Had a wild dream last night. It began with Prince and I talking motorcycles, though I have to say that Prince looked more like Little Richard. There was a nice red motorcycle too, with spinning parts on the motor that don’t really make much sense now when I think about it.
At some point later, I was walking down a rural road and into a church(?). There was some kind christening-type thing going on, but it involved surgically implanting a line between the pelvis and the shoulder so that the child would grow up visibly stunted. This was presented as a price paid by the child for the parents belonging to the wrong group. That way, the group could always be recognized, and the individuals would be in a constant level of pain. My sense was that the original intent was that this was originally done so that the child would grow to reject the group so that its children wouldn’t have the procedure. But instead it had become a ritualized tradition and insisted on by the parents. Maybe a bit like foot binding?
Book
GPT-Agents
- Need to see if I can do Z-tests in Excel – you can (tutorial)!
- Had to add the American data
- Finished correlation, t-test, and z-test
SBIRs
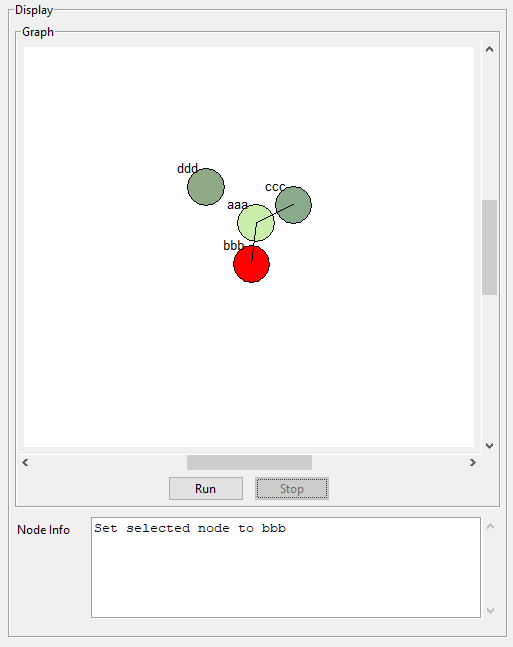
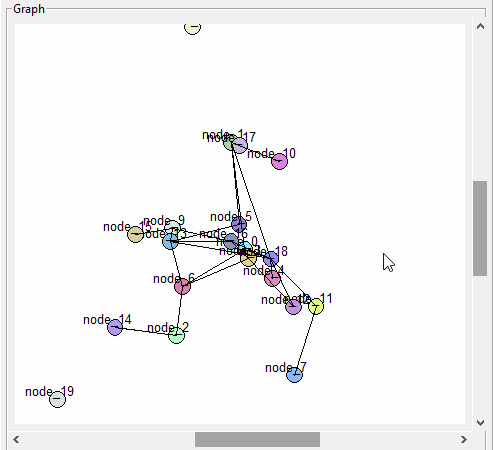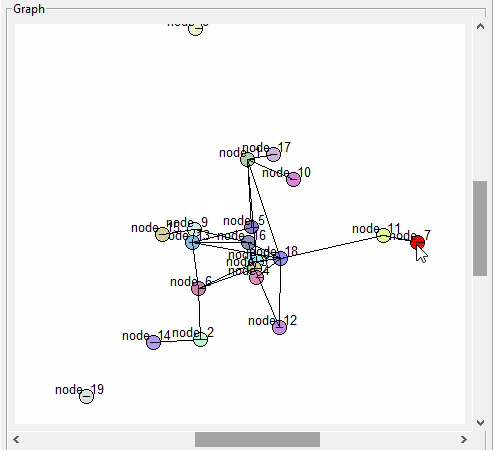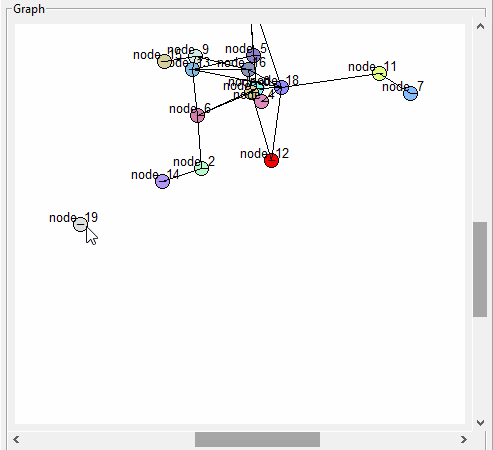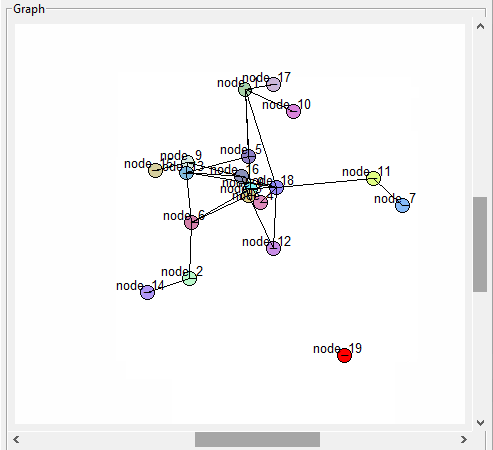
- still working on the logic for setting parent group and selected node/topic. There is some kind of problem with callbacks on the tk.Text widget. I can fix all my bugs by turning off all the Text callbacks. It may be because I create a callback for an in-class method that in turn calls an optional method that is passed into the class. Tomorrow I’ll try binding directly and see if that fixes things, otherwise proceed with only the select callback in the raw text












You must be logged in to post a comment.