
7:00 – 5:00 ASRC MKT
- Target Blue Sky paper for iSchool/iConference 2019: The chairs are particularly looking for “Blue Sky Ideas” that are open-ended, possibly even “outrageous” or “wacky,” and present new problems, new application domains, or new methodologies that are likely to stimulate significant new research.
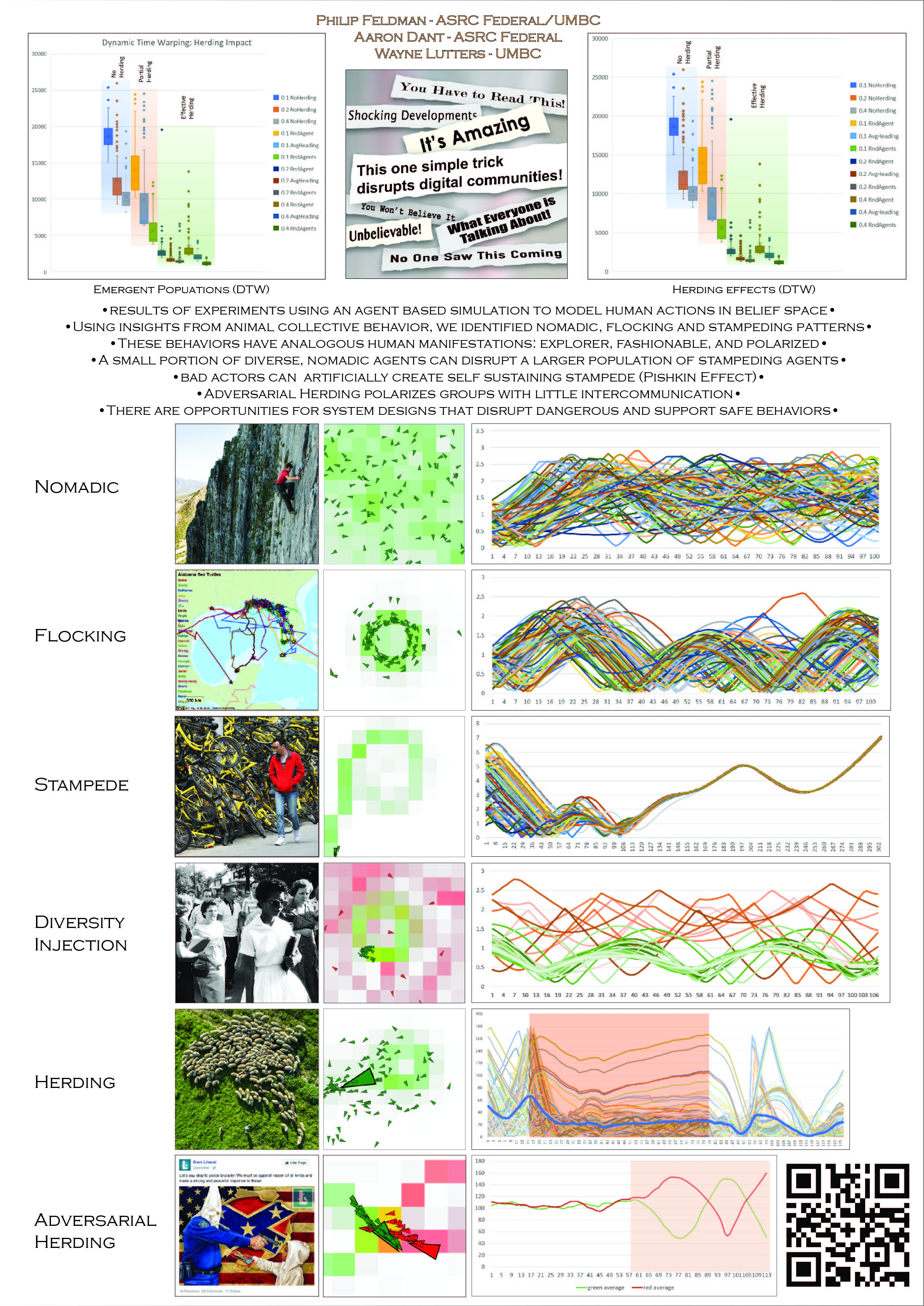
- I’m thinking that a paper that works through the ramifications of this diagram as it relates to people and machines. With humans that are slow responding with spongy, switched networks the flocking area is large. With a monolithic densely connected system it’s going to be a straight line from nomadic to stampede.

- Length: Up to 4 pages (excluding references)
- Submission deadline: October 1, 2018
- Notification date: mid-November, 2018
- Final versions due: December 14, 2018
- First versions will be submitted using .pdf. Final versions must be submitted in .doc, .docx or La Tex.
- More good stuff on BBC Business Daily Trolling for Cash
- Anger and animosity is prevalent online, with some people even seeking it out. It’s present on social media of course as well as many online forums. But now outrage has spread to mainstream media outlets and even the advertising industry. So why is it so lucrative? Bonny Brooks, a writer and researcher at Newcastle University explains who is making money from outrage. Neuroscientist Dr Dean Burnett describes what happens to our brains when we see a comment designed to provoke us. And Curtis Silver, a tech writer for KnowTechie and ForbesTech, gives his thoughts on what we need to do to defend ourselves from this onslaught of outrage.
- Exposure to Opposing Views can Increase Political Polarization: Evidence from a Large-Scale Field Experiment on Social Media
- Christopher Bail (Scholar)
- There is mounting concern that social media sites contribute to political polarization by creating “echo chambers” that insulate people from opposing views about current events. We surveyed a large sample of Democrats and Republicans who visit Twitter at least three times each week about a range of social policy issues. One week later, we randomly assigned respondents to a treatment condition in which they were offered financial incentives to follow a Twitter bot for one month that exposed them to messages produced by elected officials, organizations, and other opinion leaders with opposing political ideologies. Respondents were re-surveyed at the end of the month to measure the effect of this treatment, and at regular intervals throughout the study period to monitor treatment compliance. We find that Republicans who followed a liberal Twitter bot became substantially more conservative post-treatment, and Democrats who followed a conservative Twitter bot became slightly more liberal post-treatment. These findings have important implications for the interdisciplinary literature on political polarization as well as the emerging field of computational social science.
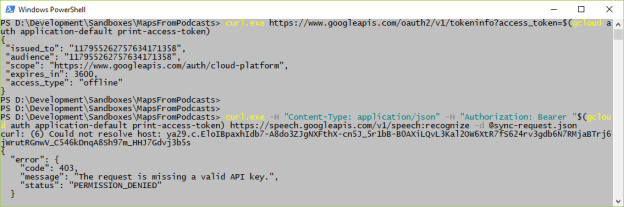
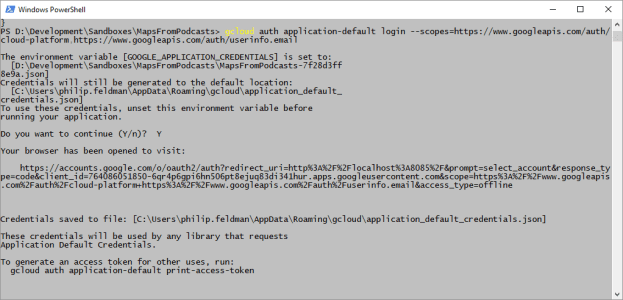
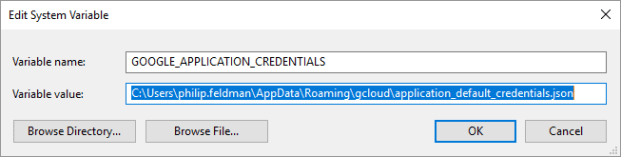
- Setup gcloud tools on laptop – done
- Setup Tensorflow on laptop. Gave up un using CUDA 9.1, but got tf doing ‘hello, tensorflow’
- Marcom meeting – 2:00
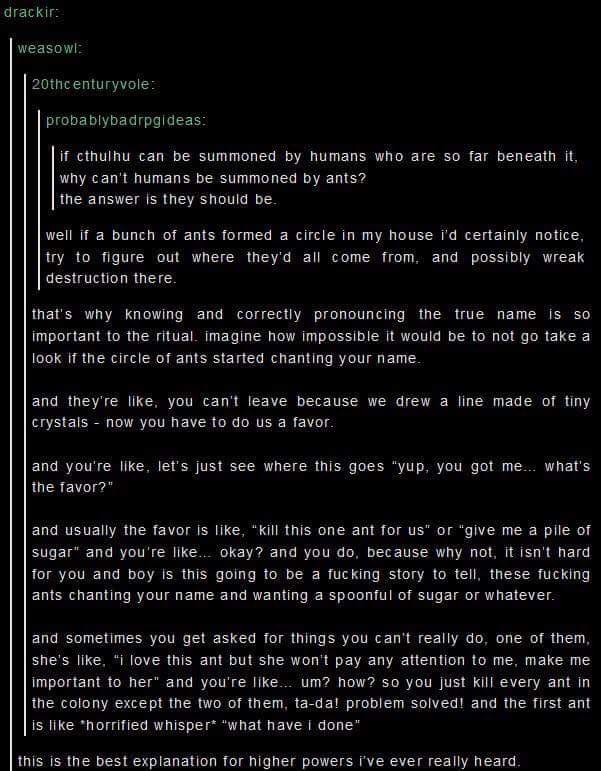
- Get the concept of behaviors being a more scalable, dependable way of vetting information.
- Eg Watching the DISI of outrage as manifested in trolling
- “Uh. . . . not to be nitpicky,,,,,but…the past tense of drag is dragged, not drug.”: An overview of trolling strategies
- Dr Claire Hardaker (Scholar) (Blog)
- I primarily research aggression, deception, and manipulation in computer-mediated communication (CMC), including phenomena such as flaming, trolling, cyberbullying, and online grooming. I tend to take a forensic linguistic approach, based on a corpus linguistic methodology, but due to the multidisciplinary nature of my research, I also inevitably branch out into areas such as psychology, law, and computer science.
- This paper investigates the phenomenon known as trolling — the behaviour of being deliberately antagonistic or offensive via computer-mediated communication (CMC), typically for amusement’s sake. Having previously started to answer the question, what is trolling? (Hardaker 2010), this paper seeks to answer the next question, how is trolling carried out? To do this, I use software to extract 3,727 examples of user discussions and accusations of trolling from an eighty-six million word Usenet corpus. Initial findings suggest that trolling is perceived to broadly fall across a cline with covert strategies and overt strategies at each pole. I create a working taxonomy of perceived strategies that occur at different points along this cline, and conclude by refining my trolling definition.
- Citing papers
- Dr Claire Hardaker (Scholar) (Blog)
- “Uh. . . . not to be nitpicky,,,,,but…the past tense of drag is dragged, not drug.”: An overview of trolling strategies
- Eg Watching the DISI of outrage as manifested in trolling
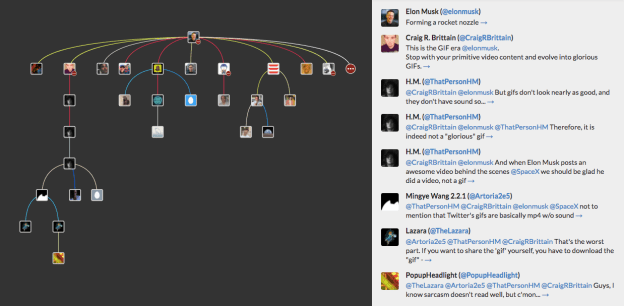
- FireAnt (Filter, Identify, Report, and Export Analysis Toolkit) is a freeware social media and data analysis toolkit with built-in visualization tools including time-series, geo-position (map), and network (graph) plotting.
- Fix marquee – done
- Export to ppt – done!
- include videos – done
- Center title in ppt:
- model considerations – done
- diversity injection – done
- Got the laptop running Python and Tensorflow. Had a stupid problem where I accidentally made a virtual environment and keras wouldn’t work. Removed, re-connected and restarted IntelliJ and everything is working!











You must be logged in to post a comment.