7:00 – 4:30 ASRC MKT
- Listening to the Invisibilia episode on the stories we tell ourselves. (I, I, I. Him)
- Listening to BBC Business Daily, on Economists in the doghouse. One of the people being interviewed is Mariana Mazzucato, who wrote The Entrepreneurial State: debunking public vs. private sector myths. She paraphrases Plato: “stories rule the world”. Oddly, this does not show up when you search through Plato’s work. It may be part of the Parable of the Cave, where the stories that the prisoners tell each other build a representation of the world?
- Moby Dick, page 633 – a runaway condition:
- They were one man, not thirty. For as the one ship that held them all; though it was put together of all contrasting things-oak, and maple, and pine wood; iron, and pitch, and hemp-yet all these ran into each other in the one concrete hull, which shot on its way, both balanced and directed by the long central keel; even so, all the individualities of the crew, this man’s valor, that man’s fear; guilt and guiltiness, all varieties were welded into oneness, and were all directed to that fatal goal which Ahab their one lord and keel did point to.
- John Goodall, one of Wayne’s former students is deep into intrusion detection and visualization
- Added comments to Aaron’s Reddit notes / CHI paper
- Chris McCormick has a bunch of nice tutorials on his blog, including this one on Word2Vec:
- This tutorial covers the skip gram neural network architecture for Word2Vec. My intention with this tutorial was to skip over the usual introductory and abstract insights about Word2Vec, and get into more of the details. Specifically here I’m diving into the skip gram neural network model.
- He also did this:
- wiki-sim-search: Similarity search on Wikipedia using gensim in Python.The goals of this project are the following two features:
- Create LSI vector representations of all the articles in English Wikipedia using a modified version of the make_wikicorpus.py script in gensim.
- Perform concept searches and other fun text analysis on Wikipedia, also using gensim functionality.
- Slicing out columns in numpy:
import numpy as np dimension = 3 size = 10 dataset = np.ndarray(shape=(size, dimension)) for x in range(size): for y in range(dimension): val = (y+1) * 10 + x +1 dataset[x,y] = val print(dataset) print(dataset[...,0]) print(dataset[...,1]) print(dataset[...,2])Results in:
[[11. 21. 31.] [12. 22. 32.] [13. 23. 33.] [14. 24. 34.] [15. 25. 35.] [16. 26. 36.] [17. 27. 37.] [18. 28. 38.] [19. 29. 39.] [20. 30. 40.]] [11. 12. 13. 14. 15. 16. 17. 18. 19. 20.] [21. 22. 23. 24. 25. 26. 27. 28. 29. 30.] [31. 32. 33. 34. 35. 36. 37. 38. 39. 40.]
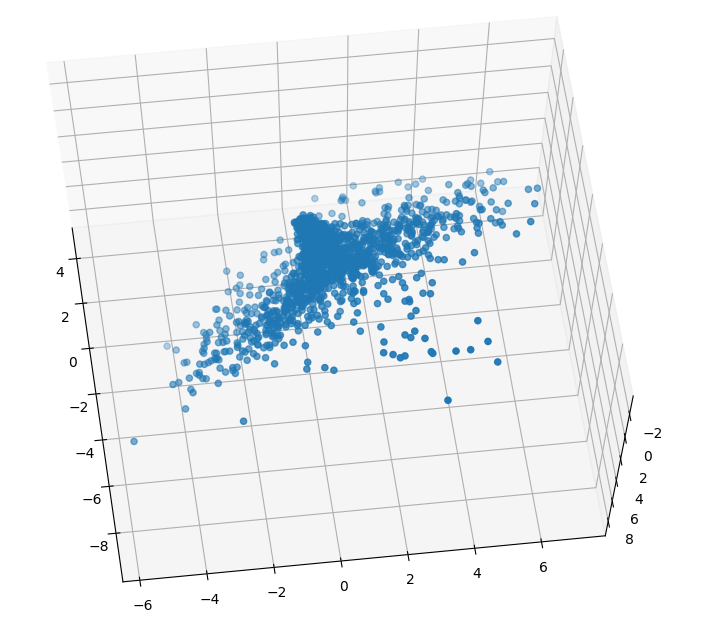
- And that makes everything work. Here’s a screenshot of a 3D embedding space for the entire(?) Jack London corpora:
- A few things come to mind
- I’ll need to get the agents to stay in the space that the points are in. I think each point is an “attractor” with a radius (an agent without a heading). IN the presence of an attractor an agent’s speed is reduced by x%. It there are a lot of attractors (n), then the speed is reduced by xn%. Which should make for slower agents in areas of high density. Agents in the presence of attractors also expand their influence horizon, becoming more “attractive”
- I should be able to draw the area covered by each book in the corpora by looking for the W2V coordinates and plotting them as I read through the (parsed) book. Each book gets a color.