
7:00 – 3:30 ASRC GOES
- Russian Trolls Aren’t Actually Persuading Americans on Twitter, Study Finds
- New research highlights a surprising barrier to hacking our democracy: filter bubbles
- The Duke Polarization Lab is a group of seven faculty members, 21 graduate students, and four undergraduate students who are working to develop new technology to combat political polarization online.
- Source Article: Assessing the Russian Internet Research Agency’s impact on the political attitudes and behaviors of American Twitter users in late 2017
- There is widespread concern that Russia and other countries have launched social-media campaigns designed to increase political divisions in the United States. Though a growing number of studies analyze the strategy of such campaigns, it is not yet known how these efforts shaped the political attitudes and behaviors of Americans. We study this question using longitudinal data that describe the attitudes and online behaviors of 1,239 Republican and Democratic Twitter users from late 2017 merged with nonpublic data about the Russian Internet Research Agency (IRA) from Twitter. Using Bayesian regression tree models, we find no evidence that interaction with IRA accounts substantially impacted 6 distinctive measures of political attitudes and behaviors over a 1-mo period. We also find that interaction with IRA accounts were most common among respondents with strong ideological homophily within their Twitter network, high interest in politics, and high frequency of Twitter usage. Together, these findings suggest that Russian trolls might have failed to sow discord because they mostly interacted with those who were already highly polarized. We conclude by discussing several important limitations of our study—especially our inability to determine whether IRA accounts influenced the 2016 presidential election—as well as its implications for future research on social media influence campaigns, political polarization, and computational social science.
- This makes sense to me, as we are most responsive to those that we align with and least responsive to those that we are opposed to. The problem is that I don’t think the Russians are interested in persuasion. They are interested in sowing discord using polarization, which this technique works splendidly for
- Dissertation – finished the resilience section
- Evolver. Undo all the indexing crap – done! And it’s working. Here’s the chart of the exhaustive [X Y] search (1600 possibilities), vs the evolved [X Y Zfunc] search (640,000 possibilities). And it’s actually 30 evolution steps:
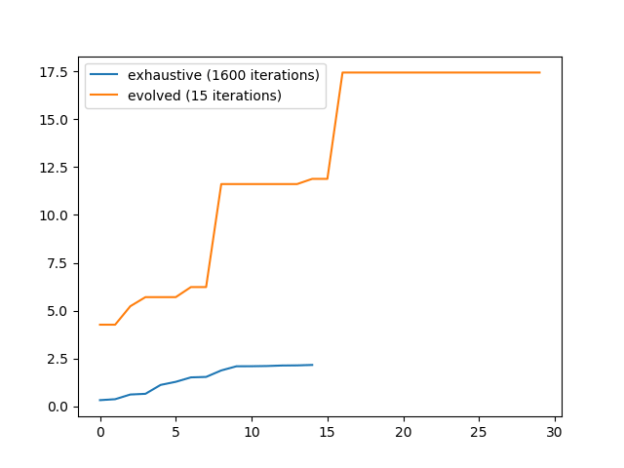
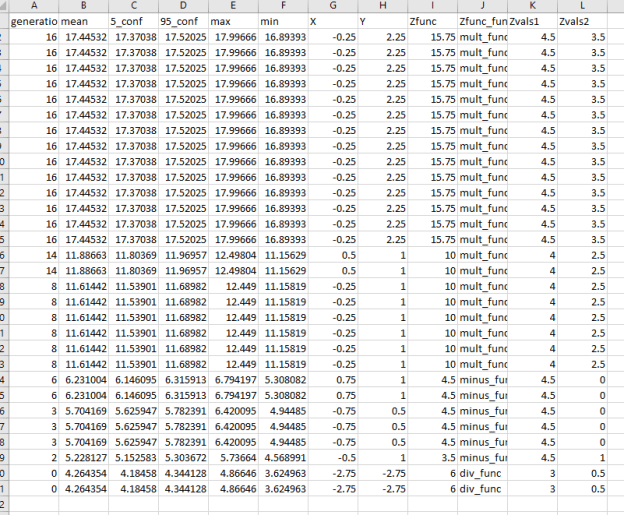
- Here’s all the steps. The most recent is on top. Note that it discovers the mult function early on and never looks back:
- Now I need to fix all the code I broke and write some documentation





You must be logged in to post a comment.