7:00 – 8:00 Research
- Finishing up poster?
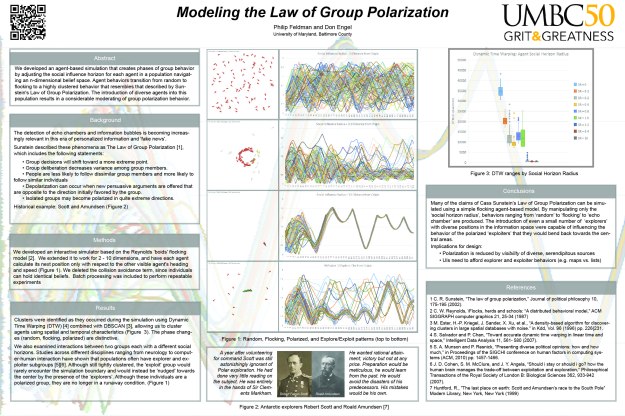
- Starting submission for Phys Rev E, based on my notes here.
- Created account
- Created ORCID account
- Started submission. Errors!There were problems with the following fields:
- AllExploit_SI0.0.psd: Classification description value must be selected for each file and cannot be left unknown.
- 90_ExploitR10_10_ExploreR0.psd: Classification description value must be selected for each file and cannot be left unknown.
- polarized.jpg: Classification description value must be selected for each file and cannot be left unknown.
- clusterMembership.png: Classification description value must be selected for each file and cannot be left unknown.
- toolScreenshot.png: Classification description value must be selected for each file and cannot be left unknown.
- ModelingGroupPolarization2col.pdf: Classification description value must be selected for each file and cannot be left unknown.
- exploring.jpg: Classification description value must be selected for each file and cannot be left unknown.
- ModelingGroupPolarization.pdf: Classification description value must be selected for each file and cannot be left unknown.
- psheader.txt: Classification description value must be selected for each file and cannot be left unknown.
- influenced.jpg: Classification description value must be selected for each file and cannot be left unknown.
- ExplorerPDF.png: Classification description value must be selected for each file and cannot be left unknown.
- ModelingGroupPolarization.synctex.gz: Classification description value must be selected for each file and cannot be left unknown.
- AllExploit_SI10.0.jpg: Classification description value must be selected for each file and cannot be left unknown.
- ModelingGroupPolarizationDraft.pdf: Classification description value must be selected for each file and cannot be left unknown.
- flocking.jpg: Classification description value must be selected for each file and cannot be left unknown.
- DTWmatrix.png: Classification description value must be selected for each file and cannot be left unknown.
- ModelingGroupPolarization.log: Classification description value must be selected for each file and cannot be left unknown.
- ModelingGroupPolarization.dvi: Classification description value must be selected for each file and cannot be left unknown.
- AllExploit_SI10.0.psd: Classification description value must be selected for each file and cannot be left unknown.
- ModelingGroupPolarization.blg: Classification description value must be selected for each file and cannot be left unknown.
- 90_ExploitR10_10_ExploreR0.jpg: Classification description value must be selected for each file and cannot be left unknown.
- AllExploit_SI0.2.psd: Classification description value must be selected for each file and cannot be left unknown.
- SimilarPaths.png: Classification description value must be selected for each file and cannot be left unknown.
- RevTex41_example.aux: Classification description value must be selected for each file and cannot be left unknown.
- label 0 is duplicated
- ModelingGroupPolarization.aux: Classification description value must be selected for each file and cannot be left unknown.
- revtex41_template.blg: Classification description value must be selected for each file and cannot be left unknown.
- RevTex41_example.blg: Classification description value must be selected for each file and cannot be left unknown.
- DTWclusters.png: Classification description value must be selected for each file and cannot be left unknown.
- Main text file is required
9:00 – 5:00, 6:00, 7:30 BRC








You must be logged in to post a comment.