
I think this might be useful for coherence measures.

7:00 – 4:30 ASRC NASA/PhD
Analyzing Discourse and Text Complexity for Learning and Collaborating
Author: Mihai Dascalu
Notes
7:00 – 4:00 ASRC PhD/NASA

7:00 – 4:30 ASRC PhD/NASA

7:00 – 8:00 (13 hrs) ASRC NASA/PhD





7:00 – 6:00 ASRC PhD
7:00 – 3:00 ASRC NASA
import numpy as np
val = np.array([[0.6]])
row = np.array([[-0.59, 0.75, -0.94,0.34 ]])
col = np.array([[-0.59], [ 0.75], [-0.94], [ 0.34]])
print ("np.dot({}, {}) = {}".format(val, row, np.dot(val, row)))
print ("np.dot({}, {}) = {}".format(col, val, np.dot(col, val)))
'''
note the very different results:
np.dot([[0.6]], [[-0.59 0.75 -0.94 0.34]]) = [[-0.354 0.45 -0.564 0.204]]
np.dot([[-0.59], [ 0.75], [-0.94], [ 0.34]], [[0.6]]) = [[-0.354], [ 0.45 ], [-0.564], [ 0.204]]
'''
# Multiply the values of the relu'd layer [[0, 0.517, 0, 0]] by the goal-output_layer [.61] weight_mat = np.dot(layer_1_col_array, layer_1_to_output_delta) # e.g. [[0], [0.31], [0], [0]] weights_layer_1_to_output_col_array += alpha * weight_mat # add the scaled deltas in # Multiply the streetlights [[1], [0], [1] times the relu2deriv'd input_to_layer_1_delta [[0, 0.45, 0, 0]] weight_mat = np.dot(input_layer_col_array, input_to_layer_1_delta) # e.g. [[0, 0.45, 0, 0], [0, 0, 0, 0], [0, 0.45, 0, 0]] weights_input_to_layer_1_array += alpha * weight_mat # add the scaled deltas in
7:00 – 4:30 ASRC PhD/NASA
[ "a", "about", "above", "after", "again", "against", "all", "am", "an", "and", "any", "are", "as", "at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "could", "did", "do", "does", "doing", "down", "during", "each", "few", "for", "from", "further", "had", "has", "have", "having", "he", "he'd", "he'll", "he's", "her", "here", "here's", "hers", "herself", "him", "himself", "his", "how", "how's", "i", "i'd", "i'll", "i'm", "i've", "if", "in", "into", "is", "it", "it's", "its", "itself", "let's", "me", "more", "most", "my", "myself", "nor", "of", "on", "once", "only", "or", "other", "ought", "our", "ours", "ourselves", "out", "over", "own", "same", "she", "she'd", "she'll", "she's", "should", "so", "some", "such", "than", "that", "that's", "the", "their", "theirs", "them", "themselves", "then", "there", "there's", "these", "they", "they'd", "they'll", "they're", "they've", "this", "those", "through", "to", "too", "under", "until", "up", "very", "was", "we", "we'd", "we'll", "we're", "we've", "were", "what", "what's", "when", "when's", "where", "where's", "which", "while", "who", "who's", "whom", "why", "why's", "with", "would", "you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves" ]
7:00 – 4:00 ASRC PhD
import pymysql
class forum_reader:
connection: pymysql.connections.Connection
def __init__(self, user_name: str, user_password: str, db_name: str):
print("initializing")
self.connection = pymysql.connect(host='localhost', user=user_name, password=user_password, db=db_name)
def read_data(self, sql_str: str) -> str:
with self.connection.cursor() as cursor:
cursor.execute(sql_str)
result = cursor.fetchall()
return"{}".format(result)
def close(self):
self.connection.close()
if __name__ == '__main__':
fr = forum_reader("some_user", "some_pswd", "some_db")
print(fr.read_data("select topic_id, forum_id, topic_title from phpbb_topics"))
initializing ((4, 14, 'SUBJECT: 3 Room Linear Dungeon Test 1'),)
self.connection = pymysql.connect(
host='localhost', user=user_name, password=user_password, db=db_name,
cursorclass=pymysql.cursors.DictCursor)
[{'topic_id': 4, 'forum_id': 14, 'topic_title': 'SUBJECT: 3 Room Linear Dungeon Test 1'}]
CREATE or REPLACE VIEW post_view AS SELECT p.post_id, FROM_UNIXTIME(p.post_time) as post_time, p.topic_id, t.topic_title, t.forum_id, f.forum_name, u.username, p.poster_ip, p.post_subject, p.post_text FROM phpbb_posts p INNER JOIN phpbb.phpbb_forums f ON p.forum_id=f.forum_id INNER JOIN phpbb.phpbb_topics t ON p.topic_id=t.topic_id INNER JOIN phpbb.phpbb_users u ON p.poster_id=u.user_id;
[{
'post_id': 4,
'post_time': datetime.datetime(2018, 11, 27, 16, 0, 27),
'topic_id': 4,
'topic_title': 'SUBJECT: 3 Room Linear Dungeon Test 1',
'forum_id': 14,
'forum_name': 'DB Test',
'username': 'dungeon_master1',
'poster_ip': '71.244.249.217',
'post_subject': 'SUBJECT: 3 Room Linear Dungeon Test 1',
'post_text': 'POST: dungeon_master1 says that you are about to take on a 3-room linear dungeon.'
}]
Progress for today 🙂 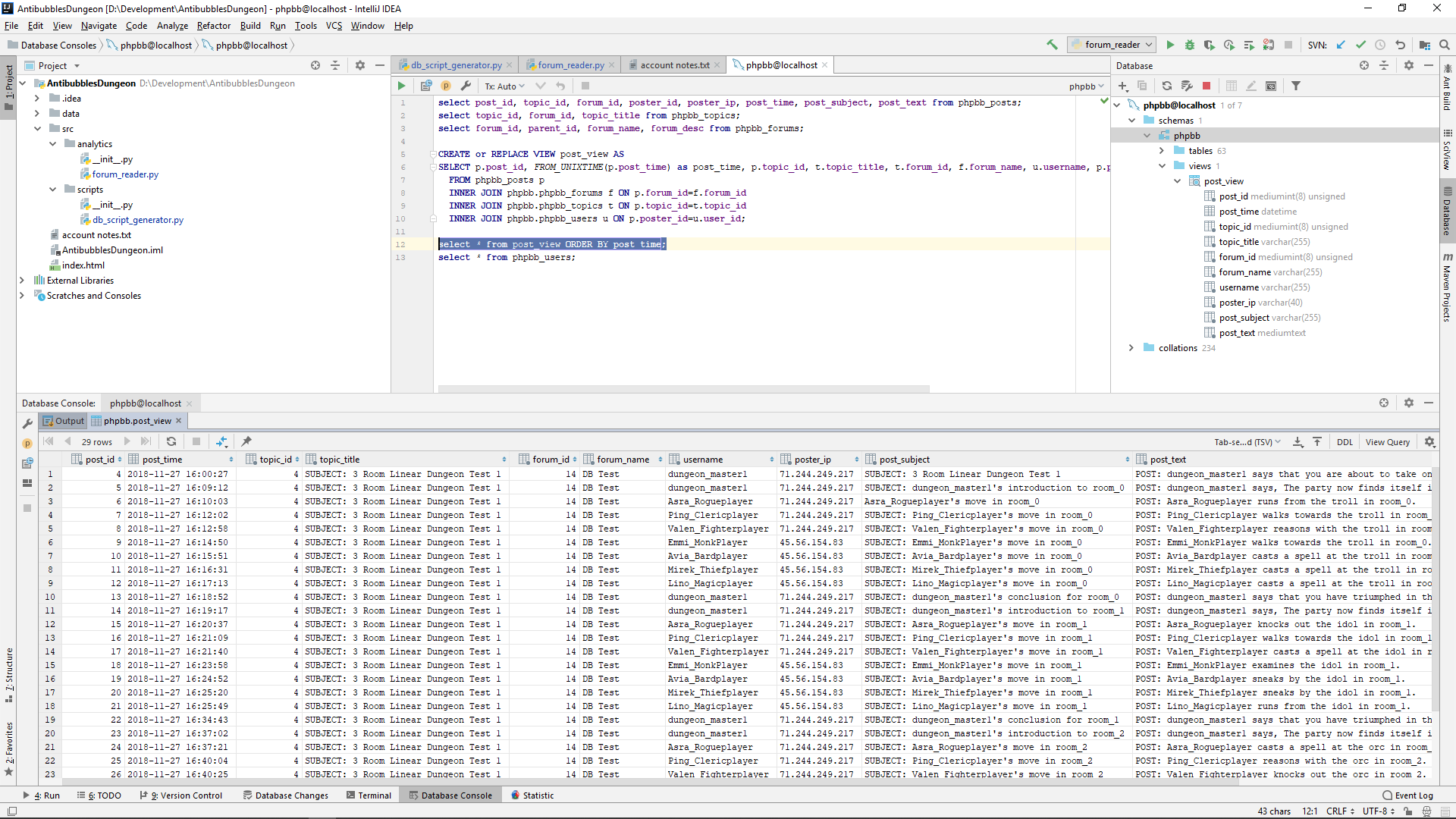
7:00 – 5:00 ASRC PhD
SUBJECT: dungeon_master1's introduction to the dungeon POST: dungeon_master1 says that you are about to take on a 3-room linear dungeon. SUBJECT: dungeon_master1's introduction to room_0 POST: dungeon_master1 says, The party now finds itself in room_0. There is a troll here. SUBJECT: Asra_Rogueplayer's move in room_0 POST: Asra_Rogueplayer runs from the troll in room_0. SUBJECT: Ping_Clericplayer's move in room_0 POST: Ping_Clericplayer walks towards the troll in room_0. SUBJECT: Valen_Fighterplayer's move in room_0 POST: Valen_Fighterplayer reasons with the troll in room_0. SUBJECT: Emmi_MonkPlayer's move in room_0 POST: Emmi_MonkPlayer walks towards the troll in room_0. SUBJECT: Avia_Bardplayer's move in room_0 POST: Avia_Bardplayer casts a spell at the troll in room_0. SUBJECT: Mirek_Thiefplayer's move in room_0 POST: Mirek_Thiefplayer casts a spell at the troll in room_0. SUBJECT: Lino_Magicplayer's move in room_0 POST: Lino_Magicplayer casts a spell at the troll in room_0. SUBJECT: dungeon_master1's conclusion for room_0 POST: dungeon_master1 says that you have triumphed in the challenge of room_0. SUBJECT: dungeon_master1's introduction to room_1 POST: dungeon_master1 says, The party now finds itself in room_1. There is an idol here. SUBJECT: Asra_Rogueplayer's move in room_1 POST: Asra_Rogueplayer knocks out the idol in room_1. SUBJECT: Ping_Clericplayer's move in room_1 POST: Ping_Clericplayer walks towards the idol in room_1. SUBJECT: Valen_Fighterplayer's move in room_1 POST: Valen_Fighterplayer casts a spell at the idol in room_1. SUBJECT: Emmi_MonkPlayer's move in room_1 POST: Emmi_MonkPlayer examines the idol in room_1. SUBJECT: Avia_Bardplayer's move in room_1 POST: Avia_Bardplayer sneaks by the idol in room_1. SUBJECT: Mirek_Thiefplayer's move in room_1 POST: Mirek_Thiefplayer sneaks by the idol in room_1. SUBJECT: Lino_Magicplayer's move in room_1 POST: Lino_Magicplayer runs from the idol in room_1. SUBJECT: dungeon_master1's conclusion for room_1 POST: dungeon_master1 says that you have triumphed in the challenge of room_1. SUBJECT: dungeon_master1's introduction to room_2 POST: dungeon_master1 says, The party now finds itself in room_2. There is an orc here. SUBJECT: Asra_Rogueplayer's move in room_2 POST: Asra_Rogueplayer casts a spell at the orc in room_2. SUBJECT: Ping_Clericplayer's move in room_2 POST: Ping_Clericplayer reasons with the orc in room_2. SUBJECT: Valen_Fighterplayer's move in room_2 POST: Valen_Fighterplayer knocks out the orc in room_2. SUBJECT: Emmi_MonkPlayer's move in room_2 POST: Emmi_MonkPlayer runs from the orc in room_2. SUBJECT: Avia_Bardplayer's move in room_2 POST: Avia_Bardplayer walks towards the orc in room_2. SUBJECT: Mirek_Thiefplayer's move in room_2 POST: Mirek_Thiefplayer distracts the orc in room_2. SUBJECT: Lino_Magicplayer's move in room_2 POST: Lino_Magicplayer examines the orc in room_2. SUBJECT: dungeon_master1's conclusion for room_2 POST: dungeon_master1 says that you have triumphed in the challenge of room_2. SUBJECT: dungeon_master1's conclusion POST: dungeon_master1 says that you have triumphed in the challenge of the 3-room linear dungeon.


7:00 – 5:00ASRC PhD
Semantics-Space-Time Cube. A Conceptual Framework for Systematic Analysis of Texts in Space and Time
8:00 – 3:00 ASRC PhD
Listening to How CRISPR Gene Editing Is Changing the World, where Jennifer Kahn discusses the concept of Fitness Cost, where mutations (CRISPR or otherwise) often decrease the fitness of the modified organism. I’m thinking that this relates to the conflicting fitness mechanisms of diverse and monolithic systems. Diverse systems are resilient in the long run. Monolithic systems are effective in the short run. That stochastic interaction between those two time scales is what makes the problem of authoritarianism so hard.
Fitness cost is explicitly modeled here: Kinship, reciprocity and synergism in the evolution of social behaviour
The spread of low-credibility content by social bots
Using Machine Learning to map the field of Collective Intelligence research 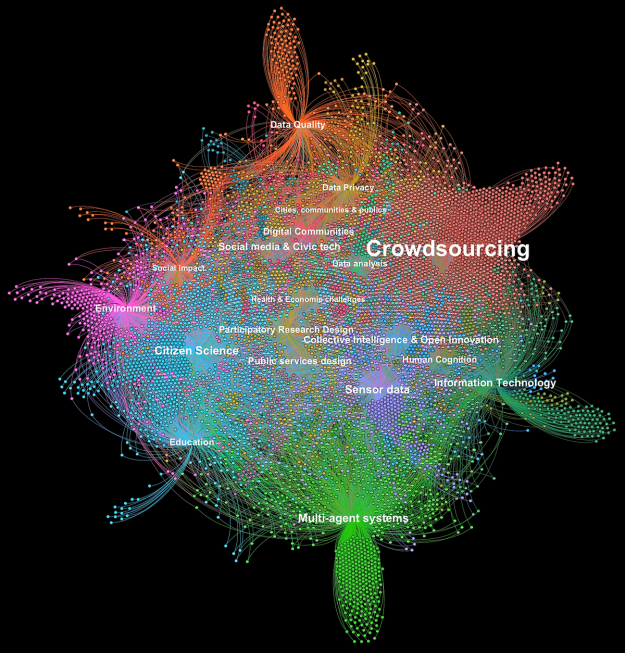
Working on 810 meta-reviews today. Done-ish!

You must be logged in to post a comment.