
GPT Agents
- Submit paper
- Switch Tweet Embedding over to binary and list-based embedding retrieval
- Add cluster labeling Done! With GPT response. Still need to use average center of cluster and roll that into the update callback:
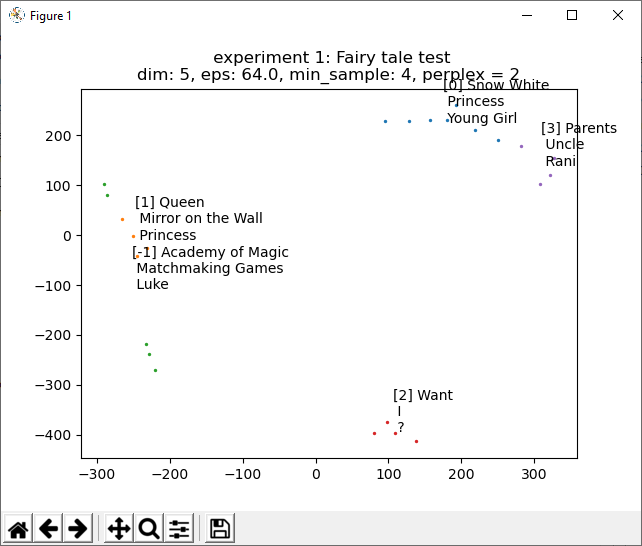
- Cluster -1 doesn’t make much sense because those are non-clustered points
SBIRs
- Thinking about the document explorer. I think that taking the average of the embeddings in a cluster and then sorting the list to produce either extracting keywords, summarizing, or something that does a version for extracting topics should work.
- To get narrative mappings to work, there may need to multiple “summaries plus implications to xxx” that might be needed. Then the same process as the NarrativeExplorer should work.
- There needs to be a single-parent, multi-children relationship to a hierarchical clustering of a document set. Sentence->paragraph->chapter->book->collection, etc. in each case, there can be an embedding from the actual text (up to the max tokens?), and then generated text/embedding from the GPT.
- Reading in a book is a multi-level process, that should then make returning results faster and better.
