Aaron, Panos and I had a walkthrough of Jarod’s SLR. It needs a lot of organizing and framing. The information is all there, but it’s more like a collection of notes than a paper.
SBIRs
LAIC meeting went well, but it got a little shaky. The upshot is that we will probably demo the navigator app first, and the builder app second. The use case can still be rules of engagement, where we can show a script unfolding where the rules are followed (staying close) in response to an event, and the rules being disregarded. Then we can show how the map is made.
Need to start wiring up the text to the graph
Working out adding seeds or topics to groups and getting details
rliable is an open-source Python library for reliable evaluation, even with a handful of runs, on reinforcement learning and machine learnings benchmarks.
Deep reinforcement learning (RL) algorithms are predominantly evaluated by comparing their relative performance on a large suite of tasks. Most published results on deep RL benchmarks compare point estimates of aggregate performance such as mean and median scores across tasks, ignoring the statistical uncertainty implied by the use of a finite number of training runs. Beginning with the Arcade Learning Environment (ALE), the shift towards computationally-demanding benchmarks has led to the practice of evaluating only a small number of runs per task, exacerbating the statistical uncertainty in point estimates. In this paper, we argue that reliable evaluation in the few run deep RL regime cannot ignore the uncertainty in results without running the risk of slowing down progress in the field. We illustrate this point using a case study on the Atari 100k benchmark, where we find substantial discrepancies between conclusions drawn from point estimates alone versus a more thorough statistical analysis. With the aim of increasing the field’s confidence in reported results with a handful of runs, we advocate for reporting interval estimates of aggregate performance and propose performance profiles to account for the variability in results, as well as present more robust and efficient aggregate metrics, such as interquartile mean scores, to achieve small uncertainty in results. Using such statistical tools, we scrutinize performance evaluations of existing algorithms on other widely used RL benchmarks including the ALE, Procgen, and the DeepMind Control Suite, again revealing discrepancies in prior comparisons. Our findings call for a change in how we evaluate performance in deep RL, for which we present a more rigorous evaluation methodology, accompanied with an open-source library rliable, to prevent unreliable results from stagnating the field.
Put together spreadsheets for French, Chinese, Mexican and American LIWC results
4:15 Meeting
SBIRs
Promoting generic params objects to their own classes with default values
Working out seeds and visited topics – done!
Getting the adding and using of topic groups. This means adding a method that supports callbacks to external (parent) code, so that I can keep the two components coordinated
Working on getting the LWIC data organized – done!
SBIRs
Sprint Planning
Finished(?) with the parameter objects. I may change the file to MapsDataObjects and inherit from the serializing base class once I see how everything works with this approach.
Created PickleDataObjectBase and refactord. Loading and saving seems to be working fine
Ok, back to GraphBuilder. Added save, load, and exit callback attributes that can be passed a function from the main application. That should let me get the data out of the ProjectWindow class
See what LWIC data I have and then get the rest analyzed
SBIRs
Sprint demos
Working on being able to pass complex data objects nicely. Reworked everything to use pickle, which serializes objects nicely, and uses binary strings, which should be more compact, too.
Social media platforms attempting to curb abuse and misinformation have been accused of political bias. We deploy neutral social bots who start following different news sources on Twitter, and track them to probe distinct biases emerging from platform mechanisms versus user interactions. We find no strong or consistent evidence of political bias in the news feed. Despite this, the news and information to which U.S. Twitter users are exposed depend strongly on the political leaning of their early connections. The interactions of conservative accounts are skewed toward the right, whereas liberal accounts are exposed to moderate content shifting their experience toward the political center. Partisan accounts, especially conservative ones, tend to receive more followers and follow more automated accounts. Conservative accounts also find themselves in denser communities and are exposed to more low-credibility content.
We are very pleased to announce the release of scikit-learn 1.0! The library has been stable for quite some time, releasing version 1.0 is recognizing that and signalling it to our users. This release does not include any breaking changes apart from the usual two-release deprecation cycle. For the future, we do our best to keep this pattern.
Can a poem be alive? Can we drink poetry?In this event, we explore these ideas through a bioart project. Raaz is a multimedia installation with a poetry-infused bottle of wine surrounded by audio-visual representations of a 14th-century Persian poem on transformation. The transgenic yeast used to make the wine included an encoding of the poem. The installation creates a meditative space surrounded by microscopic images of the yeast and ambient audio that combines a reading of the poem, its Morse code, and an original bass flute melody.During the event you can experience Raaz in-person, hear about the artists’ process and motivations in their opening talk, and participate in a hands-on agar art activity for individuals of all ages!
It’s only just Fall, but the rains came through yesterday and the weather has shifted. The mornings are chilly and the air is drier.
I’m also not getting any traction on the book, so I have to figure out what to do next. Maybe a more academic press? Do you need an agent for that? Anyway, I’m procrastinating on doing any research-y things today and am just going to write some nice therapeutic code.
SBIRs
Figured out the problem I was having with scaled and scrolled canvas. The trick is to use the tk.Canvas.canvasx(event.x) and tk.Canvas.canvasy(event.y) calls, which map the window mouse X,Y points to the (larger) canvas coordinates:
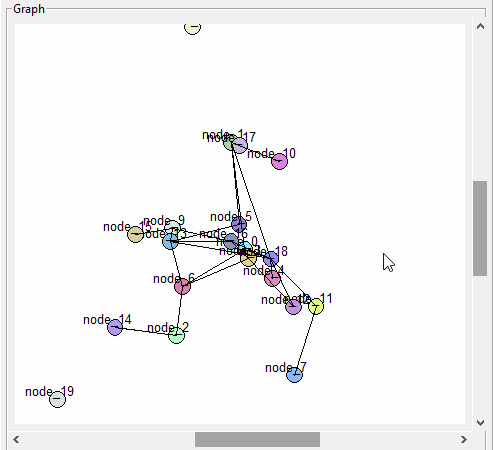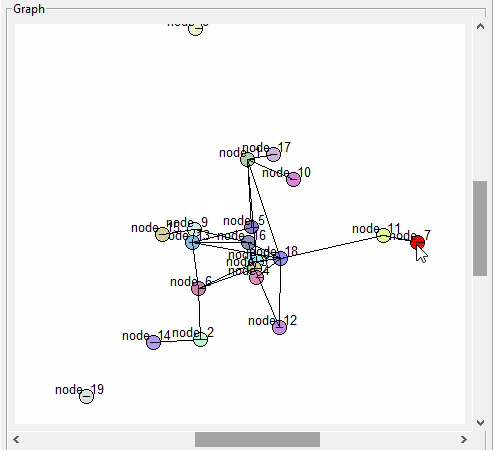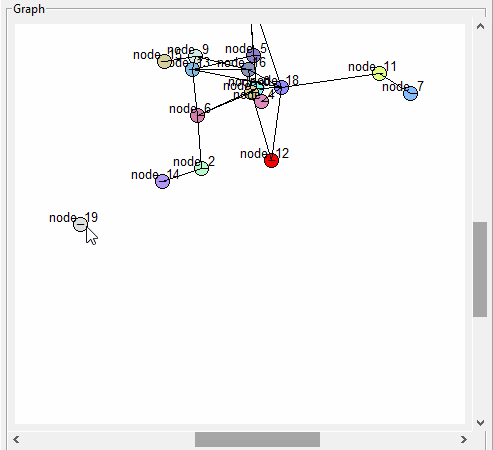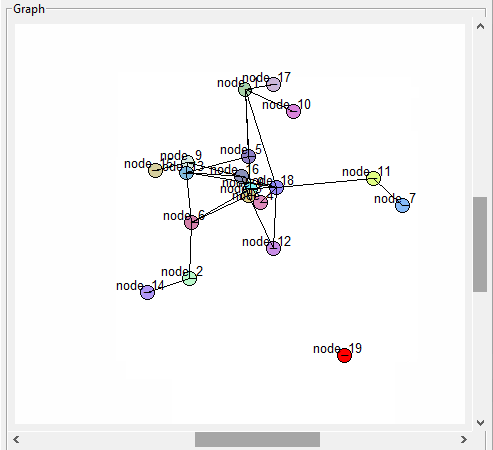
Still having a bit of trouble clicking on some nodes though…
The other thing that I realize is that I think I want to send data around in JSON files so that the transition to a webapp is easier . Refactoring to support this.
The emergence of a field devoted to researching, and countering, influence operations is something I have watched closely. In 2014, I channeled a fascination with propaganda from the two world wars into researching how the phenomena was changing in a digital age. In those early days, there were few places to find work researching influence operations. The career paths were mostly in academia or in the military or intelligence services. Marrying the two, I chose to pursue a doctorate in war studies. Along the way, I have worked with tech companies, militaries, civil society groups, and governments, learning how each understands and works to counter (and sometimes run) influence operations.
Meeting yesterday. One of the things that came up was that the GPT struggled to train against the French corpora more than the others as measured by out-of-band responses. Need to see what’s going on here. Also, does this show up in LWIC?
SBIRs
9:15 standup – done
11:00 LAIC weekly – went well
12:00 Performance Engineering presentation – missed it
2:00 Adversarial learning weekly – Rukan is working on other things right now, so it was more of a chat. We spent a good deal of time talking about the Pandemonium Cognitive model.
3:30 Monthly Data Science tagup. Cool presentation on LANDSAT
4:00 Phone interview – That was fun!
GUI
Trying to figure out why the scrollbars mess up the node picking
Got the data from the ground truth and runs. Need to combine, then do a rollup of American, French, Chinese, and Mexican
4:14 Meeting
SBIRs
More GUI. Need to be able to drag selected nodes around. Got it working well enough for the first pass. I need to fix it so the link back to the node is also moved:
Radical ideologies can and do inevitably interconnect historically; the far-right’s fascination with radical forms of Islam is not a new phenomenon and while it may have been accentuated by militant Islamists’ fame, we cannot overlook these movements deep historic roots and how historical fragments, real or imagined, intersect to inspire elements of the far-right today.
SBIR(s)
Helped Aaron yesterday with getting formatting right on the report
Stand up today. Mention funding. Come to think of it, add an approximate token price calculator for a session. That info may be in the JSON file that comes back from OpenAI
Add a Run/Stop button to the graph display (done!). Will still need to be able to drag around nodes
Zoom turned out to be a bit tricky, because the lines were not being scaled and translated along with the nodes. TO do this, I needed to use the screen coordinates for the nodes, which I got like this:
Which I then combined with the global(!) positions of the nodes to get the combined effect:
self.x += self.dx * elapsed
self.y += self.dy * elapsed
self.cd.canvas.move(self.id, self.dx * elapsed, self.dy * elapsed) # global coords
self.set_screen_coords() # get local coords
for n, l in self.neighbor_dict.items():
self.cd.canvas.coords(l, self.cx, self.cy, n.cx, n.cy) #use local coords
The French, Chinese, and Mexican reviews are still cooking. It looks like about 8 hours more to finish generation, then the sentiment. So everything will probably be done tomorrow? Then I can run the analysis, and probably start writing.
Also, in the app, I want to try hooking the system to the local GPT models, and try to reproduce the chess board.
WeightWatcher(WW): is an open-source, diagnostic tool for analyzing Deep Neural Networks (DNN), without needing access to training or even test data. It can be used to:
analyze pre/trained pyTorch, Keras, DNN models (Conv2D and Dense layers)
monitor models, and the model layers, to see if they are over-trained or over-parameterized
predict test accuracies across different models, with or without training data
detect potential problems when compressing or fine-tuning pretrained models
layer warning labels: over-trained; under-trained
GPT Agents
Finished extracting French, Chinese and Mexican reviews and ran the sentiment analyzer
Finished creating the French, Chinese, and Mexican models (50k reviews, 6 epochs). Need to run them next
I want to try WW (above) on the stars models and see what it says
Submitted the actual dissertation to the copyright office.
GPT Agents
Working on training models for French, Chinese, and Mexican restaurants on the corpora I built yesterday. Need to extract 10k items of ground truth while training
How do people learn the large, complex web of social relations around them? We test how people use information about social features (such as being part of the same club or sharing hobbies) to fill in gaps in their knowledge of friendships and to make inferences about unobserved friendships in the social network. We find the ability to infer friendships depends on a simple but inflexible heuristic that infers friendship when two people share the same features, and a more complex but flexible cognitive map that encodes relationships between features rather than between people. Our results reveal that cognitive maps play a powerful role in shaping how people represent and reason about relationships in a social network.
Hmm. Can’t download the PDF or read the full article
The spread of misinformation is a global phenomenon, with implications for elections, state-sanctioned violence, and health outcomes. Yet, even though scholars have investigated the capacity of fact-checking to reduce belief in misinformation, little evidence exists on the global effectiveness of this approach. We describe fact-checking experiments conducted simultaneously in Argentina, Nigeria, South Africa, and the United Kingdom, in which we studied whether fact-checking can durably reduce belief in misinformation. In total, we evaluated 22 fact-checks, including two that were tested in all four countries. Fact-checking reduced belief in misinformation, with most effects still apparent more than 2 weeks later. A meta-analytic procedure indicates that fact-checks reduced belief in misinformation by at least 0.59 points on a 5-point scale. Exposure to misinformation, however, only increased false beliefs by less than 0.07 points on the same scale. Across continents, fact-checks reduce belief in misinformation, often durably so.
GPT Agents
Finished reading in Andreea’s data. I’m going to add a column called ‘test’, that has some text in it to judge the quality of training. I’m going to start out with ‘ten’, ‘twenty’, ‘thirty’, and ‘forty’, which will show up in those percentages. We’ll be able to compare the percentages in the generated and the original. Done with the original
Create corpora and start training model.
Built corpora
Training!
Done! Need to verify the test percentages
[[[month:August location:Auckland text:@rnz_news @NZStuff @minhealthnz @NewshubNZ @jacindaardern @simonjbridges @nzlabour I have a few theories but they are completely illogical. My theory is that many in government and opposition are too trusting, while many in the media are too partisan. #covid19nz #covid19_nz #nzpol, test:twenty]]][[[month:August location:New Zealand text:Dr Liz Gordon: NZ’s Covid-19 response a failure
[[[month:April location:New Zealand text:“As they travel around the world, as we go back to the U.S., it is critical that they be able to meet with health officials and other trusted advisers to update their status”. https://t.co/7kZk6HtRcV #covid19nz #Healthandsafety, test:forty]]][[[month:April location:Wellington City, New Zealand text:It's getting harder and harder to resist the temptation to throw shade at the PM's leadership. She's deliberately and deliberately slipping up
[[[month:April location:Wellington, New Zealand text:New Zealand will now have a COVID-19 emergency alert system. A system based on scientific certainty, based on best informed research. The sooner we use science the sooner we’ll all get back to normal life. This is a global challenge. https://t.co/YFpI6zWgv7 #coronavirus #COVID19nz, test:forty]]][[[month:April location:Wellington text:New Zealand is now in #COVID19nz mode. The system works
[[[month:April location:New Zealand text:A month of #Covid19nz has taught me to trust #SocialDistancing and not to accept #selfishness. So much of #NZtourism comes from poor, vulnerable, and elderly people. If you or someone you know has #Covid19NZ symptoms, please report them to contact tracing at 0800 451 9453 https://t.co/Jw2i0U8Jqn, test:forty]]][[[month:April location:New Zealand text:@MatthewHootonNZ @TheAMShowNZ
[[[month:May location:Auckland, NZ text:#coronavirusnz #COVID19nz One of the new covid-19 cases reported in Queenstown this week is a case in the community. https://t.co/XmqEZd2aDw, test:forty]]][[[month:May location:Muriwai, Aotearoa text:Māori Health Minister Māori Party @RikkiRakaka @nzlabour https://t.co/gwqEZqNrA7 #COVID19 #CO
[[[month:May location:Wellington, New Zealand text:This is a welcome relief to many. Here's an idea: don't just sell as much as you can. Instead, take out the cash and start collecting. #COVID19nz, test:forty]]][[[month:May location:0 text:Can't say my children are very good at math - and in math classes I find they get lots of confused - but when I read someone ask them "how many years of age do they still live with?", they instantly burst into laughter. #nzpol #covid19nz
[[[month:April location:Auckland, New Zealand text:Great article by @Kiwi_Country to explain the importance of #COVID19nz and how to use your personal details to protect your community. Great info in the article https://t.co/v9L0GtX8z3 https://t.co/s3Nm3z3qCZ, test:ten]]][[[month:April location:Auckland, New Zealand text:My thoughts: #covid19NZ #NewZealandLockdown https://t.co
[[[month:June location:Aotearoa, New Zealand text:?♂️ #Covid_19 #COVID19nz https://t.co/Nb8Cq8xFZJ, test:forty]]][[[month:June location:Te Upoko o Te Ika a Maui text:Māori #COVID19nz #lockdownnz https://t.co/tS9QjkFZhM, test:forty]]][[[month:June location:Christchurch City, New Zealand text:What
[[[month:June location:Auckland, New Zealand text:It's important to be clear about the amount of work we can do to safeguard the community and the health and wellbeing of NZers. Read this: https://t.co/vh0MxwKlG7 #COVID19nz, test:forty]]][[[month:June location:New Zealand text:“All the good work that the Govt's emergency plans have done” @SiouxsieW #covid19nz https://t.co/fDZFdZJ0
[[[month:March location:Wellington City, New Zealand text:RT TheDailyBlogNZ "Life in Lock Down: Day 2 | Frank Macskasy - The Daily Blog https://t.co/4tP8dZZWmA #nzpol #covid19nz https://t.co/HmDw5BcE5j", test:forty]]][[[month:March location:0 text:Life in Lock Down: Day 2 | Frank Macskasy - The Daily Blog https://t.co/xWZFyLk3
[[[month:April location:New Zealand text:MEDIA WATCH: Jacinda destroys Duncan Garner | The Daily Blog https://t.co/Hk5VZ9oTkC #nzpol #covid19nz https://t.co/p7tMkLH9Rk", test:ten]]][[[month:April location:New Zealand text:GUEST BLOG: Geoff Simmons – The Price of Citizenship | The Daily Blog https://t.co/JKc0NqEqH #nzpol #covid19nz https://t.
4:15 UMBC Meeting. We’ll try French, Chinese, (and Mexican) to see if the ratings change















You must be logged in to post a comment.