
Chase Dispute team 9:00 – 9:00 1 888 489 8452
Just Landscaping: (443) 251-2188
BB Infinite: 866.865.3335
Societies change their minds faster than people do

GPT Agents
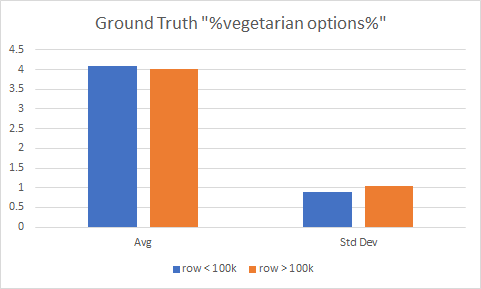
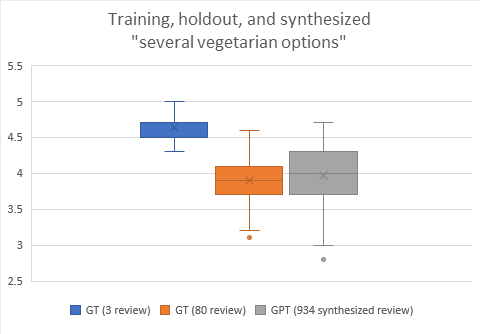
- Spreadsheets for vegetarian 100k GT vs GT vs synth. Everything is good except for ‘no vegetarian options’ It’s the only options that does not appear in the first 100k rows. Going to try some longer prompts to see if I can nudge the model in a better direction. Do that at lunch
- Hmmm. I can’t seem to produce a negative star distribution:

- Meeting with Andreea? Yup. Good chat
SBIRs
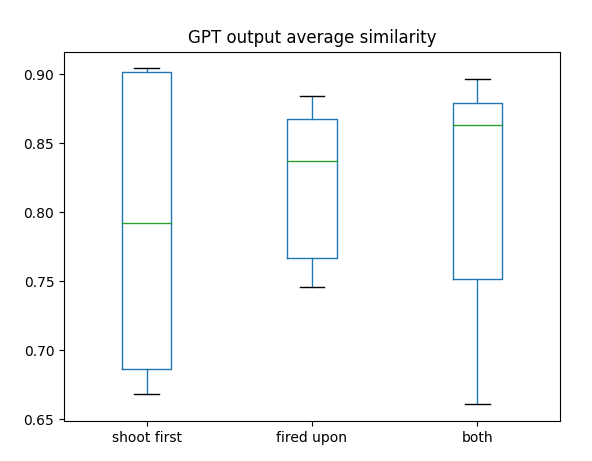
- Integrate text similarity into popup widget












You must be logged in to post a comment.