Once more, icky weather makes me productive
- Ingested all the runs into the db. We are at 7,246 posts
- Reworking the 5 bucket analysis
- Building better ignore files and rebuilding bucket spreadsheets. It tuns out that for tymora1, names took up 25% of the BOW, so I increased the fraction saved to the trimmed spreadsheets to 50%
- Building bucket spreadsheets and saving the centrality vector
- Here’s what I’ve got so far:

- Trajectories:

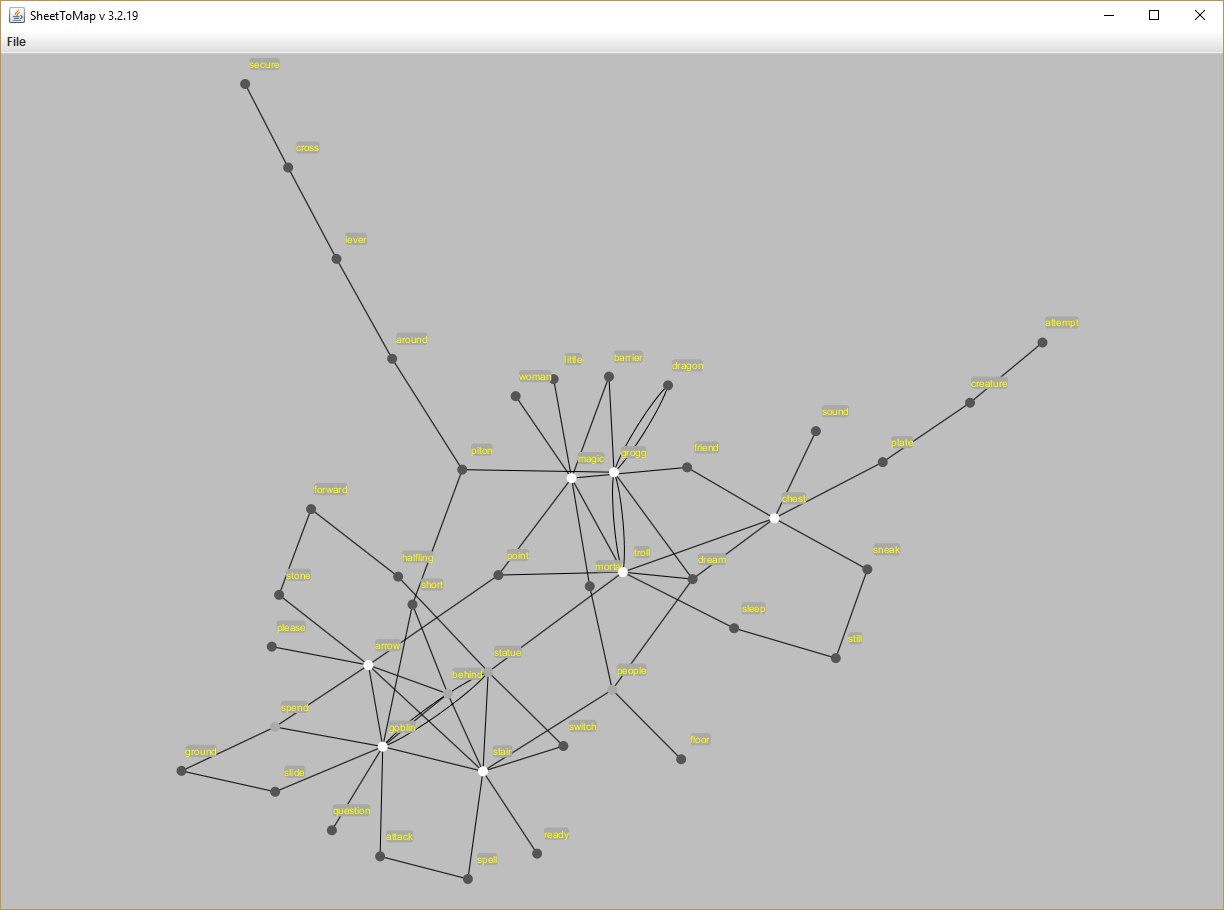
- First map:
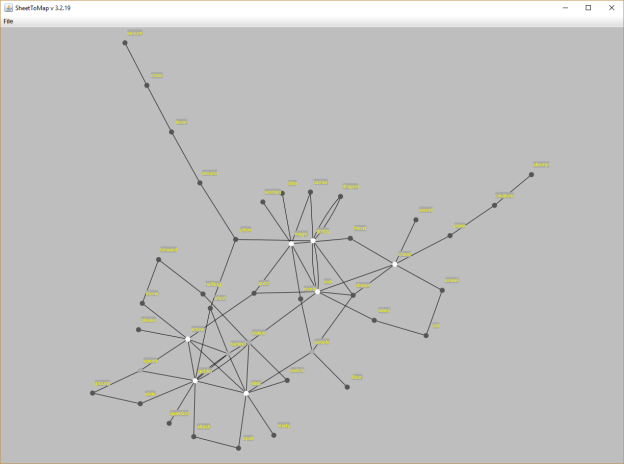
- Here it is annotated:
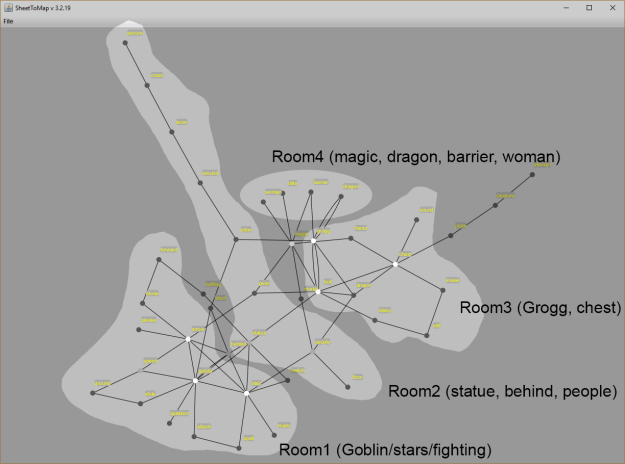
- Some thoughts. I think this is still “zoomed out” too far. Changing the granularity should help some. I need to automate some of my tools though. The other issue is how I’m assembling my sequences.