
7:00 – 5:00 ASRC MKT
- Overview (Research Browser-ish) and their blog. Here it is working with the serendipity corpus:

- Google is doing a lot to map art with ML, but it lacks a sense of meaning
- Found Visualization of Topic-Sentiment Dynamics in Crowdfunding Projects. Put it in the phase 2 lit review
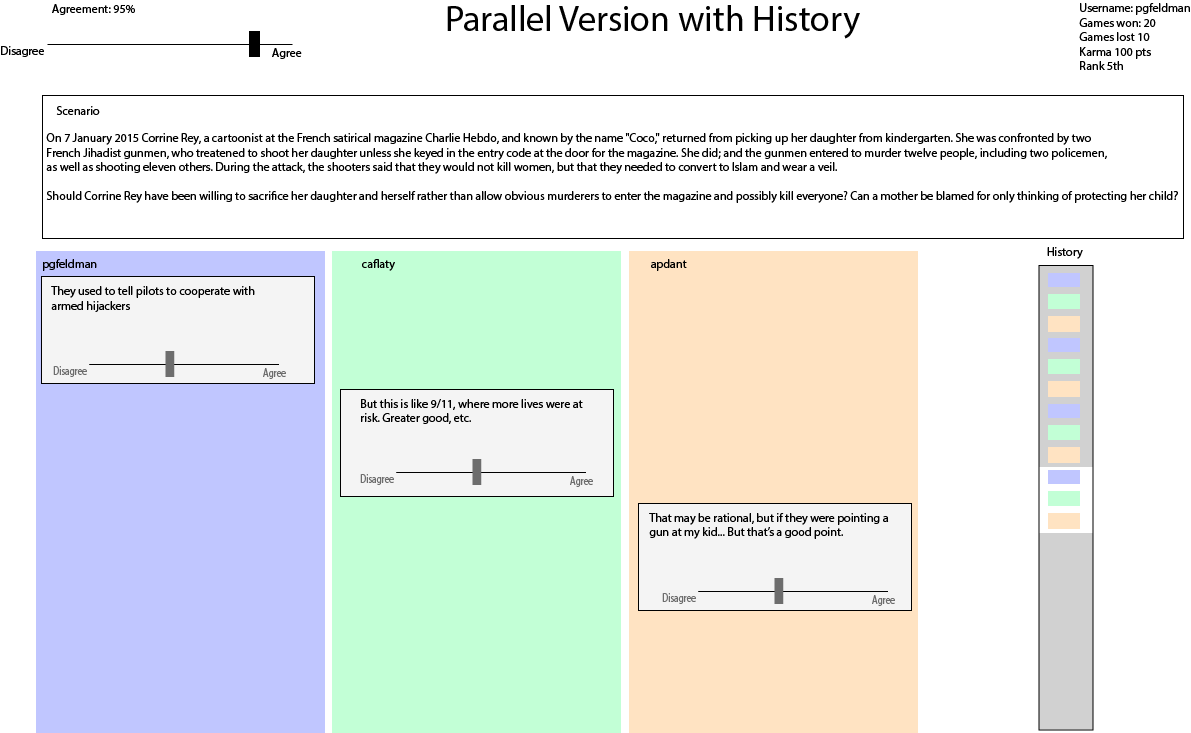
- It shouldn’t be called the Polarization Game. Need a title. Maybe something from myth?
- Continuing with Suppressing the Search Engine Manipulation Effect
- In the discussion of Order effects, they talk about primacy effects of lists. A quick Scholar search didn’t turn up any studies of primacy effects of maps (like maybe preference for the local area), but some poking around in this space turned up this: Maps of Bounded Rationality: Psychology for Behavioral Economics
- Back to game design. Having a problem with integrating PHPUnit and RedbeanPHP. Getting this message when I have two or more tests to run: RedBeanPHP\RedException : A database has already been specified for this key.
- The answer was to add –process-isolation to the TestRunner args:
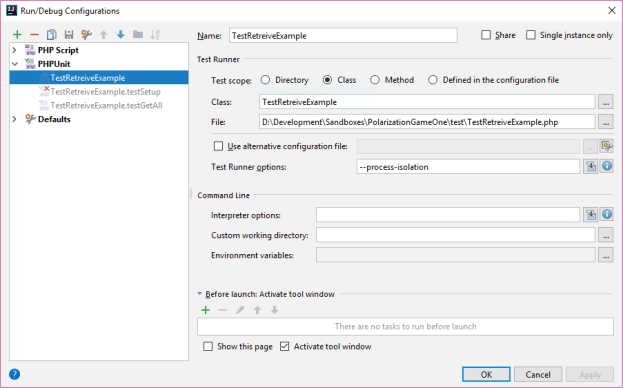
- BTW, clicking on the blue “info” box at the right of the field will bring up the args allowed
- I went looking for a way to #ifdef some basic exercising code that I like to add at the bottom of php files. Couldn’t find anything, but I figured out this pattern for file SomeClass.php:
class SomeClass { public function doStuff(){echo "stuff done!;} } if(strpos($_SERVER['PHP_SELF'], "SomeClass.php" )){ printf("running from %s\n", $_SERVER['PHP_SELF']); $sc = new SomeClass(); $sc->doStuff(); } - This will only run if the file containing the code is executed directly. It won’t run when called by phpUNIT, for example
- The answer was to add –process-isolation to the TestRunner args:


4:00 – 4:30
- Chat with Stan about ML to recognize signal outliers. We talked about GAs for a while, and I sent him Zhenping’s ppt.







You must be logged in to post a comment.