7:00 – 4:00 VTX
- So I ask myself, is there some kind of public repository of crawled data? Why, of course there is! Common Crawl. So there is a way of getting the deep link structure for a given site without crawling it. That could give me the ability to determine how ‘bubbly’ a site is. I’m thinking there may be a ratio of bidirectional to unidirectional links (per site?) that could help here.
- More lit review and integration.
- Making diagrams for the Sprint review today
- Overview
- The purpose of this effort is to provide a capability for the system to do more sophisticated queries that do several things
- Allow the user to emphasize/de-emphasize words or phrases that relate to the particular search and to do this interactively based on linguistic analysis of the returned text.
- Get user value judgments on the information provided based on the link results reordering
- Use this to feed back to the selection criteria for provider Flags.
- This work leans on the paper PageRank without Hyperlinks if you want more background/depth.
- Eiphcone 129 – Design database table schema.
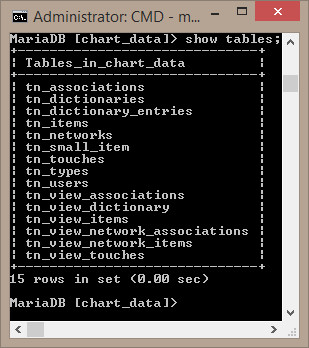
- Took my existing MySql db schema and migrated it to Java Persistent Entities. Basically this meant taking a db that was designed for precompiled query access and retrieval (direct data access for adding data, views for retrieval) and restructuring it. So we go from:
- to

- The classes are annotated POJOs in a simple hierarchy. The classes that have ‘Base’ in their names I expect to be extended, though there may be enough capability here. GuidBase has some additional capability to make adding data to one class that has a data relation to another class gets filled out properly in both:
 Since multiple dictionary entries can be present in multiple corpora BaseDictionaryEntry and Corpus both have a <Set> of BaseEntryContext that connects the corpora and entries with additional information that might be useful, such as counts.
Since multiple dictionary entries can be present in multiple corpora BaseDictionaryEntry and Corpus both have a <Set> of BaseEntryContext that connects the corpora and entries with additional information that might be useful, such as counts.
- This manifests itself in the database as the following:
 It’s not the prettiest drawing, but I can’t get IntelliJ to draw any better. You can see that the tables match directly to the classes. I used the InheritanceType.JOINED strategy since Jeremy was concerned about wasted space in the tables.
It’s not the prettiest drawing, but I can’t get IntelliJ to draw any better. You can see that the tables match directly to the classes. I used the InheritanceType.JOINED strategy since Jeremy was concerned about wasted space in the tables.
- The next steps will be to start to create test cases that allow for tuning and testing of this setup at different data scales.
- Eiphcone 132 – Document current progress on relationship/taxonomy design & existing threat model
- Currently, a threat is extracted by comparing a set of known entities to surrounding text for keywords. In the model shown above, practitioners would exist in a network that includes items like the practice, attending hospitals, legal representation, etc. Because of this relationship, flags could be extended to the other members of the network. If a near neighbor in this network has a Flag attached, it will weight the surrounding edges and influence the practitioner. So if one doctor in a practice is convicted of malpractice, then other doctors in the practice will get lower scores.
- The dictionary and corpus can interact as their own network to determine the amount of wight that is given to a particular score. For example, words in a dictionary that are used to extract data from a legal corpus may have more weight than a social media corpus.
- Eiphcone 134 – Design/document NER processing in relation to future taxonomy
- I compiled and ran the NER codebase and also walked though the Stanford NLP documentation. The current NER system looks to be somewhat basic, but solid and usable. Using it to populate the dictionaries and annotating the corpus appears to be straightforward addition of the capabilities already present in the Stanford API.
- Demo – I don’t really have a demo, unless people want to see some tests compile and run. To save the time, I have this exiting printout that shows the return of dynamically created data:
[EL Info]: 2016-01-12 14:09:40.481--ServerSession(1842102517)--EclipseLink, version: Eclipse Persistence Services - 2.6.1.v20150916-55dc7c3
[EL Info]: connection: 2016-01-12 14:09:40.825--ServerSession(1842102517)--/file:/C:/Development/Sandboxes/JPA_2_1/out/production/JPA_2_1/_NetworkService login successful
Users
firstName(firstname_0), lastName(lastname_0), login(login_0), networks( network_0)
firstName(firstname_1), lastName(lastname_1), login(login_1), networks( network_4)
firstName(firstname_2), lastName(lastname_2), login(login_2), networks( network_3)
firstName(firstname_3), lastName(lastname_3), login(login_3), networks( network_1 network_2)
firstName(firstname_4), lastName(lastname_4), login(login_4), networks()
Networks
name(network_0), owner(login_0), type(WAMPETER), archived(false), public(false), editable(true)
[92]: name(DataNode_6_to_BaseNode_8), guid(network_0_DataNode_6_to_BaseNode_8), weight(0.5708945393562317), type(IDENTITY), network(network_0)
Source: [86]: name('DataNode_6'), type(ENTITIES), annotation('annotation_6'), guid('50836752-221a-4095-b059-2055230d59db'), double(18.84955592153876), int(6), text('text_6')
Target: [88]: name('BaseNode_8'), type(COMPUTED), annotation('annotation_8'), guid('77250282-3b5e-416e-a469-bbade10c5e88')
[91]: name(BaseNode_5_to_UrlNode_4), guid(network_0_BaseNode_5_to_UrlNode_4), weight(0.3703539967536926), type(COMPUTED), network(network_0)
Source: [85]: name('BaseNode_5'), type(RATING), annotation('annotation_5'), guid('bf28f478-626d-4e8f-9809-b4a37f2ad504')
Target: [84]: name('UrlNode_4'), type(IDENTITY), annotation('annotation_4'), guid('bffe13ae-bb70-46a6-b1b4-9f58cadad04e'), Date(2016-01-11 11:51Z), html(some text), text('some text'), link('http://source.com/source.html'), image('http://source.com/soureImage.jpg')
[98]: name(BaseNode_5_to_UrlNode_1), guid(network_0_BaseNode_5_to_UrlNode_1), weight(0.4556456208229065), type(ENTITIES), network(network_0)
Source: [85]: name('BaseNode_5'), type(RATING), annotation('annotation_5'), guid('bf28f478-626d-4e8f-9809-b4a37f2ad504')
Target: [81]: name('UrlNode_1'), type(UNKNOWN), annotation('annotation_1'), guid('f9693110-6b5b-4888-9585-99b97062a4e4'), Date(2016-01-11 11:51Z), html(some text), text('some text'), link('http://source.com/source.html'), image('http://source.com/soureImage.jpg')
name(network_1), owner(login_3), type(WAMPETER), archived(false), public(false), editable(true)
[96]: name(BaseNode_2_to_UrlNode_1), guid(network_1_BaseNode_2_to_UrlNode_1), weight(0.5733484625816345), type(URL), network(network_1)
Source: [82]: name('BaseNode_2'), type(ITEM), annotation('annotation_2'), guid('c5867557-2ac3-4337-be34-da9da0c7e25d')
Target: [81]: name('UrlNode_1'), type(UNKNOWN), annotation('annotation_1'), guid('f9693110-6b5b-4888-9585-99b97062a4e4'), Date(2016-01-11 11:51Z), html(some text), text('some text'), link('http://source.com/source.html'), image('http://source.com/soureImage.jpg')
[95]: name(DataNode_0_to_UrlNode_7), guid(network_1_DataNode_0_to_UrlNode_7), weight(0.85154128074646), type(MERGE), network(network_1)
Source: [80]: name('DataNode_0'), type(USER), annotation('annotation_0'), guid('e9b7fa0a-37f1-41bd-a2c1-599841d1507a'), double(0.0), int(0), text('text_0')
Target: [87]: name('UrlNode_7'), type(QUERY), annotation('annotation_7'), guid('b9351194-d10e-4f6a-b997-b84c61344fcf'), Date(2016-01-11 11:51Z), html(some text), text('some text'), link('http://source.com/source.html'), image('http://source.com/soureImage.jpg')
[94]: name(DataNode_9_to_BaseNode_5), guid(network_1_DataNode_9_to_BaseNode_5), weight(0.72845458984375), type(KEYWORDS), network(network_1)
Source: [89]: name('DataNode_9'), type(USER), annotation('annotation_9'), guid('5bdb67de-5319-42db-916e-c4050dc682dd'), double(28.274333882308138), int(9), text('text_9')
Target: [85]: name('BaseNode_5'), type(RATING), annotation('annotation_5'), guid('bf28f478-626d-4e8f-9809-b4a37f2ad504')
name(network_2), owner(login_3), type(EXPLICIT), archived(false), public(false), editable(true)
[90]: name(BaseNode_8_to_UrlNode_7), guid(network_2_BaseNode_8_to_UrlNode_7), weight(0.2619180679321289), type(WAMPETER), network(network_2)
Source: [88]: name('BaseNode_8'), type(COMPUTED), annotation('annotation_8'), guid('77250282-3b5e-416e-a469-bbade10c5e88')
Target: [87]: name('UrlNode_7'), type(QUERY), annotation('annotation_7'), guid('b9351194-d10e-4f6a-b997-b84c61344fcf'), Date(2016-01-11 11:51Z), html(some text), text('some text'), link('http://source.com/source.html'), image('http://source.com/soureImage.jpg')
name(network_3), owner(login_2), type(EXPLICIT), archived(false), public(false), editable(true)
[93]: name(UrlNode_4_to_DataNode_3), guid(network_3_UrlNode_4_to_DataNode_3), weight(0.7689594030380249), type(ITEM), network(network_3)
Source: [84]: name('UrlNode_4'), type(IDENTITY), annotation('annotation_4'), guid('bffe13ae-bb70-46a6-b1b4-9f58cadad04e'), Date(2016-01-11 11:51Z), html(some text), text('some text'), link('http://source.com/source.html'), image('http://source.com/soureImage.jpg')
Target: [83]: name('DataNode_3'), type(UNKNOWN), annotation('annotation_3'), guid('e7565935-6429-451f-b7f4-cc2d612ca3fd'), double(9.42477796076938), int(3), text('text_3')
[97]: name(DataNode_3_to_DataNode_0), guid(network_3_DataNode_3_to_DataNode_0), weight(0.5808262825012207), type(URL), network(network_3)
Source: [83]: name('DataNode_3'), type(UNKNOWN), annotation('annotation_3'), guid('e7565935-6429-451f-b7f4-cc2d612ca3fd'), double(9.42477796076938), int(3), text('text_3')
Target: [80]: name('DataNode_0'), type(USER), annotation('annotation_0'), guid('e9b7fa0a-37f1-41bd-a2c1-599841d1507a'), double(0.0), int(0), text('text_0')
name(network_4), owner(login_1), type(ITEM), archived(false), public(false), editable(true)
[99]: name(UrlNode_4_to_UrlNode_7), guid(network_4_UrlNode_4_to_UrlNode_7), weight(0.48601675033569336), type(WAMPETER), network(network_4)
Source: [84]: name('UrlNode_4'), type(IDENTITY), annotation('annotation_4'), guid('bffe13ae-bb70-46a6-b1b4-9f58cadad04e'), Date(2016-01-11 11:51Z), html(some text), text('some text'), link('http://source.com/source.html'), image('http://source.com/soureImage.jpg')
Target: [87]: name('UrlNode_7'), type(QUERY), annotation('annotation_7'), guid('b9351194-d10e-4f6a-b997-b84c61344fcf'), Date(2016-01-11 11:51Z), html(some text), text('some text'), link('http://source.com/source.html'), image('http://source.com/soureImage.jpg')
Dictionaries
[30]: name(dictionary_0), guid(943ea8b6-6def-48ea-8b0f-a4e52e53954f), Owner(login_0), archived(false), public(false), editable(true)
Entry = word_11
Parent = word_10
word_11 has 790 occurances in corpora0_chapter_1
Entry = word_14
word_14 has 4459 occurances in corpora1_chapter_2
Entry = word_1
Parent = word_0
word_1 has 3490 occurances in corpora1_chapter_2
Entry = word_10
word_10 has 3009 occurances in corpora3_chapter_4
Entry = word_4
word_4 has 2681 occurances in corpora3_chapter_4
Entry = word_5
Parent = word_4
word_5 has 5877 occurances in corpora1_chapter_2
[31]: name(dictionary_1), guid(c7b62a4b-b21a-4ebe-a939-0a71a891a3f9), Owner(login_0), archived(false), public(false), editable(true)
Entry = word_3
Parent = word_2
word_3 has 4220 occurances in corpora0_chapter_1
Entry = word_6
word_6 has 4852 occurances in corpora2_chapter_3
Entry = word_17
Parent = word_16
word_17 has 8394 occurances in corpora2_chapter_3
Entry = word_2
word_2 has 1218 occurances in corpora3_chapter_4
Entry = word_19
Parent = word_18
word_19 has 8921 occurances in corpora2_chapter_3
Entry = word_8
word_8 has 4399 occurances in corpora3_chapter_4
Corpora
[27]: name(corpora1_chapter_2), guid(08803d93-deeb-4699-bdb2-ffa9f635c373), totalWords(1801), importer(login_1), url(http://americanliterature.com/author/herman-melville/book/moby-dick-or-the-whale/chapter-2-the-carpet-bag)
word_15 has 5338 occurances in corpora1_chapter_2
word_13 has 2181 occurances in corpora1_chapter_2
word_14 has 4459 occurances in corpora1_chapter_2
word_1 has 3490 occurances in corpora1_chapter_2
word_5 has 5877 occurances in corpora1_chapter_2
word_16 has 2625 occurances in corpora1_chapter_2
[EL Info]: connection: 2016-01-12 14:09:41.116--ServerSession(1842102517)--/file:/C:/Development/Sandboxes/JPA_2_1/out/production/JPA_2_1/_NetworkService logout successful
- Sprint review delayed. Tomorrow
- Filling in some knowledge holes in JPA. Finished Chapter 4.
- Tried getting enumerated types to work. No luck…?





You must be logged in to post a comment.