'articlebody': 'Happy 80th birthday, Bob Dylan . . . now stop making me think about you! #bobdylan80', 'position': '19', 'datecreated': '2021-05-24T12:42:35.000Z', 'datepublished': '2021-05-24T12:42:35.000Z', 'url': 'https://twitter.com/socialname/status/1396808849596760066'}, {'identifier': '1396275518413099011', 'commentcount': '0', 'articlebody': '"\'Cause if I fly I\'ll surely die, and I want to stay around . . " https://leefeldman.bandcamp.com/track/reluctant-cicada… @MargaretRenkl @eleanorlutz @jesusjiminez @scottdodd', 'position': '20', 'datecreated': '2021-05-23T01:23:19.000Z', 'datepublished': '2021-05-23T01:23:19.000Z', 'url': 'https://twitter.com/socialname/status/1396275518413099011'}, {'identifier': '1396267736288858114', 'commentcount': '0', 'articlebody': 'The cicadas are reluctant! https://leefeldman.bandcamp.com/track/reluctant-cicada… #relucantcicada @cjgiaimo #CicadaWatch2021 #cicadas2021 #CicadaBroodX #cicadapocalypse', 'position': '21', 'datecreated': '2021-05-23T00:52:24.000Z', 'datepublished': '2021-05-23T00:52:24.000Z', 'url': 'https://twitter.com/socialname/status/1396267736288858114'}, {'identifier': '1393954195909267457', 'commentcount': '0', 'articlebody': 'Working on slightly altered jazz standards. Today, “All the Things You Ate” . .', 'position': '22', 'datecreated': '2021-05-16T15:39:13.000Z', 'datepublished': '2021-05-16T15:39:13.000Z', 'url': 'https://twitter.com/socialname/status/1393954195909267457'}, {'identifier': '1382968363803148291', 'commentcount': '0', 'articlebody': 'I guess you could say I\'m a singer/songwriter, but I really prefer the term "dentist" . . . http://leefeldman.com', 'position': '23', 'datecreated': '2021-04-16T08:05:26.000Z', 'datepublished': '2021-04-16T08:05:26.000Z', 'url': 'https://twitter.com/socialname/status/1382968363803148291'}, {'identifier': '1382506160520101889', 'commentcount': '1', 'position': '24', 'datecreated': '2021-04-15T01:28:49.000Z', 'datepublished': '2021-04-15T01:28:49.000Z', 'url': 'https://twitter.com/socialname/status/1382506160520101889'}, {'identifier': '1375568476673351683', 'commentcount': '0', 'articlebody': 'Look what I found! STARBOY Eye (one look from my eye is the maximum . . ) collectible https://rarible.com/token/0xd07dc4262bcdbf85190c01c996b4c06a461d2430:385771:0x92a6406bdd9802b28749aeab93ca742a1...', 'position': '25', 'datecreated': '2021-03-26T22:00:56.000Z', 'datepublished': '2021-03-26T22:00:56.000Z', 'url': 'https://twitter.com/socialname/status/1375568476673351683'}, {'identifier': '1346136240664563713', 'commentcount': '2', 'articlebody': 'Which part of "Meow" don\'t you understand?', 'position': '26', 'datecreated': '2021-01-04T16:47:44.000Z', 'datepublished': '2021-01-04T16:47:44.000Z', 'url': 'https://twitter.com/socialname/status/1346136240664563713'}, {'identifier': '1338183208094097411', 'commentcount': '1', 'articlebody': 'Door-hanging for the DSA in Riverdale! @JefferyDinowitz #taxtherich #dsausa', 'position': '27', 'datecreated': '2020-12-13T18:05:13.000Z', 'datepublished': '2020-12-13T18:05:13.000Z', 'url': 'https://twitter.com/socialname/status/1338183208094097411'}, {'identifier': '1325837162844205056', 'commentcount': '2', 'articlebody': 'The Feldman (November, 2020) - https://mailchi.mp/c5ba89a524b1/the-feldman-november-2020…', 'position': '28', 'datecreated': '2020-11-09T16:26:27.000Z', 'datepublished': '2020-11-09T16:26:27.000Z', 'url': 'https://twitter.com/socialname/status/1325837162844205056'}, {'identifier': '1312178361049903104', 'commentcount': '0', 'articlebody': 'MANTIC Trio (Lee Feldman, Rob Price, Chris Moore) "Gangly" https://youtu.be/yuZHxn7WY7k via @YouTube', 'position': '29', 'datecreated': '2020-10-02T23:51:15.000Z', 'datepublished': '2020-10-02T23:51:15.000Z', 'url': 'https://twitter.com/socialname/status/1312178361049903104'}, {'identifier': '1311129736467415042', 'commentcount': '1', 'articlebody': 'Watch “Edge, The Story” on #Vimeo', 'position': '30', 'datecreated': '2020-09-30T02:24:23.000Z', 'datepublished': '2020-09-30T02:24:23.000Z', 'url': 'https://twitter.com/socialname/status/1311129736467415042'}, {'identifier': '1307845832012685318', 'commentcount': '0', 'articlebody': 'MANTIC Trio ad https://youtu.be/3htEbnEX0vQ via @YouTube', 'position': '31', 'datecreated': '2020-09-21T00:55:19.000Z', 'datepublished': '2020-09-21T00:55:19.000Z', 'url': 'https://twitter.com/socialname/status/1307845832012685318'}, {'identifier': '1306213933922086913', 'commentcount': '0', 'position': '32', 'datecreated': '2020-09-16T12:50:44.000Z', 'datepublished': '2020-09-16T12:50:44.000Z', 'url': 'https://twitter.com/socialname/status/1306213933922086913'}, {'identifier': '1299528850800627714', 'commentcount': '0', 'articlebody': "That's the way the world used to work . . .", 'position': '33', 'datecreated': '2020-08-29T02:06:36.000Z', 'datepublished': '2020-08-29T02:06:36.000Z', 'url': 'https://twitter.com/socialname/status/1299528850800627714'}, {'identifier': '1298023868347617285', 'commentcount': '1', 'articlebody': 'Dude. This is like Flipper meets Butthole Surfers meets Eno meets Psychic TV meets bizarre jazz shit I have no idea who. This is new breakthrough shit. Melodic, ambient dissonance. Discord...', 'position': '34', 'datecreated': '2020-08-24T22:26:20.000Z', 'datepublished': '2020-08-24T22:26:20.000Z', 'url': 'https://twitter.com/socialname/status/1298023868347617285'}, {'identifier': '1296919767400550401', 'commentcount': '0', 'articlebody': 'Mantic Trio https://open.spotify.com/artist/0tiRfdKuqyUrmniSosfYii?si=il9CTc9zSeCFpO3jTmkbzA… #NowPlaying', 'position': '35', 'datecreated': '2020-08-21T21:19:02.000Z', 'datepublished': '2020-08-21T21:19:02.000Z', 'url': 'https://twitter.com/socialname/status/1296919767400550401'}, {'identifier': '1287011341425942528', 'commentcount': '0', 'articlebody': 'Mantic Trio coming out next month, with Chris Moore, drums and Rob Price, guitar #experimentalmusic #improvisedmusic, #noiserock', 'position': '36', 'datecreated': '2020-07-25T13:06:29.000Z', 'datepublished': '2020-07-25T13:06:29.000Z', 'url': 'https://twitter.com/socialname/status/1287011341425942528'}, {'identifier': '1284272610768027649', 'commentcount': '0', 'articlebody': 'Fascism is here (Portland). National strike, anyone?', 'position': '37', 'datecreated': '2020-07-17T23:43:45.000Z', 'datepublished': '2020-07-17T23:43:45.000Z', 'url': 'https://twitter.com/socialname/status/1284272610768027649'}, {'identifier': '1283524349983588353', 'commentcount': '0', 'position': '38', 'datecreated': '2020-07-15T22:10:26.000Z', 'datepublished': '2020-07-15T22:10:26.000Z', 'url': 'https://twitter.com/socialname/status/1283524349983588353'}, {'identifier': '1281770776199335937', 'commentcount': '0', 'articlebody': '“What should one do with one’s life? More money is not the answer — it only postpones answering the question.” Giorgos Kallis (Degrowth)', 'position': '39', 'datecreated': '2020-07-11T02:02:21.000Z', 'datepublished': '2020-07-11T02:02:21.000Z', 'url': 'https://twitter.com/socialname/status/1281770776199335937'}, {'identifier': '1280658620934492160', 'commentcount': '0', 'articlebody': '"Life isn\'t everything." - Mike Nichols', 'position': '40', 'datecreated': '2020-07-08T00:23:03.000Z', 'datepublished': '2020-07-08T00:23:03.000Z', 'url': 'https://twitter.com/socialname/status/1280658620934492160'}]}}
result: {'kind': 'customsearch#result', 'title': 'ً(@whosbenfeldman) / Twitter', 'htmlTitle': 'ً(@whosbenfeldman) / Twitter', 'link': 'https://twitter.com/whosbenfeldman', 'displayLink': 'twitter.com', 'snippet': 'almost definitely not affiliated with. @benmfeldman. simmcsa Joined July 2020. 52 Following · 121 Followers · Tweets · Tweets & replies.', 'htmlSnippet': 'almost definitely not affiliated with. @benmfeldman. simmcsa Joined July 2020. 52 Following · 121 Followers · Tweets · Tweets & replies.', 'cacheId': 'i8ppeNoJR_MJ', 'formattedUrl': 'https://twitter.com/whosbenfeldman', 'htmlFormattedUrl': 'https://twitter.com/whosben<b>feldman</b>', 'pagemap': {'cse_thumbnail': [{'src': 'https://encrypted-tbn2.gstatic.com/images?q=tbn:ANd9GcSDoZIZ2uiMih4JGdf4JLVCeNmI9X3hGF9F498Be-WT007Lx2bUh8nE5Q', 'width': '48', 'height': '48'}], 'metatags': [{'og:image': 'https://pbs.twimg.com/profile_images/1295130901064478720/PztMlBbx_normal.jpg', 'theme-color': '#ffffff', 'og:type': 'profile', 'og:site_name': 'Twitter', 'al:ios:app_name': 'Twitter', 'apple-mobile-web-app-title': 'Twitter', 'og:title': 'ً (@whosbenfeldman) / Twitter', 'al:android:package': 'com.twitter.android', 'al:ios:url': 'twitter://user?screen_name=whosbenfeldman', 'og:description': 'almost definitely not affiliated with @benmfeldman', 'al:ios:app_store_id': '333903271', 'facebook-domain-verification': 'x6sdcc8b5ju3bh8nbm59eswogvg6t1', 'al:android:url': 'twitter://user?screen_name=whosbenfeldman', 'fb:app_id': '2231777543', 'apple-mobile-web-app-status-bar-style': 'white', 'viewport': 'width=device-width,initial-scale=1,maximum-scale=1,user-scalable=0,viewport-fit=cover', 'mobile-web-app-capable': 'yes', 'og:url': 'https://twitter.com/whosbenfeldman', 'al:android:app_name': 'Twitter'}], 'collection': [{'name': 'Profile Tweets'}], 'cse_image': [{'src': 'https://pbs.twimg.com/profile_images/1295130901064478720/PztMlBbx_normal.jpg'}]}}
result: {'kind': 'customsearch#result', 'title': 'Marty Feldman (@eyemartyfeldman) / Twitter', 'htmlTitle': 'Marty <b>Feldman</b> (@eyemartyfeldman) / Twitter', 'link': 'https://twitter.com/eyemartyfeldman', 'displayLink': 'twitter.com', 'snippet': "This account is dedicated to '#eyEMarty - The newly discovered autobiography of a comic genius' and is curated by the Marty Feldman Foundation.", 'htmlSnippet': 'This account is dedicated to '#eyEMarty - The newly discovered autobiography of a comic genius' and is curated by the Marty <b>Feldman</b> Foundation.', 'cacheId': 'vm3b6Q79w4gJ', 'formattedUrl': 'https://twitter.com/eyemartyfeldman', 'htmlFormattedUrl': 'https://twitter.com/eyemarty<b>feldman</b>', 'pagemap': {'cse_thumbnail': [{'src': 'https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcTh_chxN1puhQipommSTICpCu0YeSpmv0lidro1bcsvPatmhFSWutjR', 'width': '48', 'height': '48'}], 'imageobject': [{'contenturl': 'https://pbs.twimg.com/media/CoAdvuHWAAYViDc.jpg', 'width': '1024', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CoAdvuHWAAYViDc?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CmfTw-jUEAAILus.jpg', 'width': '546', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CmfTw-jUEAAILus?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/ClHDs_fUsAA6e9X.png', 'width': '1024', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/ClHDs_fUsAA6e9X?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CkEMk_iVAAAspSI.jpg', 'width': '942', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CkEMk_iVAAAspSI?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/Cjf5tnwVEAA6US7.jpg', 'width': '1024', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/Cjf5tnwVEAA6US7?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/Ci7oHvxVAAE2cCW.jpg', 'width': '480', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/Ci7oHvxVAAE2cCW?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CiccezUUgAAJjrv.jpg', 'width': '770', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CiccezUUgAAJjrv?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/ChwiIVFUgAAkOha.jpg', 'width': '336', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/ChwiIVFUgAAkOha?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/ChPWRUfU0AA-E5e.jpg', 'width': '1988', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/ChPWRUfU0AA-E5e?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CgqbrvXUYAEV39b.jpg', 'width': '577', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CgqbrvXUYAEV39b?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CgHMIuGUIAAKPGN.jpg', 'width': '630', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CgHMIuGUIAAKPGN?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CfjsVvaUMAAw00p.jpg', 'width': '640', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CfjsVvaUMAAw00p?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/Ce_JHu4UsAAMyry.jpg', 'width': '882', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/Ce_JHu4UsAAMyry?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/Cegx1UaXIAE3lCG.jpg', 'width': '728', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/Cegx1UaXIAE3lCG?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/Cd3JQA8UAAEZRkS.jpg', 'width': '797', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/Cd3JQA8UAAEZRkS?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CdTWLsiUkAApfIo.jpg', 'width': '960', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CdTWLsiUkAApfIo?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CcveeDvUAAAa_ec.jpg', 'width': '404', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CcveeDvUAAAa_ec?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CcKkvxkUsAA3SLe.jpg', 'width': '1024', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CcKkvxkUsAA3SLe?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CbnTEUDUEAACsXV.jpg', 'width': '442', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CbnTEUDUEAACsXV?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CbDOS0vUsAAOf_2.jpg', 'width': '438', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CbDOS0vUsAAOf_2?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CaerzAHUMAAYG-4.jpg', 'width': '1024', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CaerzAHUMAAYG-4?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CZ6p6xbUUAAqoVp.jpg', 'width': '600', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CZ6p6xbUUAAqoVp?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CZhC2yOUAAAk3pW.jpg', 'width': '768', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CZhC2yOUAAAk3pW?format=jpg&name=thumb'}, {'contenturl': 'https://pbs.twimg.com/media/CZbV1W1VAAEoUYe.jpg', 'width': '284', 'caption': 'Image', 'thumbnailurl': 'https://pbs.twimg.com/media/CZbV1W1VAAEoUYe?format=jpg&name=thumb'}], 'person': [{'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '36941760', 'givenname': 'Tom Jamieson', 'additionalname': 'jamiesont'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}, {'identifier': '4085098574', 'givenname': 'Marty Feldman', 'additionalname': 'eyemartyfeldman'}], 'interactioncounter': [{'userinteractioncount': '41', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/756637444380897280/likes'}, {'userinteractioncount': '11', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/756637444380897280/retweets'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/756637444380897280/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/756637444380897280'}, {'userinteractioncount': '27', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/749800704089333761/likes'}, {'userinteractioncount': '4', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/749800704089333761/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/749800704089333761/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/749800704089333761'}, {'userinteractioncount': '21', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/743590595701047296/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/743590595701047296/retweets'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/743590595701047296/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/743590595701047296'}, {'userinteractioncount': '19', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/738885644965945344/likes'}, {'userinteractioncount': '6', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/738885644965945344/retweets'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/738885644965945344/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/738885644965945344'}, {'userinteractioncount': '6', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/737727371571253248/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/737727371571253248/retweets'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/737727371571253248/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/737727371571253248'}, {'userinteractioncount': '11', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/736331627324792832/likes'}, {'userinteractioncount': '5', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/736331627324792832/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/736331627324792832/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/736331627324792832'}, {'userinteractioncount': '5', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/733779010593935362/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/733779010593935362/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/733779010593935362/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/733779010593935362'}, {'userinteractioncount': '7', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/731584781125746688/likes'}, {'userinteractioncount': '4', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/731584781125746688/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/731584781125746688/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/731584781125746688'}, {'userinteractioncount': '7', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/728494767227609089/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/728494767227609089/retweets'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/728494767227609089/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/728494767227609089'}, {'userinteractioncount': '7', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/726159558733778944/likes'}, {'userinteractioncount': '4', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/726159558733778944/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/726159558733778944/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/726159558733778944'}, {'userinteractioncount': '6', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/723561867226931201/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/723561867226931201/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/723561867226931201/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/723561867226931201'}, {'userinteractioncount': '5', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/721081866158080000/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/721081866158080000/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/721081866158080000/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/721081866158080000'}, {'userinteractioncount': '10', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/718584000307015680/likes'}, {'userinteractioncount': '4', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/718584000307015680/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/718584000307015680/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/718584000307015680'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/716012001634291712/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/716012001634291712/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/716012001634291712/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/716012001634291712'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/713875334370697216/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/713875334370697216/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/713875334370697216/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/713875334370697216'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/710945594424975360/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/710945594424975360/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/710945594424975360/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/710945594424975360'}, {'userinteractioncount': '5', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/708426539038146560/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/708426539038146560/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/708426539038146560/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/708426539038146560'}, {'userinteractioncount': '4', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/705902375811166209/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/705902375811166209/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/705902375811166209/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/705902375811166209'}, {'userinteractioncount': '6', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/703305633735450625/likes'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/703305633735450625/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/703305633735450625/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/703305633735450625'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/700840082476027905/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/700840082476027905/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/700840082476027905/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/700840082476027905'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/700840080555032577/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/700840080555032577/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/700840080555032577/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/700840080555032577'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/700839770944106496/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/700839770944106496/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/700839770944106496/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/700839770944106496'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/700839766930169856/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/700839766930169856/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/700839766930169856/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/700839766930169856'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/700839753160269824/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/700839753160269824/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/700839753160269824/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/700839753160269824'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/700839643957301248/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/700839643957301248/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/700839643957301248/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/700839643957301248'}, {'userinteractioncount': '6', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/700823289241817088/likes'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/700823289241817088/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/700823289241817088/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/700823289241817088'}, {'userinteractioncount': '5', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/698284766257262592/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/698284766257262592/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/698284766257262592/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/698284766257262592'}, {'userinteractioncount': '7', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/695713561524379648/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/695713561524379648/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/695713561524379648/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/695713561524379648'}, {'userinteractioncount': '6', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/jamiesont/status/691608740605337600/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/jamiesont/status/691608740605337600/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/jamiesont/status/691608740605337600/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/jamiesont/status/691608740605337600'}, {'userinteractioncount': '11', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/693178221026631681/likes'}, {'userinteractioncount': '4', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/693178221026631681/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/693178221026631681/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/693178221026631681'}, {'userinteractioncount': '9', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/691377515164602369/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/691377515164602369/retweets'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/691377515164602369/retweets/with_comments'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/691377515164602369'}, {'userinteractioncount': '5', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/691376941421580289/likes'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/691376941421580289/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/691376941421580289/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/691376941421580289'}, {'userinteractioncount': '7', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/691376056398274560/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/691376056398274560/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/691376056398274560/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/691376056398274560'}, {'userinteractioncount': '16', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/691375633289474048/likes'}, {'userinteractioncount': '10', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/691375633289474048/retweets'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/691375633289474048/retweets/with_comments'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/691375633289474048'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/691375338203418624/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/691375338203418624/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/691375338203418624/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/691375338203418624'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/691373918850945024/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/691373918850945024/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/691373918850945024/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/691373918850945024'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/690974706132983809/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/690974706132983809/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/690974706132983809/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/690974706132983809'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/690694860903469057/likes'}, {'userinteractioncount': '1', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/690694860903469057/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/690694860903469057/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/690694860903469057'}, {'userinteractioncount': '2', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/690694855853522944/likes'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/690694855853522944/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/690694855853522944/retweets/with_comments'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/690694855853522944'}, {'userinteractioncount': '41', 'interactiontype': 'https://schema.org/LikeAction', 'name': 'Likes', 'url': 'https://twitter.com/eyemartyfeldman/status/690694607471038464/likes'}, {'userinteractioncount': '19', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Retweets', 'url': 'https://twitter.com/eyemartyfeldman/status/690694607471038464/retweets'}, {'userinteractioncount': '0', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Quotes', 'url': 'https://twitter.com/eyemartyfeldman/status/690694607471038464/retweets/with_comments'}, {'userinteractioncount': '3', 'interactiontype': 'https://schema.org/InteractAction', 'name': 'Replies', 'url': 'https://twitter.com/eyemartyfeldman/status/690694607471038464'}], 'metatags': [{'og:image': 'https://pbs.twimg.com/profile_images/666365065168195584/WObuGYmv_normal.jpg', 'theme-color': '#ffffff', 'og:type': 'profile', 'og:site_name': 'Twitter', 'al:ios:app_name': 'Twitter', 'apple-mobile-web-app-title': 'Twitter', 'og:title': 'Marty Feldman (@eyemartyfeldman) / Twitter', 'al:android:package': 'com.twitter.android', 'al:ios:url': 'twitter://user?screen_name=eyemartyfeldman', 'og:description': "This account is dedicated to '#eyEMarty - The newly discovered autobiography of a comic genius' and is curated by the Marty Feldman Foundation", 'al:ios:app_store_id': '333903271', 'facebook-domain-verification': 'x6sdcc8b5ju3bh8nbm59eswogvg6t1', 'al:android:url': 'twitter://user?screen_name=eyemartyfeldman', 'fb:app_id': '2231777543', 'apple-mobile-web-app-status-bar-style': 'white', 'viewport': 'width=device-width,initial-scale=1,maximum-scale=1,user-scalable=0,viewport-fit=cover', 'mobile-web-app-capable': 'yes', 'og:url': 'https://twitter.com/eyemartyfeldman', 'al:android:app_name': 'Twitter'}], 'videoobject': [{'duration': 'PT0H0M0S', 'embedurl': 'https://platform.twitter.com/embed/Tweet.html?dnt=false&embedId=twitter-widget-1&frame=false&hideCard=false&hideThread=false&lang=en&id=691375633289474048', 'contenturl': 'https://video.twimg.com/tweet_video/CZhCc3sUEAERqnU.mp4', 'uploaddate': '2016-01-24T21:42:50.000Z', 'name': "@eyemartyfeldman's video Tweet", 'description': 'Embedded video', 'caption': 'Embedded video', 'thumbnailurl': 'https://pbs.twimg.com/tweet_video_thumb/CZhCc3sUEAERqnU.png'}], 'collection': [{'name': 'Profile Tweets'}], 'creativework': [{'name': 'Expanded Tweet URLs', 'url': 'https://t.co/7yZSlQ1mjV'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/4QPwcCQS2k'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/XJosjf7mTl'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/mHUED1dbeX'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/CKQRNP4qkM'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/oVoexNsuE5'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/LJEZQBJmBy'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/pZtkFPDOPX'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/E9kunTnWlG'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/uXR0kNYYqP'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/egZ3z8dsZu'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/19nyqG9gKo'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/w83LeBEzgV'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/QQSpd67VPO'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/J53TR1IoyW'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/eLosq5DmFB'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/xqlQdXMslt'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/pQzikTeQsv'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/IvDB6OwqRb'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/gEu2YEvoTv'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/emzNtXT5sF'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/cxu5UlndCE'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/v9zl8locMP'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/D2xF6aapRM'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/BpatQ4JUTM'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/qlmLdZgrQs'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/Y67DX6YgPA'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/xhfEGrmsRd'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/Za5wbA2pPR'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/D59NN9wwiJ'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/u79Sk7X2jS'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/0IeyvN4ecG'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/5z16doKyR6'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/MZOnA5OLm4'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/LB9CdocceB'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/ayU3wzJtq7'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/U2l36tWvni'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/WsaesTSNAo'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/OyYE6heftB'}, {'name': 'Expanded Tweet URLs', 'url': 'https://t.co/AbFOtbmaGK'}], 'cse_image': [{'src': 'https://pbs.twimg.com/profile_images/666365065168195584/WObuGYmv_normal.jpg'}], 'socialmediaposting': [{'identifier': '756637444380897280', 'commentcount': '1', 'articlebody': 'The year was 1975… http://theofficialmartyfeldman.com/main/news/the-year-was-1975/…', 'position': '1', 'datecreated': '2016-07-22T23:49:59.000Z', 'datepublished': '2016-07-22T23:49:59.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/756637444380897280'}, {'identifier': '749800704089333761', 'commentcount': '0', 'articlebody': 'Absolutely Fabulous http://theofficialmartyfeldman.com/main/news/860/', 'position': '2', 'datecreated': '2016-07-04T03:03:13.000Z', 'datepublished': '2016-07-04T03:03:13.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/749800704089333761'}, {'identifier': '743590595701047296', 'commentcount': '0', 'articlebody': 'Yellowbeard Set http://theofficialmartyfeldman.com/main/news/yellowbeard-set/…', 'position': '3', 'datecreated': '2016-06-16T23:46:27.000Z', 'datepublished': '2016-06-16T23:46:27.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/743590595701047296'}, {'identifier': '738885644965945344', 'commentcount': '0', 'articlebody': 'Resurrected http://theofficialmartyfeldman.com/main/news/resurrected/…', 'position': '4', 'datecreated': '2016-06-04T00:10:40.000Z', 'datepublished': '2016-06-04T00:10:40.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/738885644965945344'}, {'identifier': '737727371571253248', 'commentcount': '0', 'articlebody': 'I just uploaded "It\'s Marty Resurrected part 1" to @Vimeo:', 'position': '5', 'datecreated': '2016-05-31T19:28:06.000Z', 'datepublished': '2016-05-31T19:28:06.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/737727371571253248'}, {'identifier': '736331627324792832', 'commentcount': '0', 'articlebody': 'Marty Doc http://theofficialmartyfeldman.com/main/news/marty-doc/…', 'position': '6', 'datecreated': '2016-05-27T23:01:54.000Z', 'datepublished': '2016-05-27T23:01:54.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/736331627324792832'}, {'identifier': '733779010593935362', 'commentcount': '1', 'articlebody': 'Flippin’ http://theofficialmartyfeldman.com/main/news/flippin/…', 'position': '7', 'datecreated': '2016-05-20T21:58:43.000Z', 'datepublished': '2016-05-20T21:58:43.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/733779010593935362'}, {'identifier': '731584781125746688', 'commentcount': '0', 'articlebody': 'Too Old to Die Young http://theofficialmartyfeldman.com/main/news/too-old-to-die-young/…', 'position': '8', 'datecreated': '2016-05-14T20:39:38.000Z', 'datepublished': '2016-05-14T20:39:38.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/731584781125746688'}, {'identifier': '728494767227609089', 'commentcount': '0', 'articlebody': 'One Pair of eYEs http://theofficialmartyfeldman.com/main/news/one-pair-of-eyes/…', 'position': '9', 'datecreated': '2016-05-06T08:01:01.000Z', 'datepublished': '2016-05-06T08:01:01.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/728494767227609089'}, {'identifier': '726159558733778944', 'commentcount': '0', 'articlebody': 'Marty’s Big Night Out! http://theofficialmartyfeldman.com/main/news/martys-big-night-out/…', 'position': '10', 'datecreated': '2016-04-29T21:21:44.000Z', 'datepublished': '2016-04-29T21:21:44.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/726159558733778944'}, {'identifier': '723561867226931201', 'commentcount': '0', 'articlebody': 'DeluxE http://theofficialmartyfeldman.com/main/news/deluxe/…', 'position': '11', 'datecreated': '2016-04-22T17:19:26.000Z', 'datepublished': '2016-04-22T17:19:26.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/723561867226931201'}, {'identifier': '721081866158080000', 'commentcount': '0', 'articlebody': 'Eric on Marty http://theofficialmartyfeldman.com/main/news/eric-on-marty/…', 'position': '12', 'datecreated': '2016-04-15T21:04:48.000Z', 'datepublished': '2016-04-15T21:04:48.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/721081866158080000'}, {'identifier': '718584000307015680', 'commentcount': '0', 'articlebody': 'Martin and Feldman http://theofficialmartyfeldman.com/main/news/martin-and-feldman/…', 'position': '13', 'datecreated': '2016-04-08T23:39:10.000Z', 'datepublished': '2016-04-08T23:39:10.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/718584000307015680'}, {'identifier': '716012001634291712', 'commentcount': '0', 'articlebody': 'London 1970 http://theofficialmartyfeldman.com/main/news/london-1970/…', 'position': '14', 'datecreated': '2016-04-01T21:18:58.000Z', 'datepublished': '2016-04-01T21:18:58.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/716012001634291712'}, {'identifier': '713875334370697216', 'commentcount': '0', 'articlebody': 'Sex with a Smile http://theofficialmartyfeldman.com/main/news/sex-with-a-smile/…', 'position': '15', 'datecreated': '2016-03-26T23:48:37.000Z', 'datepublished': '2016-03-26T23:48:37.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/713875334370697216'}, {'identifier': '710945594424975360', 'commentcount': '0', 'articlebody': 'Friday’s with Marty http://theofficialmartyfeldman.com/main/news/fridays-with-marty/…', 'position': '16', 'datecreated': '2016-03-18T21:46:53.000Z', 'datepublished': '2016-03-18T21:46:53.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/710945594424975360'}, {'identifier': '708426539038146560', 'commentcount': '0', 'articlebody': 'Lauretta http://theofficialmartyfeldman.com/main/news/lauretta/…', 'position': '17', 'datecreated': '2016-03-11T22:57:03.000Z', 'datepublished': '2016-03-11T22:57:03.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/708426539038146560'}, {'identifier': '705902375811166209', 'commentcount': '0', 'articlebody': 'Marty TV Shows http://theofficialmartyfeldman.com/main/news/marty-tv-shows/…', 'position': '18', 'datecreated': '2016-03-04T23:46:56.000Z', 'datepublished': '2016-03-04T23:46:56.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/705902375811166209'}, {'identifier': '703305633735450625', 'commentcount': '1', 'articlebody': 'Marty Documentary http://theofficialmartyfeldman.com/main/news/marty-documentary/…', 'position': '19', 'datecreated': '2016-02-26T19:48:24.000Z', 'datepublished': '2016-02-26T19:48:24.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/703305633735450625'}, {'identifier': '700840082476027905', 'commentcount': '1', 'articlebody': 'I just uploaded "A Speight of Marty Back Together Again part 3" to @Vimeo:', 'position': '20', 'datecreated': '2016-02-20T00:31:11.000Z', 'datepublished': '2016-02-20T00:31:11.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/700840082476027905'}, {'identifier': '700840080555032577', 'commentcount': '1', 'articlebody': 'I just uploaded "A Speight of Marty Back Together Again part 1" to @Vimeo:', 'position': '21', 'datecreated': '2016-02-20T00:31:10.000Z', 'datepublished': '2016-02-20T00:31:10.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/700840080555032577'}, {'identifier': '700839770944106496', 'commentcount': '0', 'articlebody': 'I just uploaded "Marty Amok part 2" to @Vimeo:', 'position': '22', 'datecreated': '2016-02-20T00:29:57.000Z', 'datepublished': '2016-02-20T00:29:57.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/700839770944106496'}, {'identifier': '700839766930169856', 'commentcount': '0', 'articlebody': 'I just uploaded "Marty Amok part 4" to @Vimeo:', 'position': '23', 'datecreated': '2016-02-20T00:29:56.000Z', 'datepublished': '2016-02-20T00:29:56.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/700839766930169856'}, {'identifier': '700839753160269824', 'commentcount': '0', 'articlebody': 'I just uploaded "Marty Amok part 3" to @Vimeo:', 'position': '24', 'datecreated': '2016-02-20T00:29:52.000Z', 'datepublished': '2016-02-20T00:29:52.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/700839753160269824'}, {'identifier': '700839643957301248', 'commentcount': '0', 'articlebody': 'I just uploaded "Marty Amok part 1" to @Vimeo:', 'position': '25', 'datecreated': '2016-02-20T00:29:26.000Z', 'datepublished': '2016-02-20T00:29:26.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/700839643957301248'}, {'identifier': '700823289241817088', 'commentcount': '0', 'articlebody': 'eyE Muppeteer! http://theofficialmartyfeldman.com/main/news/eye-muppeteer/…', 'position': '26', 'datecreated': '2016-02-19T23:24:27.000Z', 'datepublished': '2016-02-19T23:24:27.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/700823289241817088'}, {'identifier': '698284766257262592', 'commentcount': '0', 'articlebody': 'The Bed Sitting Room http://theofficialmartyfeldman.com/main/news/the-bed-sitting-room/…', 'position': '27', 'datecreated': '2016-02-12T23:17:16.000Z', 'datepublished': '2016-02-12T23:17:16.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/698284766257262592'}, {'identifier': '695713561524379648', 'commentcount': '0', 'articlebody': 'Marty and the Cartoonist http://theofficialmartyfeldman.com/main/news/marty-and-the-cartoonist/…', 'position': '28', 'datecreated': '2016-02-05T21:00:13.000Z', 'datepublished': '2016-02-05T21:00:13.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/695713561524379648'}, {'identifier': '693184533512892416', 'position': '29', 'datecreated': '2016-01-29T21:30:46.000Z', 'datepublished': '2016-01-29T21:30:46.000Z'}, {'identifier': '691608740605337600', 'commentcount': '0', 'articlebody': "Was asked if I'm a Marty Feldman fan - one of my favourite sketches https://youtu.be/_epStsDeIdc via @YouTube", 'datecreated': '2016-01-25T13:09:07.000Z', 'datepublished': '2016-01-25T13:09:07.000Z', 'url': 'https://twitter.com/jamiesont/status/691608740605337600'}, {'identifier': '693178221026631681', 'commentcount': '1', 'articlebody': '‘Four, left, I mean right, FUCK!’ http://theofficialmartyfeldman.com/main/news/four-left-i-mean-right-fuck/…', 'position': '30', 'datecreated': '2016-01-29T21:05:41.000Z', 'datepublished': '2016-01-29T21:05:41.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/693178221026631681'}, {'identifier': '691377515164602369', 'commentcount': '1', 'articlebody': 'Hilarious outtakes with Madeline Kahn and Marty Feldman in "Young Frankenstein" (1974)', 'position': '31', 'datecreated': '2016-01-24T21:50:19.000Z', 'datepublished': '2016-01-24T21:50:19.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/691377515164602369'}, {'identifier': '691376941421580289', 'commentcount': '0', 'articlebody': 'Young Frankenstein: Working with Marty Feldman http://flip.it/p8irA @MelBrooks', 'position': '32', 'datecreated': '2016-01-24T21:48:02.000Z', 'datepublished': '2016-01-24T21:48:02.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/691376941421580289'}, {'identifier': '691376056398274560', 'commentcount': '0', 'articlebody': 'RT: @bnokj', 'position': '33', 'datecreated': '2016-01-24T21:44:31.000Z', 'datepublished': '2016-01-24T21:44:31.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/691376056398274560'}, {'identifier': '691375633289474048', 'commentcount': '3', 'position': '34', 'datecreated': '2016-01-24T21:42:50.000Z', 'datepublished': '2016-01-24T21:42:50.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/691375633289474048'}, {'identifier': '691375338203418624', 'commentcount': '0', 'articlebody': 'RT @peterhayes123: Marty Feldman: much missed.', 'position': '35', 'datecreated': '2016-01-24T21:41:40.000Z', 'datepublished': '2016-01-24T21:41:40.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/691375338203418624'}, {'identifier': '691373918850945024', 'commentcount': '0', 'articlebody': 'RT @bnokj: This Marty Feldman poem was too good not to share. Really enjoying his autobiography. A sweet, funny man.', 'position': '36', 'datecreated': '2016-01-24T21:36:02.000Z', 'datepublished': '2016-01-24T21:36:02.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/691373918850945024'}, {'identifier': '690974706132983809', 'commentcount': '0', 'articlebody': 'Marty Meets Tom http://theofficialmartyfeldman.com/main/news/marty-meets-tom/…', 'position': '37', 'datecreated': '2016-01-23T19:09:42.000Z', 'datepublished': '2016-01-23T19:09:42.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/690974706132983809'}, {'identifier': '690694860903469057', 'commentcount': '0', 'articlebody': 'I just uploaded "Marty Feldman - Vatican Rag - Tom Lehrer" to @Vimeo:', 'position': '38', 'datecreated': '2016-01-23T00:37:41.000Z', 'datepublished': '2016-01-23T00:37:41.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/690694860903469057'}, {'identifier': '690694855853522944', 'commentcount': '0', 'articlebody': 'I just uploaded "A Speight of Marty Back Together Again part 1" to @Vimeo:', 'position': '39', 'datecreated': '2016-01-23T00:37:40.000Z', 'datepublished': '2016-01-23T00:37:40.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/690694855853522944'}, {'identifier': '690694607471038464', 'commentcount': '3', 'articlebody': 'I just uploaded "Marty Feldman - National Brotherhood Week - Tom Lehrer" to @Vimeo:', 'position': '40', 'datecreated': '2016-01-23T00:36:41.000Z', 'datepublished': '2016-01-23T00:36:41.000Z', 'url': 'https://twitter.com/eyemartyfeldman/status/690694607471038464'}]}}





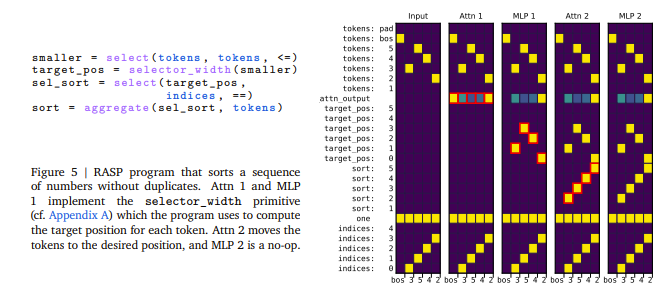




You must be logged in to post a comment.