
ASRC PhD 7:00 – 6:00
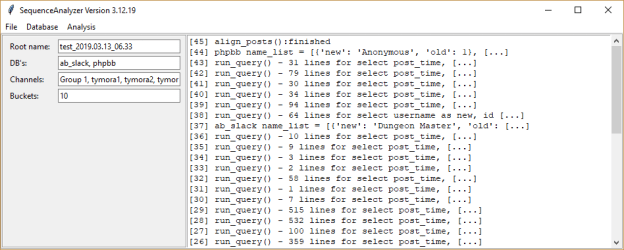
- SlackToDb
- Pull down text – Done, I hope. The network here has bad problems with TLS resolution. Will try from home
- Link sequential posts – done
- Add word lists for places and spaces (read from file, also read embeddings)
- Writing out the config file – done
- Add field for similarity distance threshold. Changing this lists nearby words in the embedding space. These terms are used for trajectory generation and centrality tables.
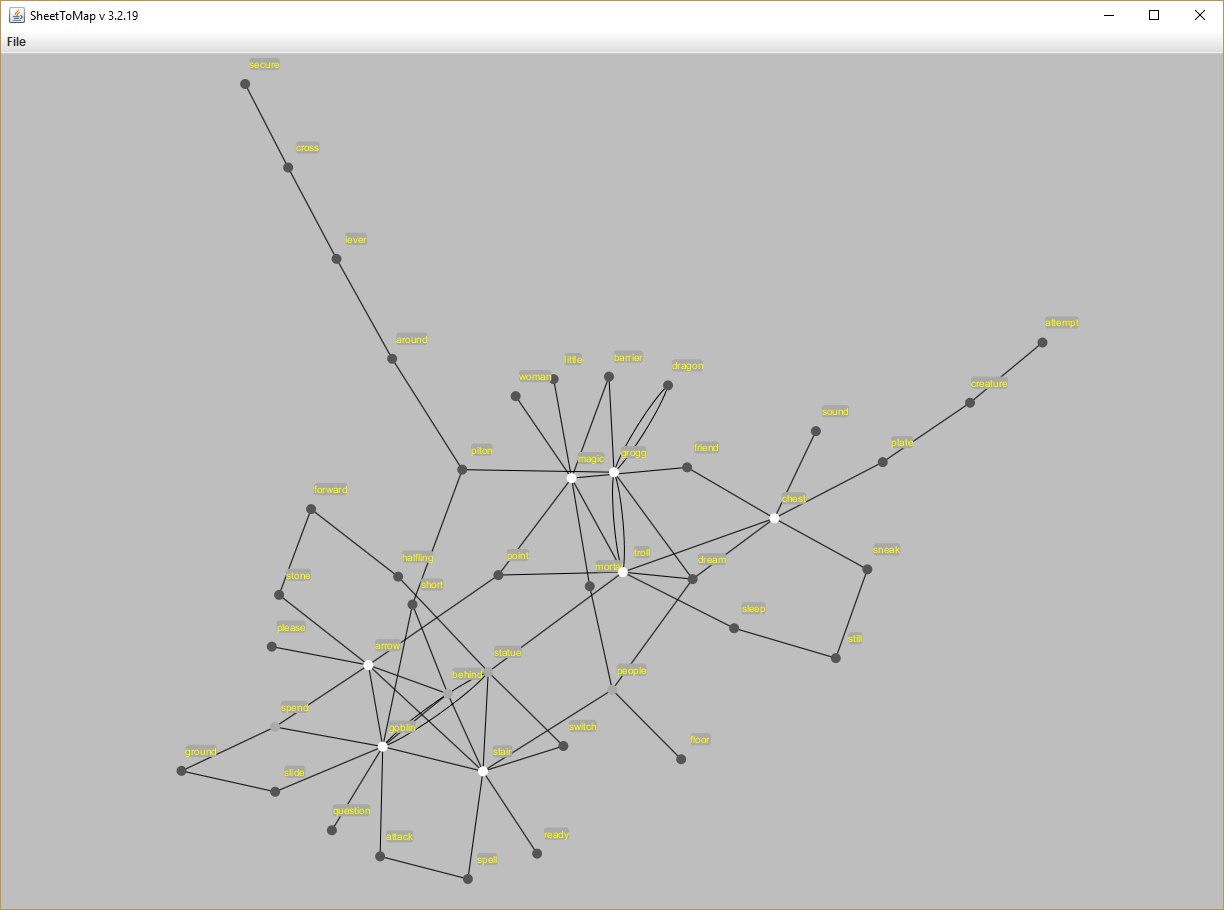
- Add plots for place/space words
- Add phrase-based splitting to find rooms. Buckets work within these splits. Text before the first split and after the last split isn’t used (For embedding, centrality, etc.)
- Add phrase-based trimming. Test before one and after the other isn’t used
- Stub out centrality for (embedded) terms and (concatenated, bucketed, and oriented) documents
- Look into 3d for tkinter (from scratch)
- OpenGL (stackoverflow) (pyopengltk)
- How to embed a Matplotlib graph to your Tkinter GUI
- Embedding Matplotlib In Tk
- Embed a pyplot in a tkinter window and update it – Stack Overflow
- And we’ll need to tab between console and graphics (section 11.4 of tkInter
n = ttk.Notebook(parent) f1 = ttk.Frame(n) # first page, which would get widgets gridded into it f2 = ttk.Frame(n) # second page n.add(f1, text='One') n.add(f2, text='Two')
- Progress for the day:














You must be logged in to post a comment.