
Return glasses for less powerful prescription. I’ll do that after my 2:00 meeting
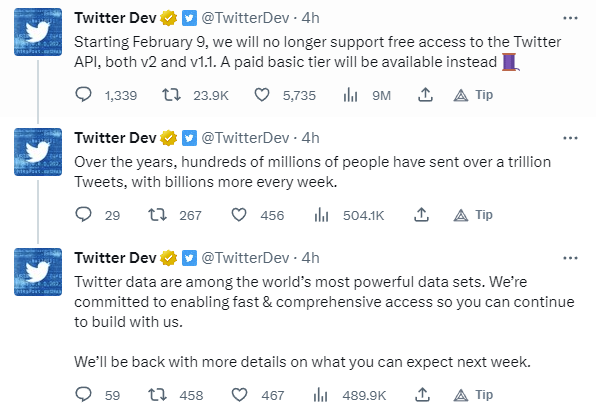
Looks like the end of academic access. Ah well, it was a nice run. Trained language models are more fun anyway
Extracting Training Data from Diffusion Models
- Image diffusion models such as DALL-E 2, Imagen, and Stable Diffusion have attracted significant attention due to their ability to generate high-quality synthetic images. In this work, we show that diffusion models memorize individual images from their training data and emit them at generation time. With a generate-and-filter pipeline, we extract over a thousand training examples from state-of-the-art models, ranging from photographs of individual people to trademarked company logos. We also train hundreds of diffusion models in various settings to analyze how different modeling and data decisions affect privacy. Overall, our results show that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training.
And I found the Trump campaign trip I’ve been looking for!
SBIRs
- Finished the second draft! Need to send it out for some external sanity check. The SLT would like to see it too.
- 9:15 standup – done
- 11:30 CSC touch point
- 2:00 MORS meeting with Aaron – done! Sent off to SLT
- Send draft! Done!
- Check out GPT-Index (github.com/jerryjliu/gpt_index) – done! Need to see if it will work with Python 3.7.4
- Talk to Rukan and Aaron about making a separate repo for binary encoding project, notebooks, and results – done. Set up tomorrow maybe?
GPT-Agents
- Copy over and wire up PCA, TSNE, and DBSCAN.
Book
- Start proofing. I think downloading chapters to Word for grammar and spell checks is probably the way to go
