
Book
D20
- Zach appears happy with the changes
#COVID
- The Arabic finetuning didn’t work. Drat.
- This could, though….
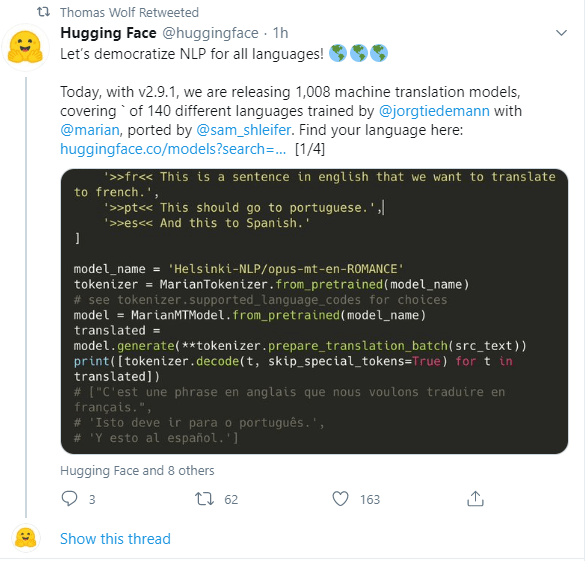
GPT-2 Agents
- Need to handle hints, takes, check, and checkmate:
num_regex = re.compile('[^0-9]') alpha_regex = re.compile('[0-9]') hints_regex = re.compile('[KQNBRx+]') def parse_move(m): hints = [] cleaned = hints_regex.sub('', m) if '++' in m: hints.append("checkmate") elif '+' in m: hints.append("check") if 'x' in m: hints.append("takes") if len(cleaned) > 2: hints.append(cleaned[0]) cleaned = cleaned[1:] piece = piece_regex.sub('', m) num = num_regex.sub('', cleaned) letter = alpha_regex.sub('', cleaned) return "{}/{}: piece = [{}], square = ({}, {}), hints = {}".format(m, cleaned, piece, letter, num, hints) - Roll this in tomorrow. Comments {Anything in curly brackets}? Also, it looks like there are more meta tags (Note player name with no comma!):
[Black "Ding Liren"] [WhiteTitle "GM"] [BlackTitle "GM"] [Opening "Sicilian"] [Variation "Najdorf"] [WhiteFideId "2020009"] [BlackFideId "8603677"]
GOES
- More with TF-GAN from this Google course on GANs
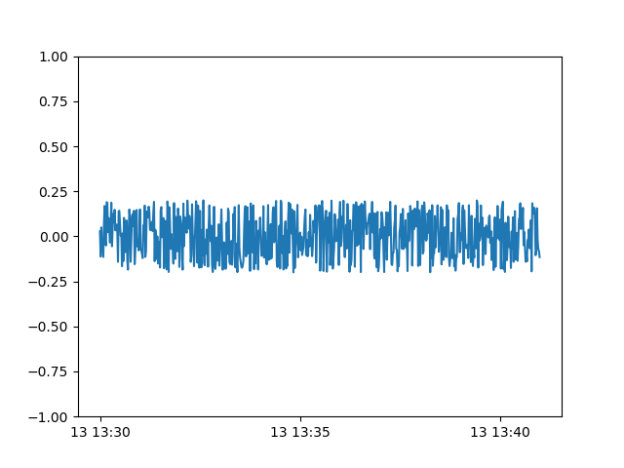
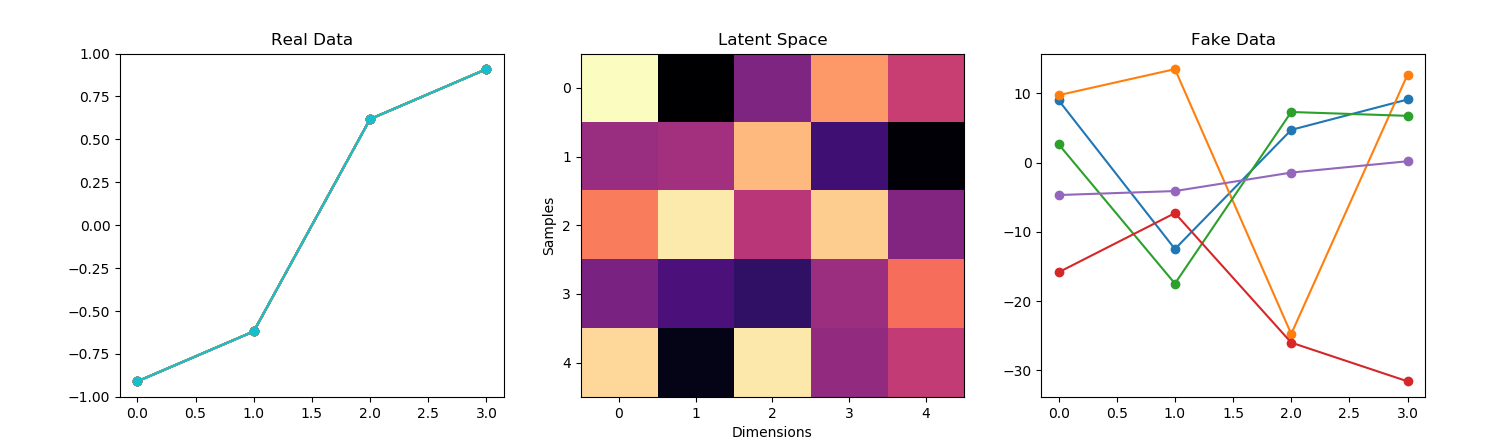
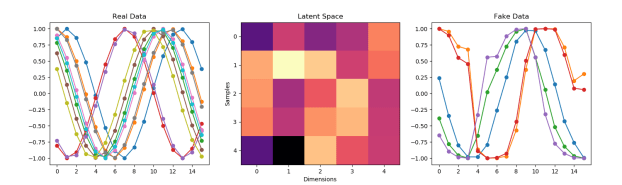
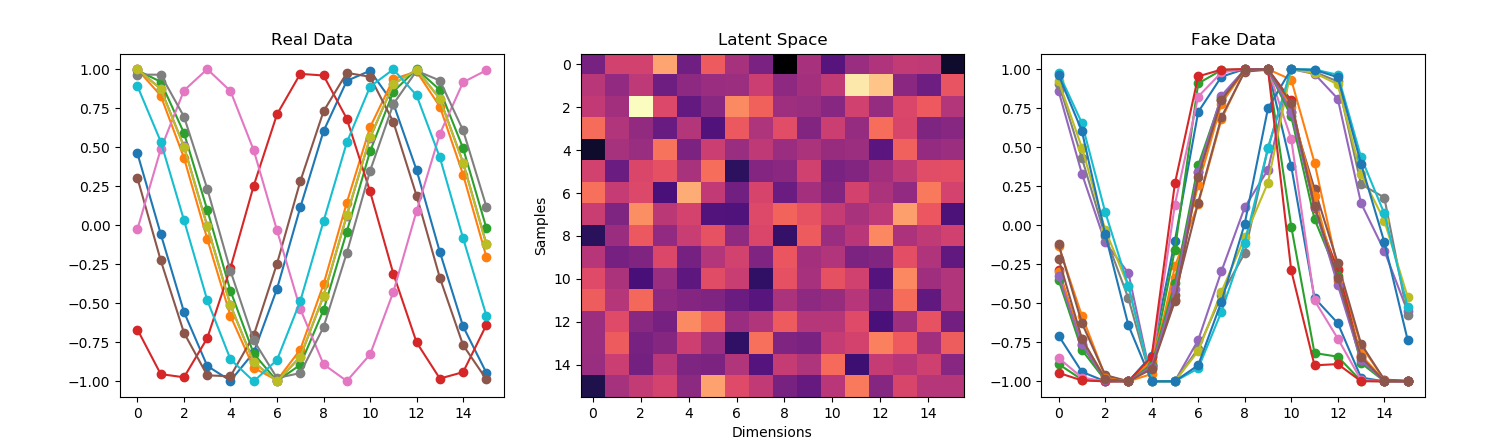
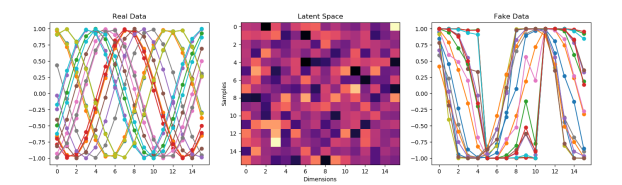
- Mode Collapse is why the GAN keeps generating a single waveform
- Need to contact Joel shor as Google. Sent a note on LinkedIn and a followup email to his Google account (from D:\Development\External\tf-gan\README)
- GANSynth: Making music with GANs
- In this post, we introduce GANSynth, a method for generating high-fidelity audio with Generative Adversarial Networks (GANs).
- 10 Lessons I Learned Training GANs for one Year
- Advanced Topics in GANs
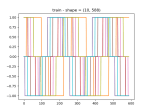
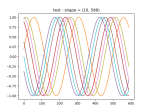
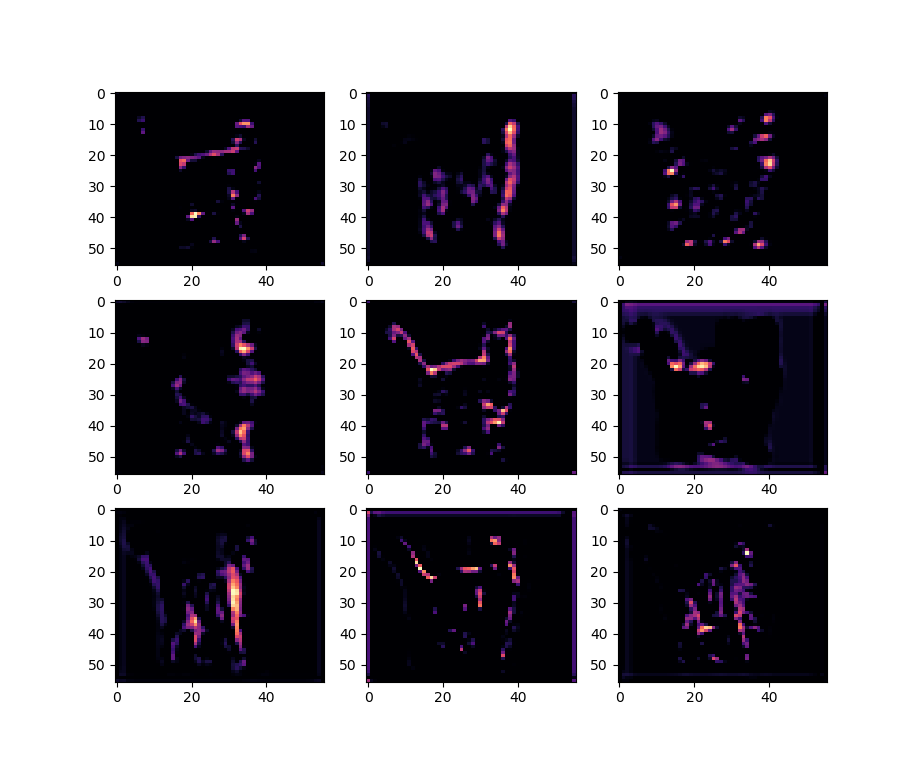
- As I lower the number of neurons in the generator, it starts to look better, but now there are odd artifacts in the untrained data :
self.g_model.add(Dense(5, activation='relu', kernel_initializer='he_uniform', input_dim=self.latent_dimension))


- Thought I’d try the TF-GAN examples but I get many compatability errors that make me thing that this does not work with TF 2.x. So I decided to try the Google Colab. Aaaaand that doesn’t work either:

- Looking through Generative Deep Learning, it says that CNNs help make the discriminator better:
- In the original GAN paper, dense layers were used in place of the convolutional layers. However, since then, it has been shown that convolutional layers give greater predictive power to the discriminator. You may see this type of GAN called a DCGAN (deep convolutional generative adversarial network) in the literature, but now essentially all GAN architectures contain convolutional layers, so the “DC” is implied when we talk about GANs. It is also common to see batch normalization layers in the discriminator for vanilla GANs, though we choose not to use them here for simplicity.
- So, tf.keras.layers.Conv1D
- Keras Conv1D: Working with 1D Convolutional Neural Networks in Keras
- A 1D CNN is very effective for deriving features from a fixed-length segment of the overall dataset, where it is not so important where the feature is located in the segment.
- Keras Conv1D: Working with 1D Convolutional Neural Networks in Keras
- 10:00 meeting with Vadim






























You must be logged in to post a comment.