
7:00 – 1:00 ASRC MKT
- Collective Agency and Cooperation in Natural and Artificial Systems (some chapters:)
- The Participatory Turn: A Multidimensional Gradual Agency Concept for Human and Non-human Actors
- Collective Agency and Cooperation in Natural and Artificial Systems
- Planning for Collective Agency
- Simulation as Research Method: Modeling Social Interactions in Management Science
- How Models Fail
- Requested the library copy. Request #426721
- Continuing with Suppressing the Search Engine Manipulation Effect
- One quick thought on Likert scales: If the selection is a slider, then we can see how the user interacts with the slider. This could let us see how decisive the users are. This could also be dome by looking at the area surrounding the radio buttons and tracking mouse motion and number of clicks in the area
- Introduction
- Recent research has shown that society’s growing dependence on ranking algorithms leaves our psychological heuristics and vulnerabilities susceptible to their influence on an unprecedented scale and in unexpected ways
- Experiments conducted on Facebook’s Newsfeed have demonstrated that subtle ranking manipulations can influence the emotional language people use
- Similarly, experiments on web search have shown that manipulating election-related search engine rankings can shift the voting preferences of undecided voters by 20% or more after a single search
- While “bias” can be ambiguous, our focus is on the ranking bias recently quantified by Kulshrestha et al. with Twitter rankings
- Our results provide support for the robustness of SEME and create a foundation for future efforts to mitigate ranking bias. More broadly, our work adds to the growing literature that provides an empirical basis to calls for algorithm accountability and transparency [24, 25, 90, 91] and contributes a quantitative approach that complements the qualitative literature on designing interventions for ranking algorithms
- Our results also suggest that proactive strategies that prevent ranking bias (e.g., alternating rankings) are more effective than reactive strategies that suppress the effect through design interventions like bias alerts. Given the accumulating evidence, we speculate that SEME may be impacting a wide range of decision-making, not just voting
- Related Work
- Order effects are among the strongest and most reliable effects ever discovered in the psychological sciences [29, 88]. These effects favorably affect the recall and evaluation of items at the beginning of a list (primacy) and at the end of a list (recency).
- There does not seem to be an equivalent primacy effect in maps that I can find
- online systems can: (1) provide a platform for constant, large-scale, rapid experimentation, (2) tailor their persuasive strategies by mining detailed demographic and behavioral profiles of users [1, 6, 9, 18, 121], and (3) provide users with a sense of control over the system that enhances their susceptibility to influence
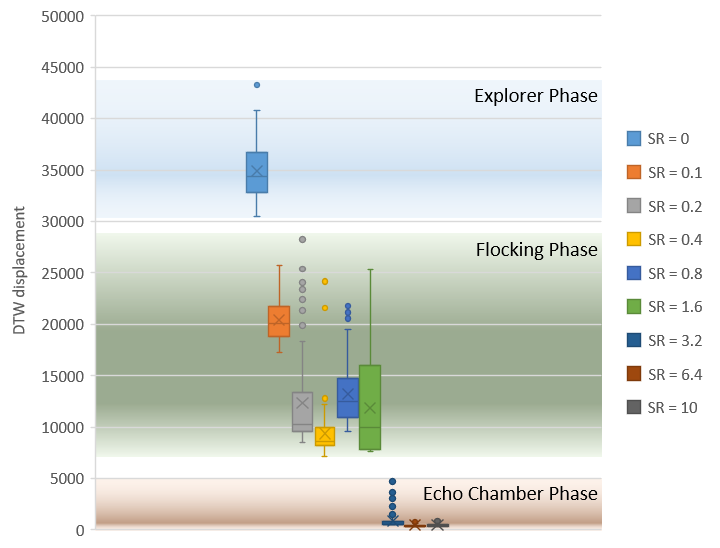
- Is this flocking from the flock’s perspective? Sort of an Ur-flock?
- This is that Trust/Awareness equation again
- A recent report involving 33,000 people found that search engines were the most trusted source of news, with 64% of people reporting that they trust search engines, compared to 57% for traditional media, 51% for online media, and 41% for social media [10]. Similarly, a 2012 survey by Pew found that 73% of search engine users report that “all or most of the information they find is accurate and trustworthy,” and 66% report that “search engines are a fair and unbiased source of information” [105].
- Suggestions for fostering resistance can be broken down into two primary strategies: (1) providing forewarnings [43, 49] and (2) training and motivating people to resist [79, 120].
- Interesting that alternate, non-ordered design approaches aren’t even mentioned
- Part of the reason that forewarnings work is explained by psychological reactance theory [12], which posits that when people believe their intellectual freedom is threatened – by exposing an attempt to persuade, for example – they react in the direction opposite that of the intended one
- In the context of online media bias, researchers have primarily explored methods for curbing the effects of algorithmic filtering and selective exposure [87, 96] rather than ranking bias [71]. In this vein, researchers have developed services that encourage users to explore multiple perspectives [97, 98] and browser extensions that gamify and encourage balanced political news consumption [19, 20, 86]. However, these solutions are somewhat impractical because they require users to adopt new services or exert additional effort.
- Order effects are among the strongest and most reliable effects ever discovered in the psychological sciences [29, 88]. These effects favorably affect the recall and evaluation of items at the beginning of a list (primacy) and at the end of a list (recency).
- Methods – Experiment Design
- To construct biased search rankings we asked four independent raters to provide bias ratings of the webpages we collected on an 11-point Likert scale ranging from -5 “favors Cameron” to +5 “favors Miliband”. We then selected the 15 webpages that most strongly favored Cameron and the 15 that most strongly favored Miliband to create three bias groups
- The query in the search engine was fixed as “UK Politics ‘David Cameron’ OR ‘Ed Miliband’”, and subjects could not reformulate it.
- On top of assignment to a bias group, subjects were randomly assigned to one of three alert experiments.We drew from the literature on decision-making and design intervention to implement so-called debiasing strategies for improving decision-making in the presence of biased information [39, 78, 82]. Specifically, we constructed and placed alerts in the search results produced by our mock search engine that provided forewarnings with salient graphics, autonomony-supportive language, and details on the persuasive threat
- Methods – Procedure
- After providing informed consent and answering basic demographic questions
- Do this and use this phrase!
- Subjects then rated the two candidates on 10-point Likert scales with respect to their overall impression of each candidate, how much they trusted each candidate, and how much they liked each candidate. Subjects also indicated their likelihood of voting for one candidate or the other on an 11-point Likert scale where the candidates’ names appeared at opposite ends of the scale and 0 indicated no preference, as well as on a binary choice question where subjects indicated who they would vote for if the election were held today.
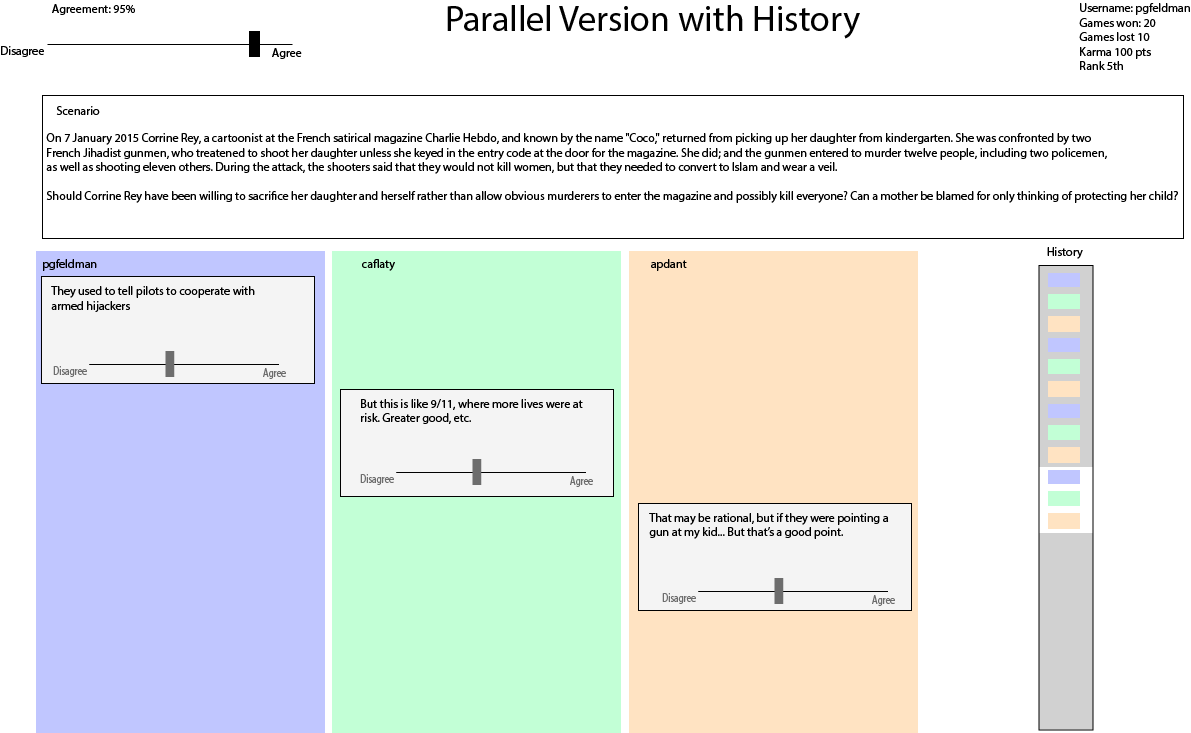
- This is a good way to set up the game. People read the dilemma, formulate an initial solution and their level of commitment to it. They can choose to make it “public” as their first statement or to keep it private and display a “no opinion” initial statement
- We asked: “While you were doing your online research on the candidates, did you notice anything about the search results that bothered you in any way?” and prompted subjects to explain what had bothered them in a free response format: “If you answered “yes,” please tell us what bothered you.” We did not directly ask subjects whether they had “noticed bias” to avoid the inflation of false positive rates that leading questions can cause
- After providing informed consent and answering basic demographic questions
- Methods – Participants
- We recruited 3,883 subjects between April 28, 2015 and May 6, 2015 on Amazon’s Mechanical Turk (AMT; https://mturk.com), a subject pool frequently used by behavioral, economic, and social science researchers [8, 13, 102]. We excluded from our analysis subjects who reported an English fluency level of 5 or less (on a scale of 1 to 10) (n=26)
- MTurk would be a good source of participants as well
- We recruited 3,883 subjects between April 28, 2015 and May 6, 2015 on Amazon’s Mechanical Turk (AMT; https://mturk.com), a subject pool frequently used by behavioral, economic, and social science researchers [8, 13, 102]. We excluded from our analysis subjects who reported an English fluency level of 5 or less (on a scale of 1 to 10) (n=26)
- Analysys – Search metrics
- Utilizing Kolmogorov-Smirnov (K-S) tests of differences in distributions, we found significant differences in the patterns of time spent on the 30 webpages between subjects in the no alert experiment (correlation with ranking: Spearman’s ρ = -0.836, P <0.001) and the high alert experiment (ρ = -0.654, P <0.001) (K-S D = 0.467, P <0.01), and between subjects in the low alert experiment (ρ = -0.719, P <0.001) and the high alert experiment (K-S D = 0.400, P <0.01)
- A way of looking for explore/exploit populations? And how fast can it be determined? Google uses a mechanism to stop an experiment once a confidence level is reached. Also, bootstrap would be good here
- Similarly, we also found significant differences in the patterns of clicks that subjects made on the 30 webpages between subjects in the no alert experiment (ρ = -0.865, P <0.001) and the high alert experiment (ρ = -0.795, P <0.001) (K-S D = 0.500, P <0.001), and between subjects in the low alert experiment (ρ = -0.876, P <0.001) and the high alert experiment (K-S D = 0.367, P <0.05)
- Among all conditions,we found that differences in the patterns of time and clicks on the individual rankings primarily emerged on the first SERP, but less so on the second, fourth, and fifth SERPs
- Utilizing Kolmogorov-Smirnov (K-S) tests of differences in distributions, we found significant differences in the patterns of time spent on the 30 webpages between subjects in the no alert experiment (correlation with ranking: Spearman’s ρ = -0.836, P <0.001) and the high alert experiment (ρ = -0.654, P <0.001) (K-S D = 0.467, P <0.01), and between subjects in the low alert experiment (ρ = -0.719, P <0.001) and the high alert experiment (K-S D = 0.400, P <0.01)
- Analysys – Attitude Shifts
- we found that the mean shifts in candidate ratings for the bias groups significantly converged on the mean shift found in the neutral group as the level of detail in the alerts increased, with high alerts creating higher convergence than low alerts
- As more diverse information is injected, populations compromise
- we found that the mean shifts in candidate ratings for the bias groups significantly converged on the mean shift found in the neutral group as the level of detail in the alerts increased, with high alerts creating higher convergence than low alerts
- Analysys – Vote Shifts
- Vote Manipulation Power (VMP)is the percent change in the number of subjects, in the two bias groups combined, who indicated that they would vote for the candidate who was favored by their search rankings. That is, if x and x ′ subjects in the bias groups said they would vote for the favored candidate before and after conducting the search, respectively, then VMP = (x ′ − x)/x.
- This could also be applied to the game to watch how votes for an outcome change over time. In the case of the game, new candidates can come into existence, so we need to watch for that.
- Vote Manipulation Power (VMP)is the percent change in the number of subjects, in the two bias groups combined, who indicated that they would vote for the candidate who was favored by their search rankings. That is, if x and x ′ subjects in the bias groups said they would vote for the favored candidate before and after conducting the search, respectively, then VMP = (x ′ − x)/x.
- Analysys – Bias Awareness
- We found 8.1% of subjects that showed awareness of the bias in the no alert experiment, a figure identical to the 8.1% awareness rate found by Eslami et al. in their audit of Booking.com [37], and similar to the 8.6% of subjects who showed awareness in the original study [30]. The percentage of subjects showing bias awareness increased to 21.5% in the low alert experiment, and 23.4% in the high alert experiment.
- Discussion
- However, despite the additional suppression of the high alerts, the lowest VMP was found among the neutral group subjects: rankings alternating between favoring the two candidates prevented SEME.
- This configuration forces users to “explore” more, within the context of a list affordance.
- As with previous research on SEME [30], and with research on attitude change and influence more generally [3, 72, 120], we found that subjects vary in their susceptibility to SEME, as well as in their responsiveness to the alerts, based on their personal characteristics (Figure 6 and Figure 7 in the Appendix).
- Explorer and exploiter populations?
- As more people turn to the internet for political news [85, 115], designing systems that can monitor and suppress the effects of algorithm biases, like ranking bias, will play an increasingly important role in protecting the public’s psychological vulnerabilities.
- And one of the big issues is finding bias at scale with domain independence
- Real-time automated bias detection could potentially be achieved by utilizing a Natural Language Processing (NLP) approach. One could utilize opinions [75], sentiment [99], linguistic patterns [109], word associations [14], or recursive neural networks [59] with human-coded data to classify biased language.
- Scale and domain problems.
- Discussion – Awareness of bias
- Awareness of ranking bias appears to suppress SEME only when it occurs in conjunction with a bias alert, perhaps because an alert is a kind of warning–inherently negative in nature.
- According to Moscovici, an inherently negative construct should reduce polarization movement.
- Awareness of ranking bias in the absence of bias alerts might increase VMP because people perceive the bias as a kind of social proof [111, 112], made all the more powerful because of the disproportionate trust people have in search rankings [10, 95, 105]. The user’s interpretation might be, “This candidate MUST be good, because even the search results say so.”
- Awareness of ranking bias appears to suppress SEME only when it occurs in conjunction with a bias alert, perhaps because an alert is a kind of warning–inherently negative in nature.
- However, despite the additional suppression of the high alerts, the lowest VMP was found among the neutral group subjects: rankings alternating between favoring the two candidates prevented SEME.
- Polarization Game
- Upgraded to PHP7. I went with the threadsafe version, which meant that I had to upgrade xdebug as well. and for some reason, I had to put the php_xdebug.dll file in the ext directory.
- And now I have typing!
- Proposal Work (1:00 – 5:00)
- Skimmed the RFI, thought of Rick Satava
- Building out template
- Wrote the first pass with Aaron









You must be logged in to post a comment.