
ASRC PhD, NASA 7:00 – 5:00
- Incorporate T’s changes – done!
- Topic Modeling with LSA, PLSA, LDA & lda2Vec
- This article is a comprehensive overview of Topic Modeling and its associated techniques.
- More Grokking. Here’s the work for the day:
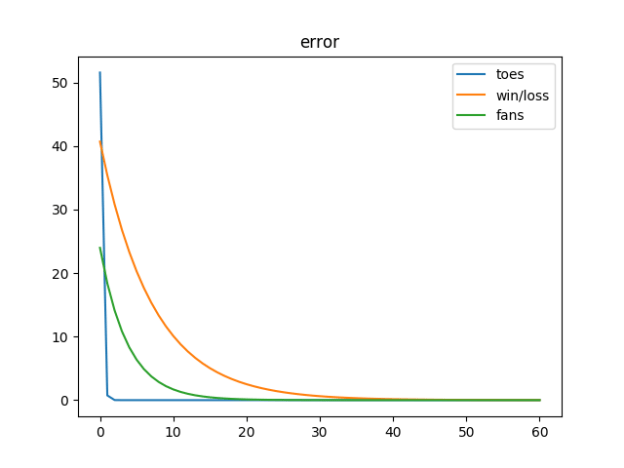
# based on https://github.com/iamtrask/Grokking-Deep-Learning/blob/master/Chapter5%20-%20Generalizing%20Gradient%20Descent%20-%20Learning%20Multiple%20Weights%20at%20a%20Time.ipynb import numpy as np import matplotlib.pyplot as plt import random # methods ---------------------------------------------------------------- def neural_network(input, weights): out = input @ weights return out def error_gt_epsilon(epsilon: float, error_array: np.array) -> bool: for i in range(len(error_array)): if error_array[i] > epsilon: return True return False # setup vars -------------------------------------------------------------- #inputs toes_array = np.array([8.5, 9.5, 9.9, 9.0]) wlrec_array = np.array([0.65, 0.8, 0.8, 0.9]) nfans_array = np.array([1.2, 1.3, 0.5, 1.0]) #output goals hurt_array = np.array([0.2, 0.0, 0.0, 0.1]) wl_binary_array = np.array([ 1, 1, 0, 1]) sad_array = np.array([0.3, 0.0, 0.1, 0.2]) weights_array = np.random.rand(3, 3) # initialise with random weights ''' #initialized with fixed weights to compare with the book weights_array = np.array([ [0.1, 0.1, -0.3], #hurt? [0.1, 0.2, 0.0], #win? [0.0, 1.3, 0.1] ]) #sad? ''' alpha = 0.01 # convergence scalar # just use the first element from each array fro training (for now?) input_array = np.array([toes_array[0], wlrec_array[0], nfans_array[0]]) goal_array = np.array([hurt_array[0], wl_binary_array[0], sad_array[0]]) line_mat = [] # for drawing plots epsilon = 0.01 # how close do we have to be before stopping #create and fill an error array that is big enough to enter the loop error_array = np.empty(len(input_array)) error_array.fill(epsilon * 2) # loop counters iter = 0 max_iter = 100 while error_gt_epsilon(epsilon, error_array): # if any error in the array is big, keep going #right now, the dot product of the (3x1) input vector and the (3x3) weight vector that returns a (3x1) vector pred_array = neural_network(input_array, weights_array) # how far away are we linearly (3x1) delta_array = pred_array - goal_array # error is distance squared to keep positive and weight the system to fixing bigger errors (3x1) error_array = delta_array ** 2 # Compute how far and in what direction (3x1) weights_d_array = delta_array * input_array print("\niteration [{}]\nGoal = {}\nPred = {}\nError = {}\nDelta = {}\nWeight Deltas = {}\nWeights: \n{}".format(iter, goal_array, pred_array, error_array, delta_array, weights_d_array, weights_array)) #subtract the scaled (3x1) weight delta array from the weights array weights_array -= (alpha * weights_d_array) #build the data for the plot line_mat.append(np.copy(error_array)) iter += 1 if iter > max_iter: break plt.plot(line_mat) plt.title("error") plt.legend(("toes", "win/loss", "fans")) plt.show() - Here’s a chart!
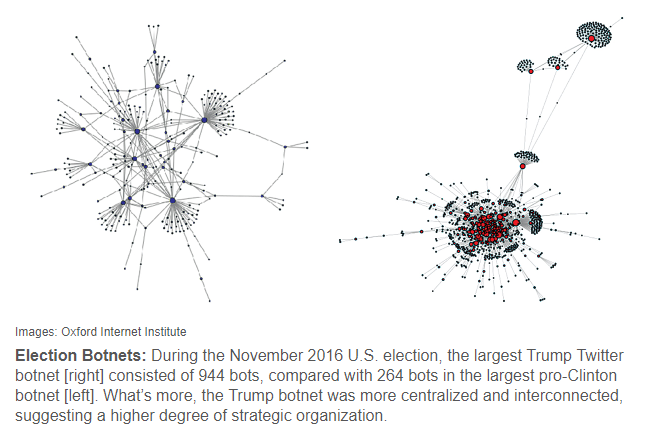
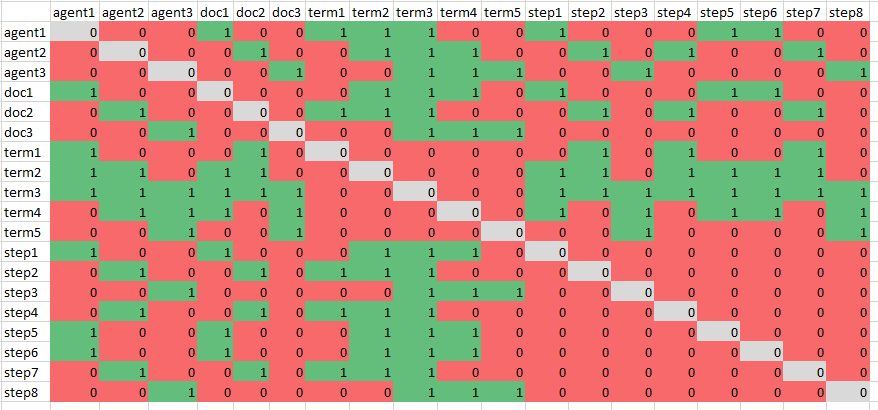
- Continuing Characterizing Online Public Discussions through Patterns of Participant Interactions
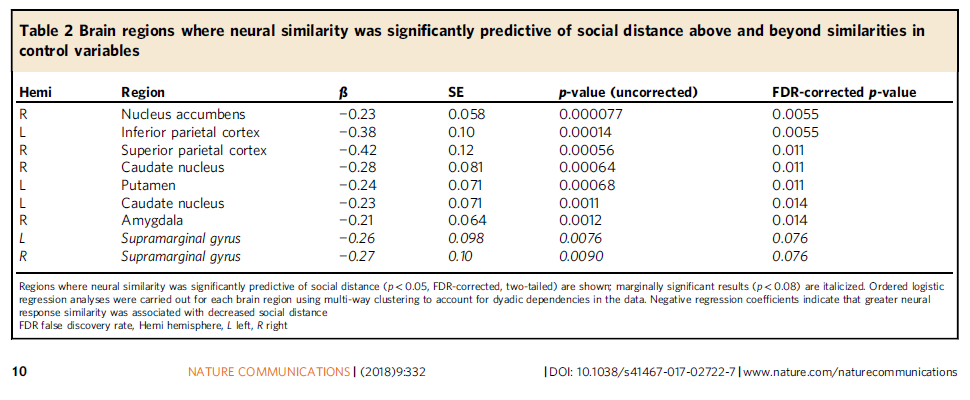




You must be logged in to post a comment.