
7:00 – 4:00 ASRC MKT
- Oh, look, a new Tensorflow (1.10). Time to break things. I like the BigTable integration though.
- Learning Meaning in Natural Language Processing — A Discussion
-
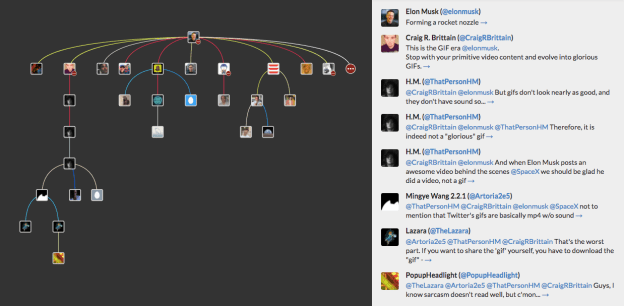
Last week a tweet by Jacob Andreas triggered a huge discussion on Twitter that many people have called the meaning/semantics mega-thread. Twitter is a great medium for having such a discussion, replying to any comment allows to revive the debate from the most promising point when it’s stuck in a dead-end. Unfortunately Twitter also makes the discussion very hard to read afterwards so I made three entry points to explore this fascinating mega-thread:
- a summary of the discussion that you will find below,
- an interactive view to explore the trees of tweets, and
- a commented map to get an overview of the main points discussed:
-
- The Current Best of Universal Word Embeddings and Sentence Embeddings
-
This post is thus a brief primer on the current state-of-the-art in Universal Word and Sentence Embeddings, detailing a few
- strong/fast baselines: FastText, Bag-of-Words
- state-of-the-art models: ELMo, Skip-Thoughts, Quick-Thoughts, InferSent, MILA/MSR’s General Purpose Sentence Representations & Google’s Universal Sentence Encoder.
If you want some background on what happened before 2017 😀, I recommend the nice post on word embeddings that Sebastian wrote last year and his intro posts.
-
- Treeverse is a browser extension for navigating burgeoning Twitter conversations.
- Detecting computer-generated random responding in questionnaire-based data: A comparison of seven indices
- With the development of online data collection and instruments such as Amazon’s Mechanical Turk (MTurk), the appearance of malicious software that generates responses to surveys in order to earn money represents a major issue, for both economic and scientific reasons. Indeed, even if paying one respondent to complete one questionnaire represents a very small cost, the multiplication of botnets providing invalid response sets may ultimately reduce study validity while increasing research costs. Several techniques have been proposed thus far to detect problematic human response sets, but little research has been undertaken to test the extent to which they actually detect nonhuman response sets. Thus, we proposed to conduct an empirical comparison of these indices. Assuming that most botnet programs are based on random uniform distributions of responses, we present and compare seven indices in this study to detect nonhuman response sets. A sample of 1,967 human respondents was mixed with different percentages (i.e., from 5% to 50%) of simulated random response sets. Three of the seven indices (i.e., response coherence, Mahalanobis distance, and person–total correlation) appear to be the best estimators for detecting nonhuman response sets. Given that two of those indices—Mahalanobis distance and person–total correlation—are calculated easily, every researcher working with online questionnaires could use them to screen for the presence of such invalid data.
- Continuing to work on SASO slides – close to done. Got a lot of adversarial herding FB examples from the House Permanent Committee on Intelligence. Need to add them to the slide. Sobering.
- And this looks like a FANTASTIC ride out of Trento: ridewithgps.com/routes/27552411
- Fixed the border menu so that it’s a toggle group
