7:00 – 3:00 ASRC GOES
- Simulation for training ML at UMD: Improved simulation system developed for self-driving cars
- University of Maryland computer scientist Dinesh Manocha, in collaboration with a team of colleagues from Baidu Research and the University of Hong Kong, has developed a photo-realistic simulation system for training and validating self-driving vehicles. The new system provides a richer, more authentic simulation than current systems that use game engines or high-fidelity computer graphics and mathematically rendered traffic patterns.
- Dissertation
- Send out email setting the date/time to Feb 21, from 11:00 – 1:00. Ask if folks could move the time earlier or later for Wayne – done
- More human study – I think I finally have a good explanation of the text convergence.
- Maybe work of the evolver?
- Add nested variables
- Look at keras-tuner code to see how GPU assignment is done
- So it looks like they are using gRPC as a way to communicate between processes?

- I mean, like separate processes, communicating via ports

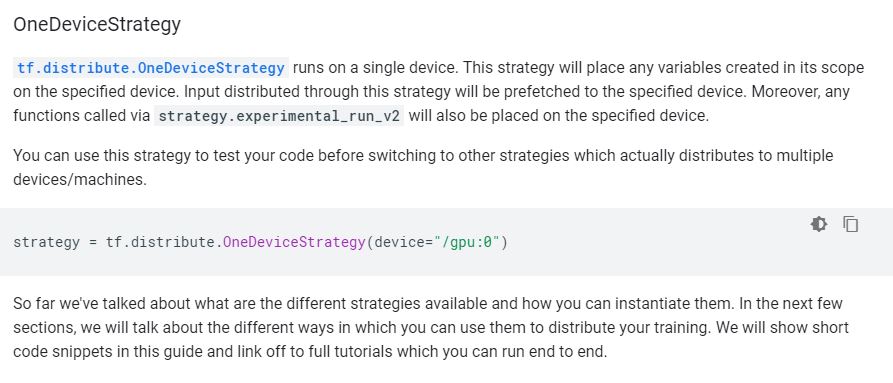
- Oh. This is why. From the tf.distribute documentation

- No – wait. This is from the TF distributed training overview page:
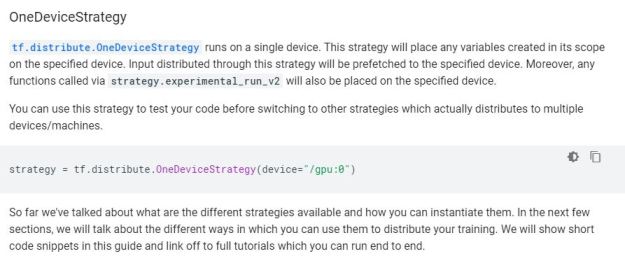
- And that seems to straight up work (assuming that multiple GPUs can be called. Here’s an example of training:
strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") with strategy.scope(): model = tf.keras.Sequential() # Adds a densely-connected layer with 64 units to the model: model.add(layers.Dense(sequence_length, activation='relu', input_shape=(sequence_length,))) # Add another: model.add(layers.Dense(200, activation='relu')) model.add(layers.Dense(200, activation='relu')) # Add a layer with 10 output units: model.add(layers.Dense(sequence_length)) loss_func = tf.keras.losses.MeanSquaredError() opt_func = tf.keras.optimizers.Adam(0.01) model.compile(optimizer= opt_func, loss=loss_func, metrics=['accuracy']) noise = 0.0 full_mat, train_mat, test_mat = generate_train_test(num_funcs, rows_per_func, noise) model.fit(train_mat, test_mat, epochs=70, batch_size=13) model.evaluate(train_mat, test_mat) model.save(model_name)And here’s an example of predicting
strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") with strategy.scope(): model = tf.keras.models.load_model(model_name) full_mat, train_mat, test_mat = generate_train_test(num_funcs, rows_per_func, noise) predict_mat = model.predict(train_mat) # Let's try some immediate inference for i in range(10): pitch = random.random()/2.0 + 0.5 roll = random.random()/2.0 + 0.5 yaw = random.random()/2.0 + 0.5 inp_vec = np.array([[pitch, roll, yaw]]) eff_mat = model.predict(inp_vec) print("input: pitch={:.2f}, roll={:.2f}, yaw={:.2f} efficiencies: pitch={:.2f}%, roll={:.2f}%, yaw={:.2f}%". format(inp_vec[0][0], inp_vec[0][1], inp_vec[0][2], eff_mat[0][0]*100, eff_mat[0][1]*100, eff_mat[0][2]*100))
- So it looks like they are using gRPC as a way to communicate between processes?
- Look at TF code to see if it makes sense to add to the project. Doesn’t look like it, but I think I can make a nice hyperparameter/architecture search API using this, once validated
- Mission Drive meeting and demo – went ok. Will Demo at NSOF tomorrow