
7:00 – 6:30ASRC GEOS
- Working more on NK Models. I have the original paper – Towards a general theory of adaptive walks on rugged landscapes, and I’ve pulled out my copy of The Origins of Order
- Determine if I have the evaluation function right
- Add mutation
- Draw the networks
- Draw an N/K/Fitness landscape?
- As an aside, I think that an NK model can be modified to use backpropagation rather than mutation. That could be interesting.
- Ok, here’s everything working the way I think it should work, but I’m not sure it’s right….
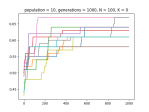
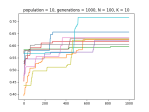
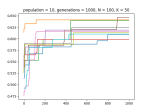
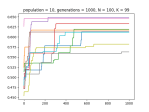
- Need to get back to Antonio about authorship and roles. I think that it makes sense if he can get a sense of what – done
- Discovered the trumptwitterarchive, which is downloadable. Would like to build a network of the retweets and tagging by sentiment, gender and race.
- Code review with Chris. Unfortunately, it was more like an interrogation than a tour. My sense is that he was expecting us to ask questions and we were expecting a presentation.
- It went ok, but the audio connection was terrible





You must be logged in to post a comment.