
GOES
- Reading the Distill article on Gaussian processes (highlighted page here)
- Copy over neural-tangents code from notebook to IDE
- Working on regression
- Ran into a problem with Tensorboard
Traceback (most recent call last): File "d:\program files\python37\lib\runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "d:\program files\python37\lib\runpy.py", line 85, in _run_code exec(code, run_globals) File "D:\Program Files\Python37\Scripts\tensorboard.exe\__main__.py", line 7, in File "d:\program files\python37\lib\site-packages\tensorboard\main.py", line 75, in run_main app.run(tensorboard.main, flags_parser=tensorboard.configure) File "d:\program files\python37\lib\site-packages\absl\app.py", line 299, in run _run_main(main, args) File "d:\program files\python37\lib\site-packages\absl\app.py", line 250, in _run_main sys.exit(main(argv)) File "d:\program files\python37\lib\site-packages\tensorboard\program.py", line 289, in main return runner(self.flags) or 0 File "d:\program files\python37\lib\site-packages\tensorboard\program.py", line 305, in _run_serve_subcommand server = self._make_server() File "d:\program files\python37\lib\site-packages\tensorboard\program.py", line 409, in _make_server self.flags, self.plugin_loaders, self.assets_zip_provider File "d:\program files\python37\lib\site-packages\tensorboard\backend\application.py", line 183, in standard_tensorboard_wsgi flags, plugin_loaders, data_provider, assets_zip_provider, multiplexer File "d:\program files\python37\lib\site-packages\tensorboard\backend\application.py", line 272, in TensorBoardWSGIApp tbplugins, flags.path_prefix, data_provider, experimental_plugins File "d:\program files\python37\lib\site-packages\tensorboard\backend\application.py", line 345, in __init__ "Duplicate plugins for name %s" % plugin.plugin_name ValueError: Duplicate plugins for name projector - After poking around a bit online with the “Duplicate plugins for name %s” % plugin.plugin_name ValueError: Duplicate plugins for name projector, I found this diagnostic, which basically asked me to reinstall everything*. That didn’t work, so I went into the Python37\Lib\site-packages and deleted by hand. Tensorboard now runs, but now I need to upgrade my cuda so that I have cudart64_101.dll
- Installed the minimum set of items from the Nvidia Package Launcher (cuda_10.1.105_418.96_win10.exe)
- Installed the cuDNN drivers from here: https://developer.nvidia.com/rdp/cudnn-download
- The regular (e.g. MNIST) demos work byt when I try the distribution code I got this error: tensorflow.python.framework.errors_impl.InvalidArgumentError: No OpKernel was registered to support Op ‘NcclAllReduce’. It turns out that there are only two viable MirroredStrategy operations, for windows, and the default is not one of them. These are the valid calls:
distribution = tf.distribute.MirroredStrategy(cross_device_ops=tf.distribute.ReductionToOneDevice()) distribution = tf.distribute.MirroredStrategy(cross_device_ops=tf.distribute.HierarchicalCopyAllReduce())
- And this call is not
# distribution = tf.distribute.MirroredStrategy(cross_device_ops=tf.distribute.NcclAllReduce()) # <-- not valid for Windows
- Funny thing. After reinstalling and getting everything to work, I tried the diagnostic again. It seems it always says to reinstall everything
- And Tensorboard is working! Here’s the call that puts data in the directory:
linear_est = tf.estimator.LinearRegressor(feature_columns=feature_columns, model_dir = 'logs/boston/')
- And when launched on the command line pointing at the same directory:
D:\Development\Tutorials\Deep Learning with TensorFlow 2 and Keras\Chapter 3>tensorboard --logdir=.\logs\boston 2020-04-20 11:36:42.999208: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll W0420 11:36:46.005735 18544 plugin_event_accumulator.py:300] Found more than one graph event per run, or there was a metagraph containing a graph_def, as well as one or more graph events. Overwriting the graph with the newest event. W0420 11:36:46.006743 18544 plugin_event_accumulator.py:312] Found more than one metagraph event per run. Overwriting the metagraph with the newest event. Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.1.1 at http://localhost:6006/ (Press CTRL+C to quit)
- I got this!
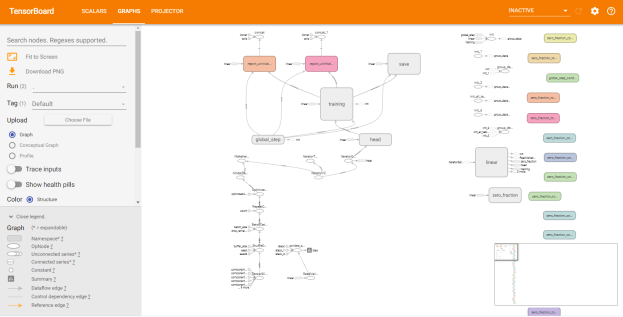
- Of course, we’re not done yet. When attempting to use the Keras callback, I get the following error: tensorflow.python.eager.profiler.ProfilerNotRunningError: Cannot stop profiling. No profiler is running. It turns out that you have to specify the log folder like this
-
- command line:
tensorboard --logdir=.\logs
- in code:
logpath = '.\\logs'
- command line:
-
- That seems to be working!
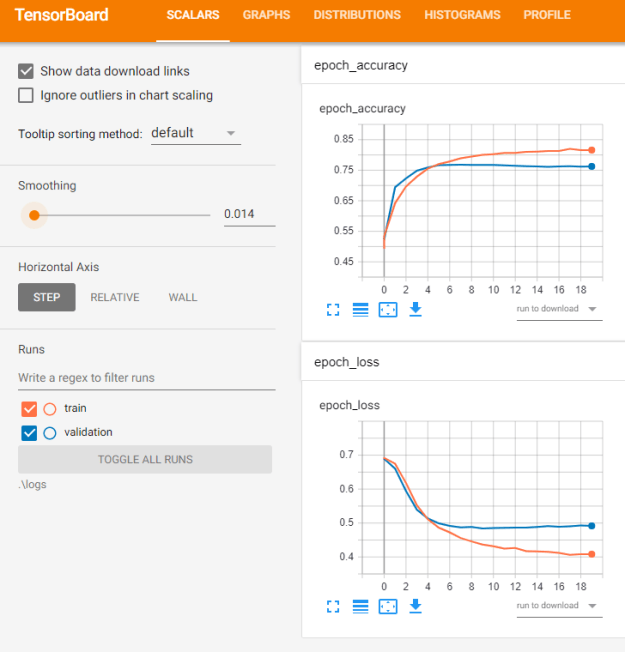
- Finished regression chapter

ASRC
- Submitted RFI response for review
ACSOS
- Got Antonio’s comments back
D20
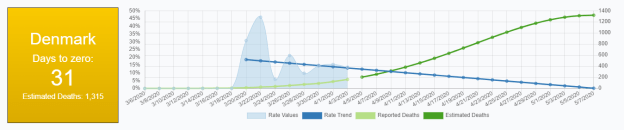
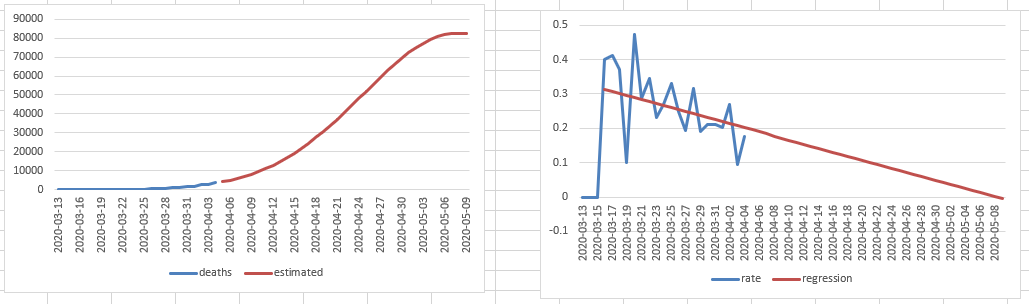
- Need to work on the math to find second bumps
- If the rate has been < x% (maybe 2.5%), calculate an offset that leaves a value of 100 for each day. When the rate jumps more than y% (e.g. 100 – 120 = 20%), freeze that number until the rate settles down again and repeat the process
- Change the number of samples to be the last x days
- Work with Zach to get maps up?
ML seminar
- Worked on getting the neural tangents notebook running on my box but jaxlib is not ported to Windows. Sigh. Find another paper.
- Maybe this? Bringing Stories Alive: Generating Interactive Fiction Worlds


















You must be logged in to post a comment.