
7:00 – 4:00 ASRC MKT
- Reinforcement Learning: An Introduction (2nd Edition)
- Richard S. Sutton (Scholar): I am seeking to identify general computational principles underlying what we mean by intelligence and goal-directed behavior. I start with the interaction between the intelligent agent and its environment. Goals, choices, and sources of information are all defined in terms of this interaction. In some sense it is the only thing that is real, and from it all our sense of the world is created. How is this done? How can interaction lead to better behavior, better perception, better models of the world? What are the computational issues in doing this efficiently and in realtime? These are the sort of questions that I ask in trying to understand what it means to be intelligent, to predict and influence the world, to learn, perceive, act, and think. In practice, I work primarily in reinforcement learning as an approach to artificial intelligence. I am exploring ways to represent a broad range of human knowledge in an empirical form–that is, in a form directly in terms of experience–and in ways of reducing the dependence on manual encoding of world state and knowledge.
- Andrew G. Barto : Most of my recent work has been about extending reinforcement learning methods so that they can work in real-time with real experience, rather than solely with simulated experience as in many of the most impressive applications to date. Of particular interest to me at present is what psychologists call intrinsically motivated behavior, meaning behavior that is done for its own sake rather than as a step toward solving a specific problem of clear practical value. What we learn during intrinsically motivated behavior is essential for our development as competent autonomous entities able to efficiently solve a wide range of practical problems as they arise. Recent work by my colleagues and me on what we call intrinsically motivated reinforcement learning is aimed at allowing artificial agents to construct and extend hierarchies of reusable skills that form the building blocks for open-ended learning. Visit the Autonomous Learning Laboratory page for some more details.
- There was a piece on BBC Business Daily on social network moderators. Aside from it being a horrible job, the show touched on how international criminal cases often rest on video uploaded to services like Twitter and Facebook. This process worked as long as the moderators were human and could tell the difference between criminal activity and the documentation of criminal activity, but now with ML solutions being implemented, these videos are being deleted. First, this shows how ad-hoc the usage of these networks are as a place for legal and journalistic activity. Second, it shows the need for a mechanism that is built to support these activities, where there is a more expansive role of reporter/researcher and editor. This is near the center of gravity for the TACJOUR project.
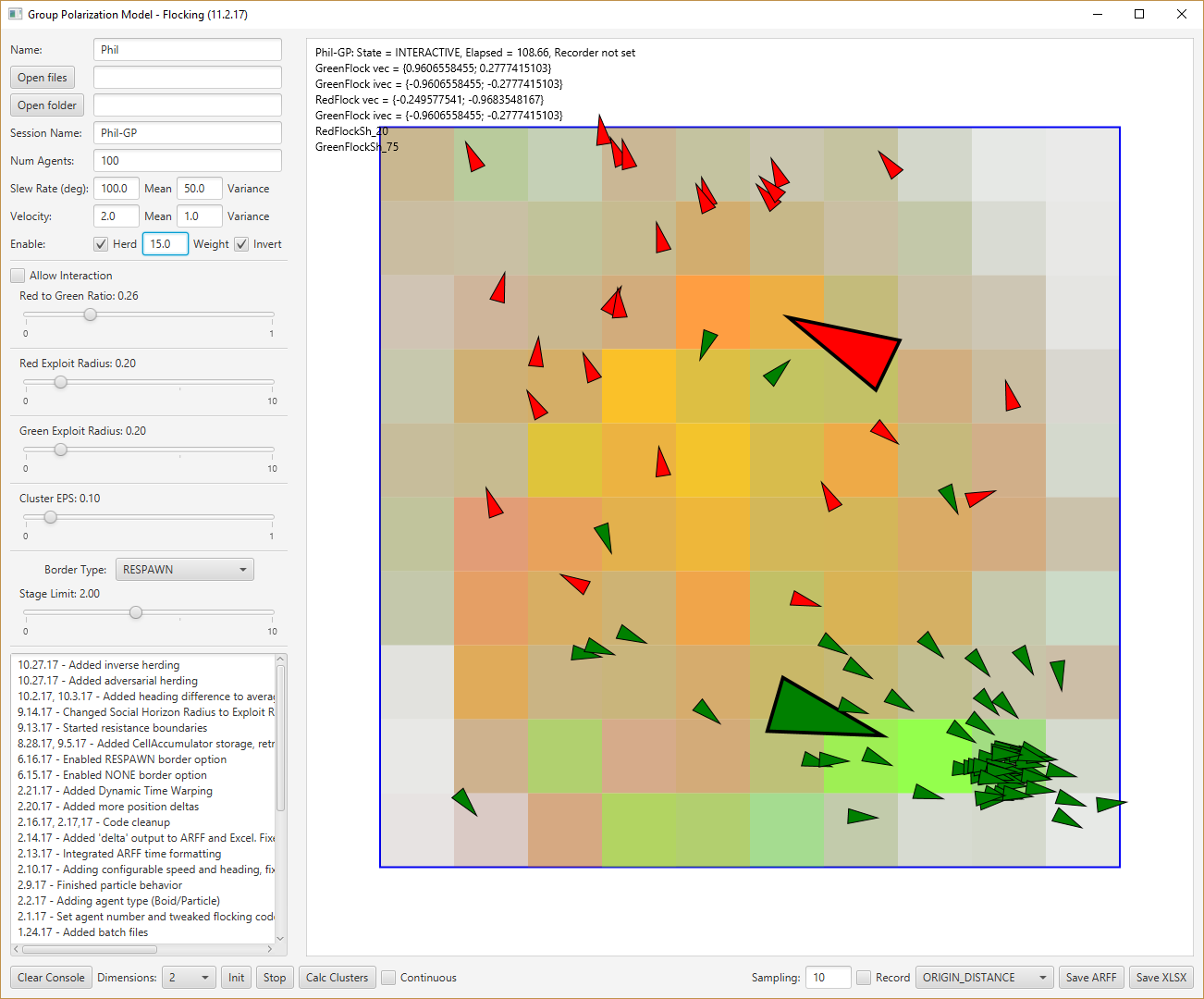
- Flying home yesterday, I was thinking about how the maps need to get built. One way of thinking about it is that you are given a set of directions that run through a geographic area and have to build a map from that. We know the adjacencies by the sequence of the directions. It follows that we should be able to build a map by overlaying all the routes in an n-dimensional space. I was then reading Technical Perspective: Exploring a Kingdom by Geodesic Measures, and at least some of the concepts appear related. In the case of the game at least, we have the center ‘post’, which is the discussion starting point. The discussion is (can be) a random walk towards the poles created in that iteration. Multiple walks create multiple paths over this unknown Manifold. I’m thinking that this should be enough information to build a self organizing map. This might help: Visual analysis of self-organizing maps
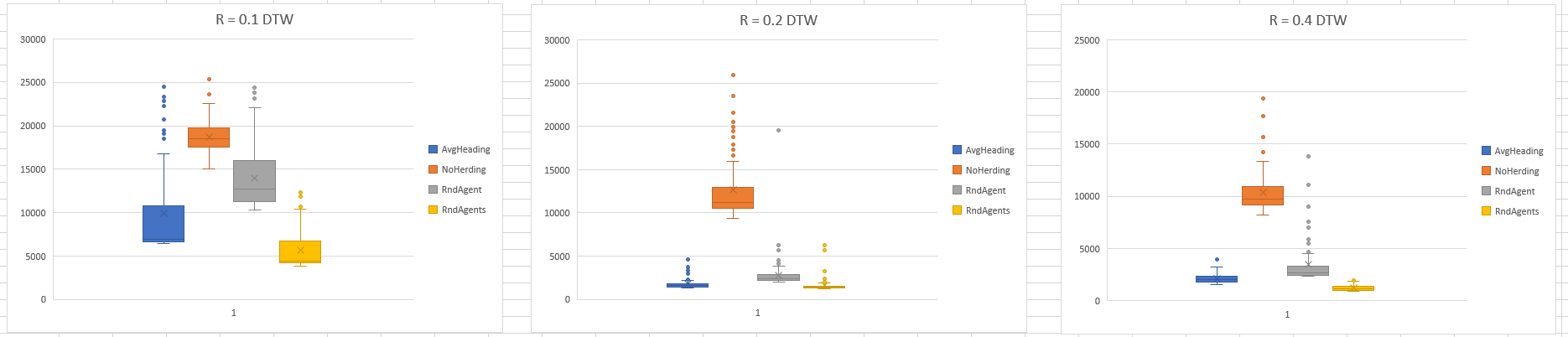
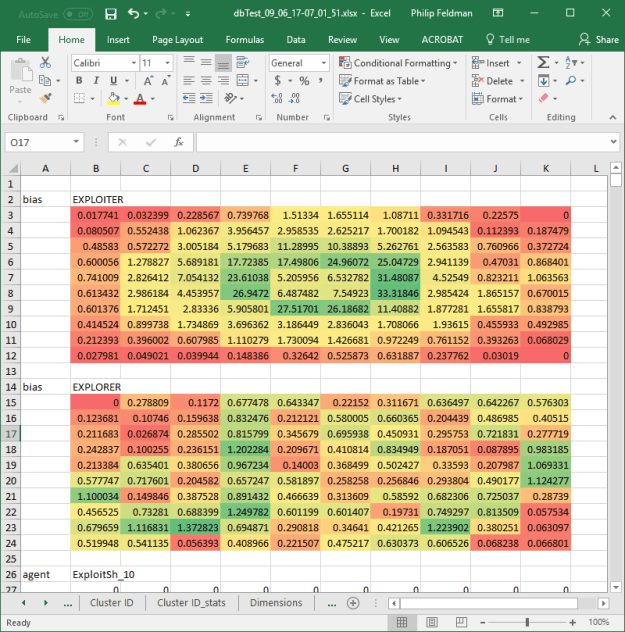
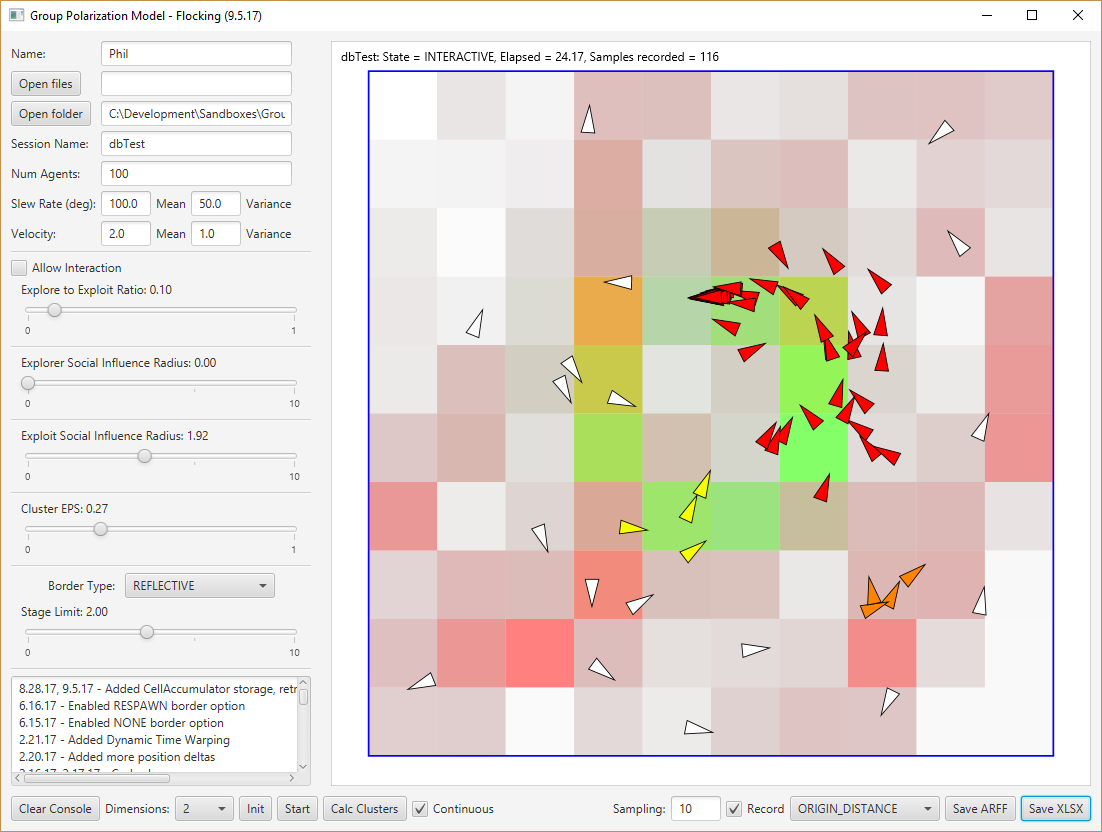
- Had some discussions with Arron about this. It should be pretty straightforward to build a map, grid or hex that trajectories can be recorded from. Then the trajectories can be used to reconstruct the map. Success is evaluated by the similarity between the source map and the reconstructed one.
- I could also add recorded trajectories to the generated spreadsheet. It could be a list of cells that the agent traverses. Comparing explore, flocking and stampede behaviors in their reconstructed maps?
- Continuing with From Keyword Search to Exploration
- The mSpace Browser is a multi faceted column based client for exploring large data sets in the way that makes sense to you. You decide the columns and the order that best suits your browsing needs.
- Yippy search
- Exalead search
- pg 62, animation
- Continuing along with Angular
- Multiple discussions with Aaron about next steps, particularly for anomaly detection













You must be logged in to post a comment.