Some grist for the AI Ethics Corpora:
- Explanations Can Reduce Overreliance on AI Systems During Decision-Making
- The upshot here is that explanations for hard things are what users need. No one (almost) needs an explanation that 2+2=5 is incorrect (disregarding the incompleteness theorem and all that). Something more complex could require a lot of explanation, probably with a strong interactive component. For our work, the user would be decoupled from the “fact checker” that is trained in the domain of the AI and can recognize when it is struggling and likely to be wrong, and can switch to other models (like using a closed form equation solver for the hard problem above)
SBIRs
- Finish peeling out embedding panel – done, I think?
- Started on ContextExplorer
GPT Agents
- 2:30 NIST meeting
- 4:00 Meeting
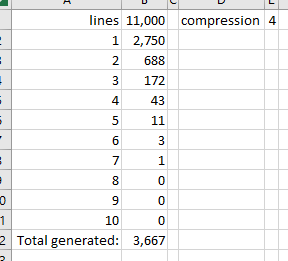
The context-based queries work really well. Here’s the full process, with question, answer, summaries and supporting text:
OpenAIEmbeddings.load_project_summary_text(): pulling text for 'moby-dick'
Processing 925 lines
Done
creating context
Question: [Why is Ahab obsessed with Mobey-Dick?]
submitting question
Answer:
Ahab is obsessed with Moby Dick because he believes that killing the White Whale will bring him revenge for the physical and emotional wounds he has suffered.
Supporting top 5 text:
Dist = 0.108 Summary: Ahab is obsessed with the idea of finding Moby Dick, believing that his snow-white brow and hump would make him unmistakable, and he endures trances of torments in his pursuit of revengeful desire.
line 4077: So that Monsoons, Pampas, Nor’-Westers, Harmattans, Trades; any wind but the Levanter and Simoon, might blow Moby Dick into the devious zig-zag world-circle of the Pequod’s circumnavigating wake
line 4078: But granting all this; yet, regarded discreetly and coolly, seems it not but a mad idea, this; that in the broad boundless ocean, one solitary whale, even if encountered, should be thought capable of individual recognition from his hunter, even as a white-bearded Mufti in the thronged thoroughfares of Constantinople
line 4079: For the peculiar snow-white brow of Moby Dick, and his snow-white hump, could not but be unmistakable
line 4080: And have I not tallied the whale, Ahab would mutter to himself, as after poring over his charts till long after midnight he would throw himself back in reveries—tallied him, and shall he escape
line 4081: His broad fins are bored, and scalloped out like a lost sheep’s ear
line 4082: And here, his mad mind would run on in a breathless race; till a weariness and faintness of pondering came over him; and in the open air of the deck he would seek to recover his strength
line 4083: what trances of torments does that man endure who is consumed with one unachieved revengeful desire
line 4084: He sleeps with clenched hands; and wakes with his own bloody nails in his palms
Dist = 0.132 Summary: Ahab was driven by his passion to capture Moby Dick, but he was also influenced by other motives, such as the possibility that killing more whales would increase the chances of encountering the White Whale, and the need to use tools and men to accomplish his goal.
line 4220: Though, consumed with the hot fire of his purpose, Ahab in all his thoughts and actions ever had in view the ultimate capture of Moby Dick; though he seemed ready to sacrifice all mortal interests to that one passion; nevertheless it may have been that he was by nature and long habituation far too wedded to a fiery whaleman’s ways, altogether to abandon the collateral prosecution of the voyage
line 4221: Or at least if this were otherwise, there were not wanting other motives much more influential with him
line 4222: It would be refining too much, perhaps, even considering his monomania, to hint that his vindictiveness towards the White Whale might have possibly extended itself in some degree to all sperm whales, and that the more monsters he slew by so much the more he multiplied the chances that each subsequently encountered whale would prove to be the hated one he hunted
line 4223: But if such an hypothesis be indeed exceptionable, there were still additional considerations which, though not so strictly according with the wildness of his ruling passion, yet were by no means incapable of swaying him
line 4224: To accomplish his object Ahab must use tools; and of all tools used in the shadow of the moon, men are most apt to get out of order
Dist = 0.136 Summary: After being physically and emotionally wounded, Ahab's monomania was unleashed and he directed all of his rage and hate towards Moby Dick, symbolizing the evil in life and thought.
line 3855: All that most maddens and torments; all that stirs up the lees of things; all truth with malice in it; all that cracks the sinews and cakes the brain; all the subtle demonisms of life and thought; all evil, to crazy Ahab, were visibly personified, and made practically assailable in Moby Dick
line 3856: He piled upon the whale’s white hump the sum of all the general rage and hate felt by his whole race from Adam down; and then, as if his chest had been a mortar, he burst his hot heart’s shell upon it
line 3857: It is not probable that this monomania in him took its instant rise at the precise time of his bodily dismemberment
line 3858: Then, in darting at the monster, knife in hand, he had but given loose to a sudden, passionate, corporal animosity; and when he received the stroke that tore him, he probably but felt the agonizing bodily laceration, but nothing more
line 3859: Yet, when by this collision forced to turn towards home, and for long months of days and weeks, Ahab and anguish lay stretched together in one hammock, rounding in mid winter that dreary, howling Patagonian Cape; then it was, that his torn body and gashed soul bled into one another; and so interfusing, made him mad
Dist = 0.143 Summary: The seamen were amazed as Ahab nailed gold to the mast and declared it was Moby Dick, describing him as having a curious fan-tail, a big spout like a shock of wheat, and many iron harpoons twisted in his hide.
line 3294: cried the seamen, as with swinging tarpaulins they hailed the act of nailing the gold to the mast
line 3295: It’s a white whale, I say,
line 3296: resumed Ahab, as he threw down the topmaul:
line 3297: a white whale
line 3298: Skin your eyes for him, men; look sharp for white water; if ye see but a bubble, sing out
line 3299: All this while Tashtego, Daggoo, and Queequeg had looked on with even more intense interest and surprise than the rest, and at the mention of the wrinkled brow and crooked jaw they had started as if each was separately touched by some specific recollection
line 3300: Captain Ahab,
line 3301: said Tashtego,
line 3302: that white whale must be the same that some call Moby Dick
line 3303: shouted Ahab
line 3304: Do ye know the white whale then, Tash
line 3305: Does he fan-tail a little curious, sir, before he goes down
line 3306: said the Gay-Header deliberately
line 3307: And has he a curious spout, too,
line 3308: said Daggoo,
line 3309: very bushy, even for a parmacetty, and mighty quick, Captain Ahab
line 3310: And he have one, two, three—oh
line 3311: good many iron in him hide, too, Captain,
line 3312: cried Queequeg disjointedly,
line 3313: all twiske-tee be-twisk, like him—him—
line 3314: faltering hard for a word, and screwing his hand round and round as though uncorking a bottle—
line 3315: like him—him—
line 3316: cried Ahab,
line 3317: aye, Queequeg, the harpoons lie all twisted and wrenched in him; aye, Daggoo, his spout is a big one, like a whole shock of wheat, and white as a pile of our Nantucket wool after the great annual sheep-shearing; aye, Tashtego, and he fan-tails like a split jib in a squall
Dist = 0.144 Summary: For forty years, Ahab has forsaken the peaceful land to make war on the horrors of the deep, leading a life of desolation and solitude, feeding on dry salted fare while others had fresh fruit, and madly chasing his prey with a frenzy more befitting a demon than a man.
line 9768: for forty years has Ahab forsaken the peaceful land, for forty years to make war on the horrors of the deep
line 9769: Aye and yes, Starbuck, out of those forty years I have not spent three ashore
line 9770: When I think of this life I have led; the desolation of solitude it has been; the masoned, walled-town of a Captain’s exclusiveness, which admits but small entrance to any sympathy from the green country without—oh, weariness
line 9771: Guinea-coast slavery of solitary command
line 9772: —when I think of all this; only half-suspected, not so keenly known to me before—and how for forty years I have fed upon dry salted fare—fit emblem of the dry nourishment of my soil
line 9773: —when the poorest landsman has had fresh fruit to his daily hand, and broken the world’s fresh bread to my mouldy crusts—away, whole oceans away, from that young girl-wife I wedded past fifty, and sailed for Cape Horn the next day, leaving but one dent in my marriage pillow—wife
line 9774: —rather a widow with her husband alive
line 9775: Aye, I widowed that poor girl when I married her, Starbuck; and then, the madness, the frenzy, the boiling blood and the smoking brow, with which, for a thousand lowerings old Ahab has furiously, foamingly chased his prey—more a demon than a man
Dist = 0.145 Summary: Ahab has been a fool for forty years, questioning why he is chasing Moby Dick and feeling old and weary, but when he looks into Starbuck's eye he sees his wife and child and decides to stay on board and not take the same risk as him.
line 9776: what a forty years’ fool—fool—old fool, has old Ahab been
line 9777: Why this strife of the chase
line 9778: why weary, and palsy the arm at the oar, and the iron, and the lance
line 9779: how the richer or better is Ahab now
line 9780: Oh, Starbuck
line 9781: is it not hard, that with this weary load I bear, one poor leg should have been snatched from under me
line 9782: Here, brush this old hair aside; it blinds me, that I seem to weep
line 9783: Locks so grey did never grow but from out some ashes
line 9784: But do I look very old, so very, very old, Starbuck
line 9785: I feel deadly faint, bowed, and humped, as though I were Adam, staggering beneath the piled centuries since Paradise
line 9786: —crack my heart
line 9787: —stave my brain
line 9788: bitter, biting mockery of grey hairs, have I lived enough joy to wear ye; and seem and feel thus intolerably old
line 9789: stand close to me, Starbuck; let me look into a human eye; it is better than to gaze into sea or sky; better than to gaze upon God
line 9790: By the green land; by the bright hearth-stone
line 9791: this is the magic glass, man; I see my wife and my child in thine eye
line 9792: No, no; stay on board, on board
line 9793: —lower not when I do; when branded Ahab gives chase to Moby Dick
line 9794: That hazard shall not be thine
Dist = 0.145 Summary: Ahab's crew seemed to be chosen by fate to help him in his revenge against the White Whale, and they shared his hatred for it, though it is unclear why or how this came to be.
line 3891: Such a crew, so officered, seemed specially picked and packed by some infernal fatality to help him to his monomaniac revenge
line 3892: How it was that they so aboundingly responded to the old man’s ire—by what evil magic their souls were possessed, that at times his hate seemed almost theirs; the White Whale as much their insufferable foe as his; how all this came to be—what the White Whale was to them, or how to their unconscious understandings, also, in some dim, unsuspected way, he might have seemed the gliding great demon of the seas of life,—all this to explain, would be to dive deeper than Ishmael can go
line 3893: The subterranean miner that works in us all, how can one tell whither leads his shaft by the ever shifting, muffled sound of his pick
line 3894: Who does not feel the irresistible arm drag
line 3895: What skiff in tow of a seventy-four can stand still
line 3896: For one, I gave myself up to the abandonment of the time and the place; but while yet all a-rush to encounter the whale, could see naught in that brute but the deadliest ill
line 3897: The Whiteness of the Whale
line 3898: What the white whale was to Ahab, has been hinted; what, at times, he was to me, as yet remains unsaid
execution took 4.342 seconds









You must be logged in to post a comment.