7:00 – 4:00 VTX
- Today’s shower thought is to compare the variance of the difference of two (unitized) rank matrices. The maximum difference would be (matrix size), so we do have a scale. If we assume a binomial distribution (there are many ways to be slightly different, only two ways to be completely different), then we can use a binomial (one tailed?) distribution centered on zero and ending at (matrix size). That should mean that I can see how far one item is from the other? But it will be withing the context of a larger distribution (all zeros vs all ones)…
- Before going down that rabbit hole, I decided to use the bootstrap method just to see if the concept works. It looks mostly good.
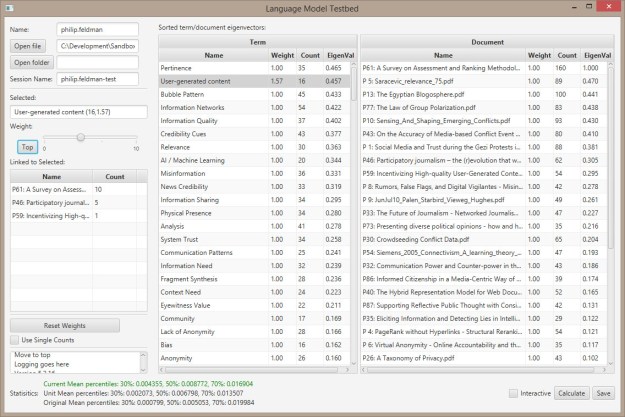
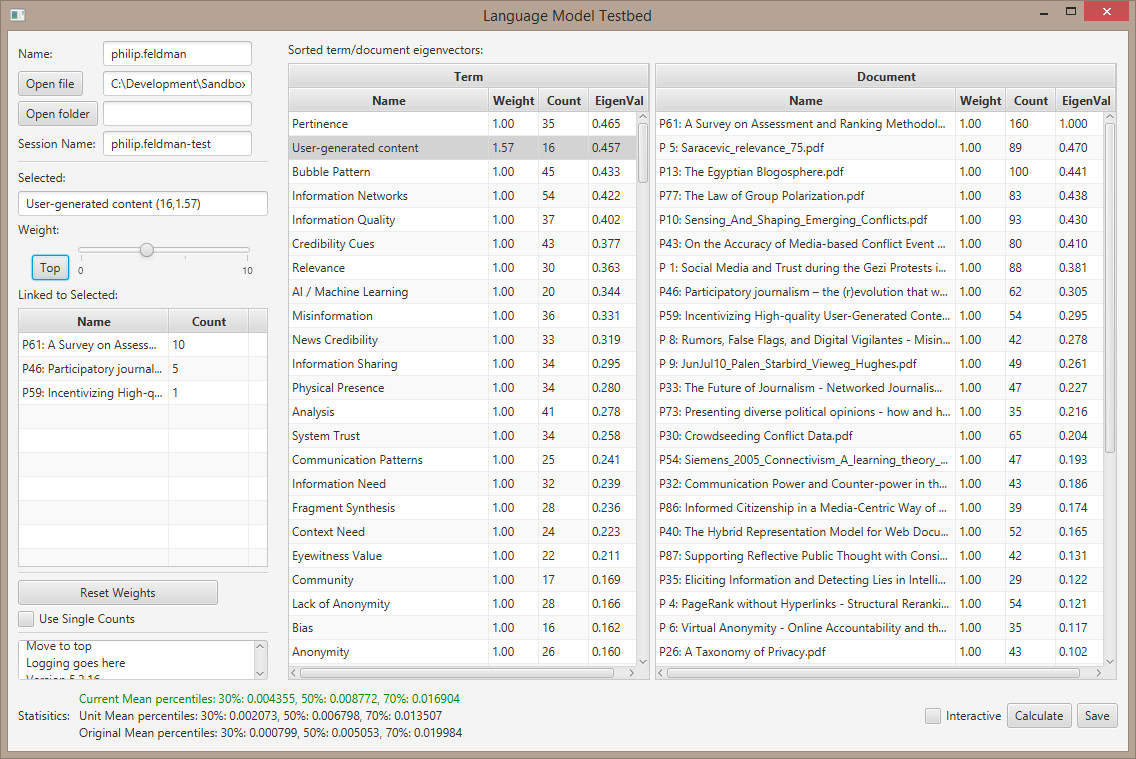
- Verified that scaling a low-ranked item (ACLED) by 10 has less impact than scaling the highest ranking item (P61) by 1.28.
- Set the stats text to red if it’s outside 1 SD and green if it’s within.
- I think the terms can be played around with more because the top one (Pertinence) gets ranked at .436, while P61 has a rank of 1.
- There are some weird issues with the way the matrix recalculates. Some states are statistically similar to others. I think I can do something with the thoughts above, but later.
- There seems to be a bug calculating the current mean when compared to the unit mean. It may be that the values are so small? It’s occasional….
- Got the ‘top’ button working.
- And that’s it for the week…
Oh yeah – Everything You Ever Wanted To Know About Motorcycle Safety Gear






You must be logged in to post a comment.