Quotebank is a dataset of 178 million unique, speaker-attributed quotations that were extracted from 196 million English news articles crawled from over 377 thousand web domains between August 2008 and April 2020. The quotations were extracted and attributed using Quobert, a distantly and minimally supervised end-to-end, language-agnostic framework for quotation attribution.
Stanford Cable TV News Analyzer The Stanford Cable TV Analyzer enables you to write queries that compute the amount of time people appear and the amount of time words are heard in cable TV news. In this tutorial we will go over the basics of how to use the tool to write simple queries.
GPT Agents
- Finished experiments and generated spreadsheets.
- Uploading everything to DropBox
- 3:00 Meeting
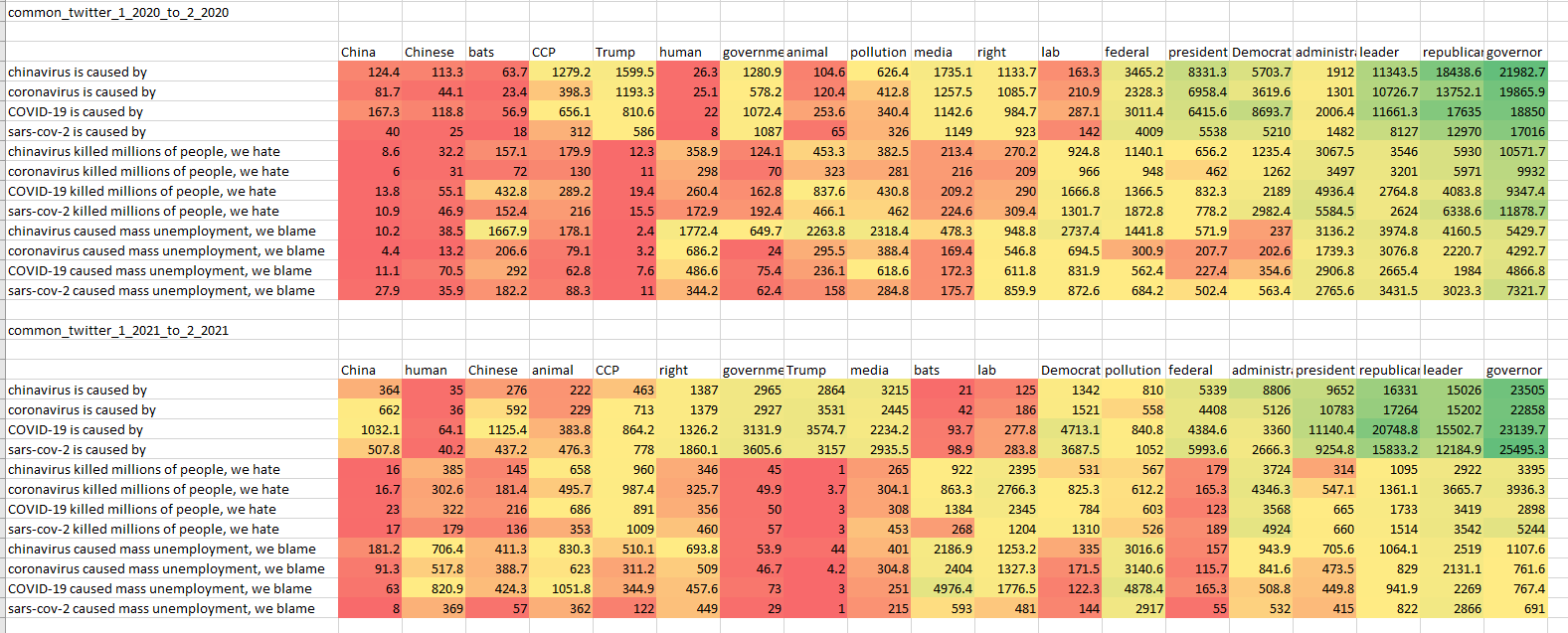
- Create datasets from tweets that have [‘%kung flu%’, ‘%kungflu%’, ‘%china virus%’, ‘%chinavirus%’, ‘%coronavirus%’, ‘%covid%’, ‘%sars-cov-2%’] and train models from these. The idea is to examine how this type of polarized training can influence the response of the model. Related work on Microsoft’s Tay
- Create a meta-sheet for all the spreadsheet summaries
- Rather than look at rankings, go back to the cumulative stats on multiple runs with top K set to the range of ranks that we want to look at, then take a look at the first n words. This addresses the token problem
SBIR
- Set up proxy (2:00)?
- Write up curves embedding code
- Start on simplest possible autoregressing Transformer using curve data
- Started on the PyTorch Quickstart. Everything is installed properly and Cuda is visible







You must be logged in to post a comment.