
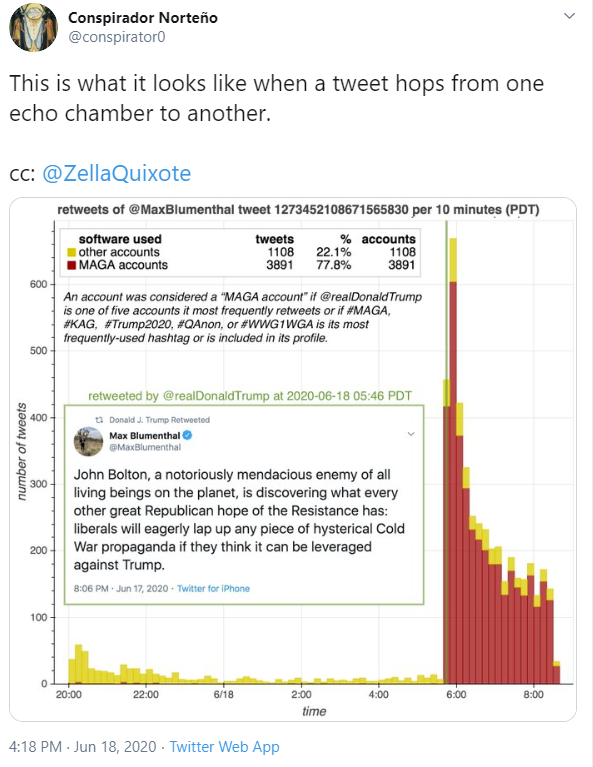
My guess it that barring interference of some kind all US cities will have something like what’s going on in Portland by election day
GPT-2 Agents
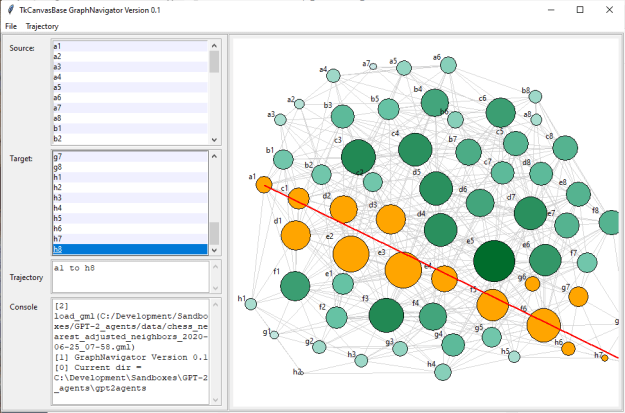
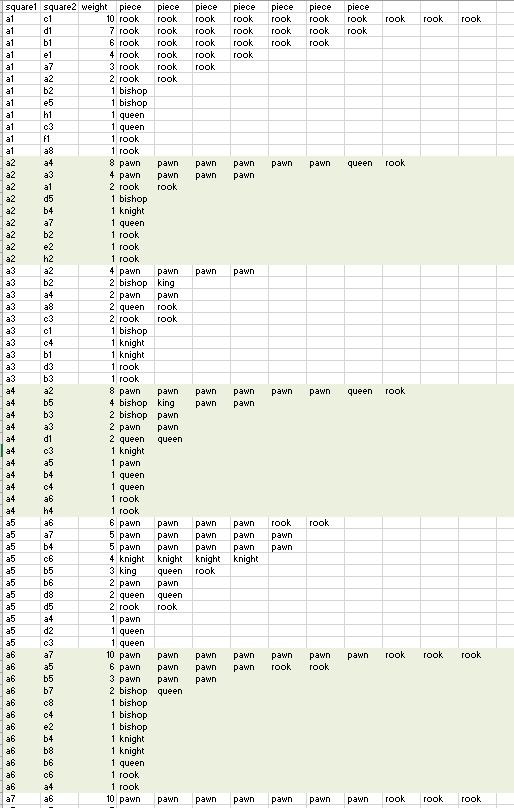
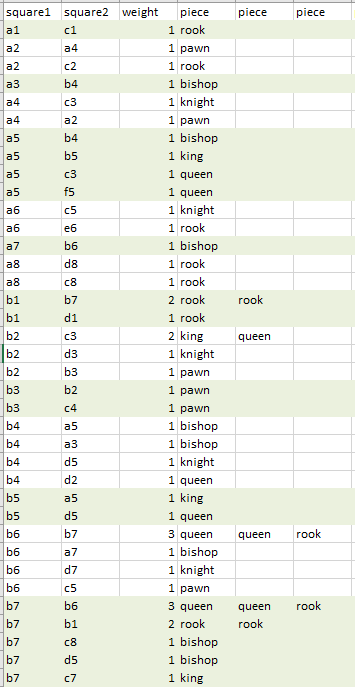
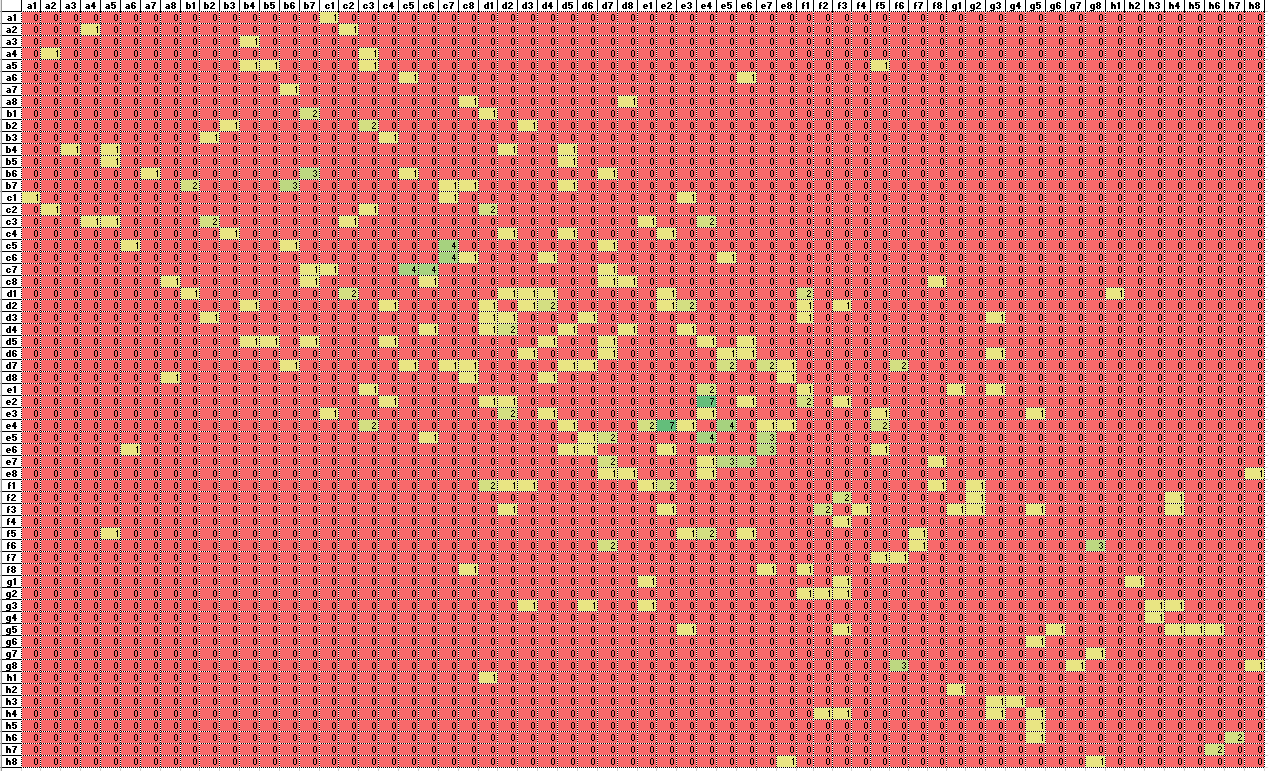
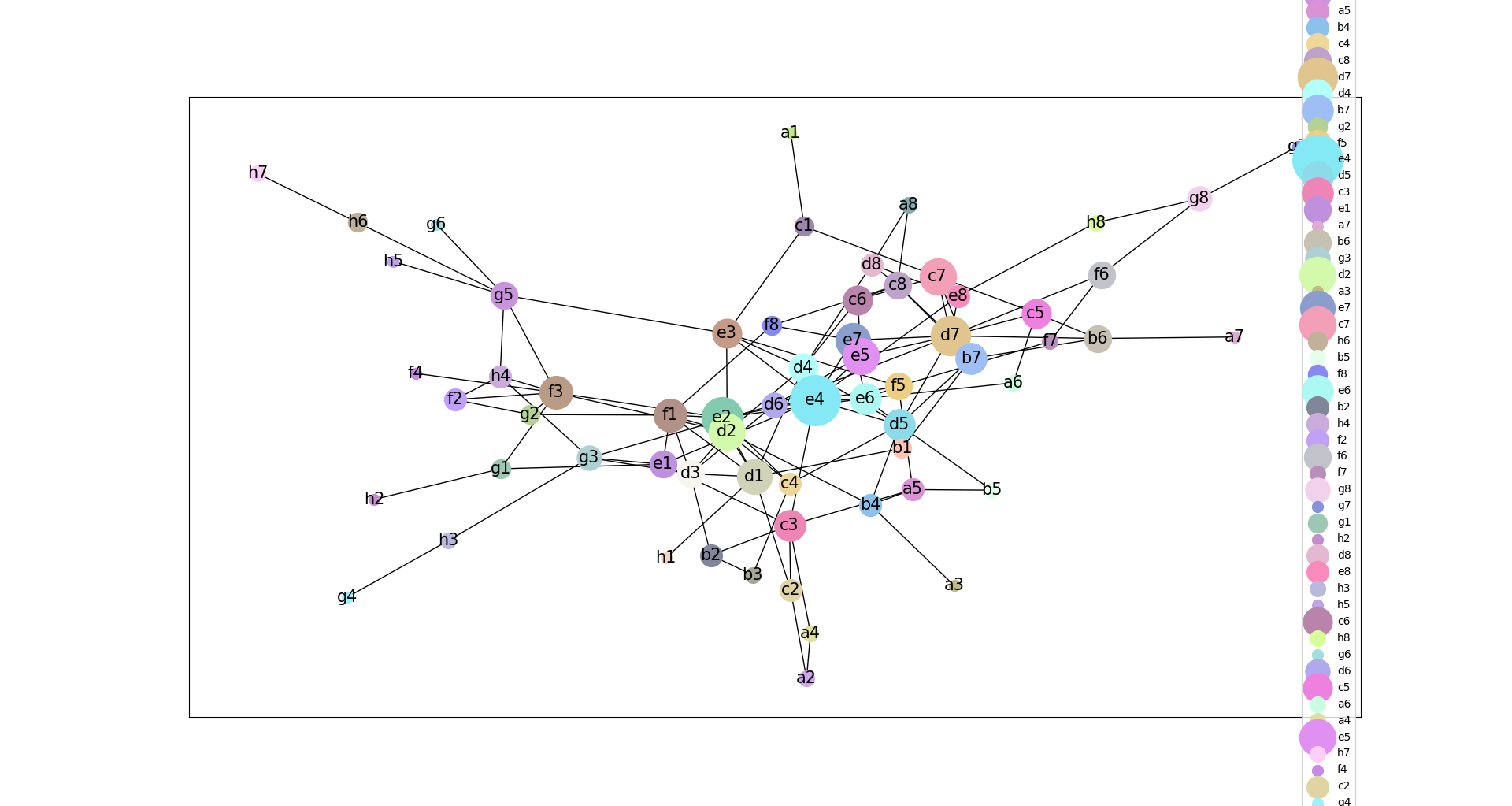
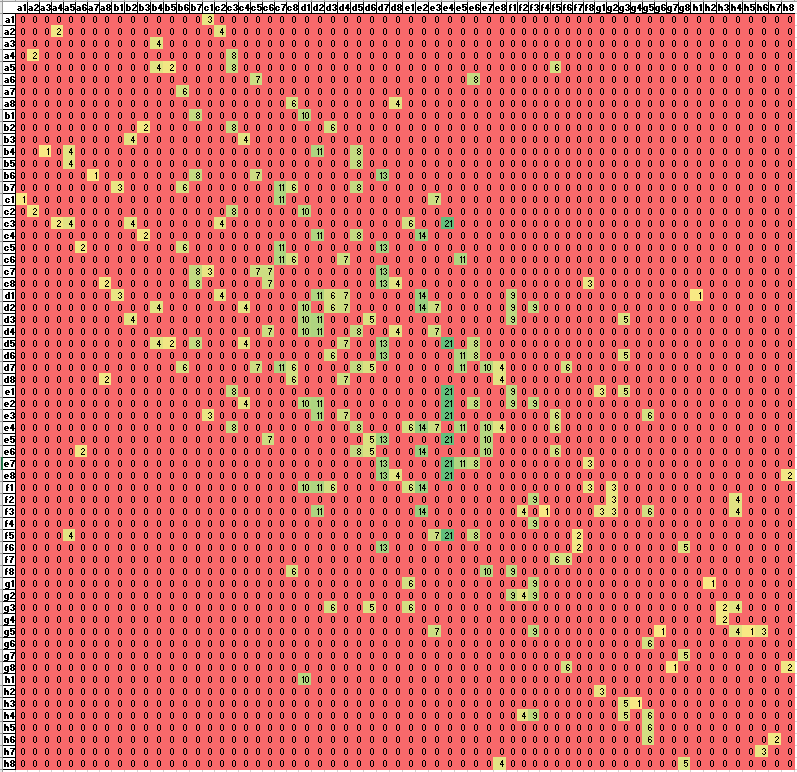
- Back from break, and thinking about what to do next. I think the first thing to do is simply gather more data from the model. Right now I have about 1,500 GPT-2 moves and about 190,000 human moves. Increasing the number of predictions to 1,000 by adding a batch size value. Otherwise I got out-of-memory errors.
- I had started the run in the morning and was almost done when a power failure hit and the UPS didn’t work. Ordered a new UPS. Tried to be clever about finishing off the last piece of data but left in the code that truncated the table. Ah, well. Starting over.
- Next is to adjust the queries so that the populations are more similar. The GPT-2 moves come from the following prompts:
probe_list = ['The game begins as ', 'In move 10', 'In move 20', 'In move 30', 'In move 40', 'White takes black ', 'Black takes white ', 'Check. ']
That means I should adjust my queries of the human data to reflect those biases, something like:
select * from table_actual where move_number = 1 order by move_number limit 50;
which should match the probe ‘The game begins as ‘.
- I’d also like to run longer, full games (look for ‘resigns’, ‘draw’, or ‘wins’) and parse them, but that’s for later.
- Need to figure out the statistics to compare populations. I think I’m going to take some time and look through the NIST Engineering Statistics Handbook

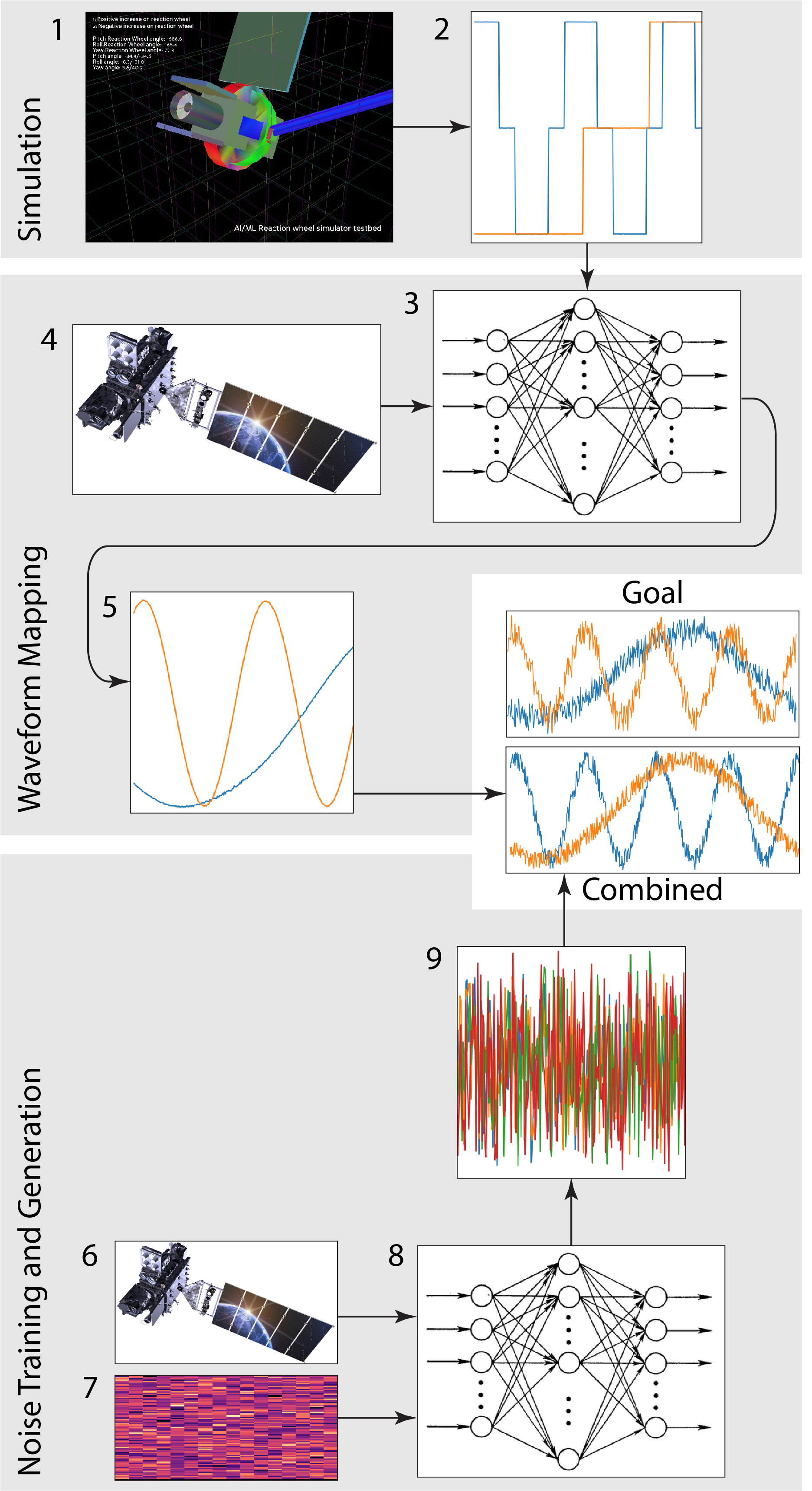
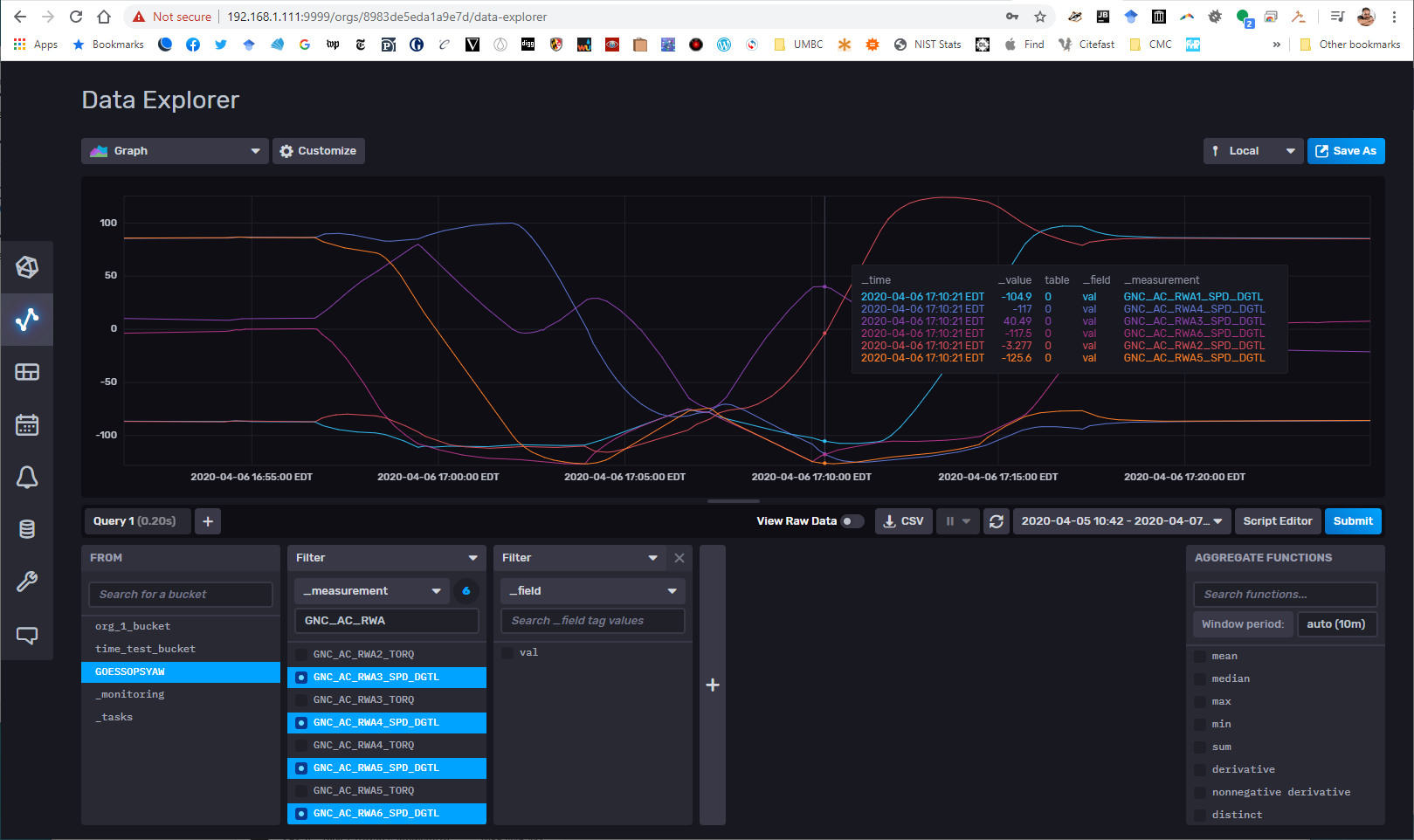
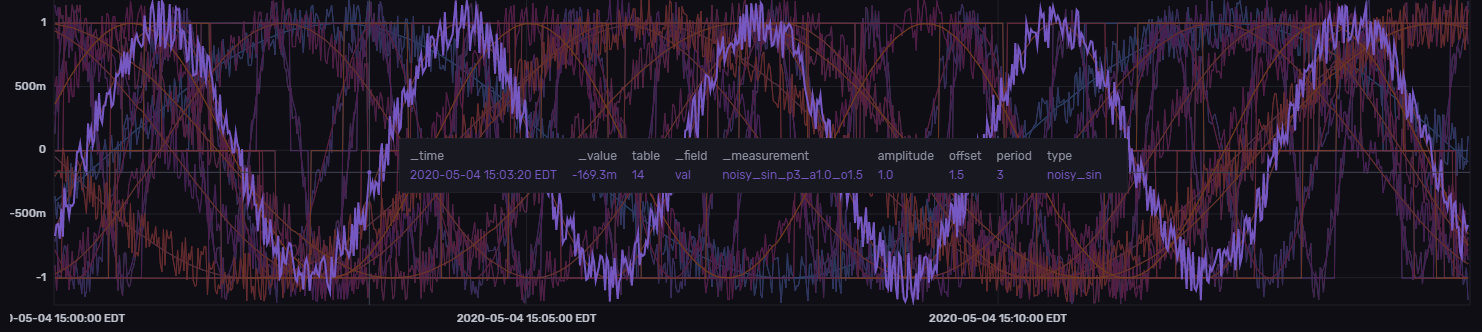
GOES
- Vadim seems to have made progress. Need to set up a meeting to chat and catch up
- 2:00 meeting with V & E. Good progress!
- GVSETS has been moved to Nov 3. Speaking of which, I’ll need to compare simulated and actual maneuvers, so stats here too. Now that the moves are cooking I’ll start on the stats













You must be logged in to post a comment.