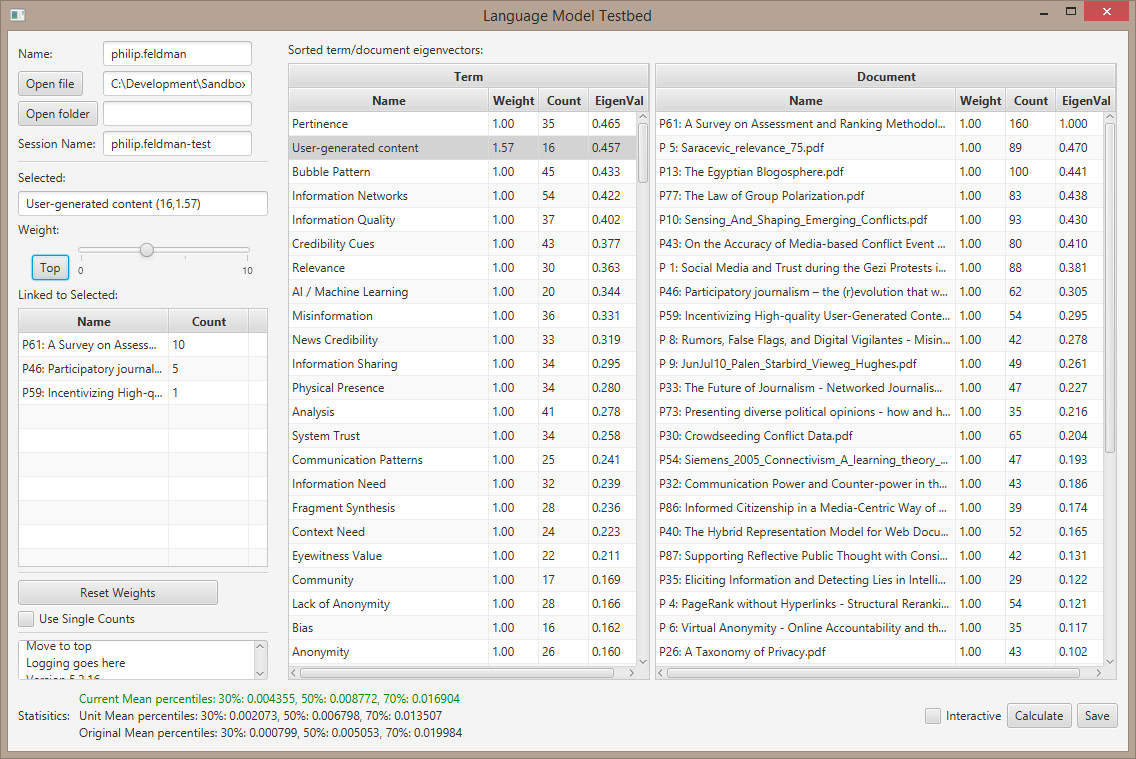
Ok, the rank table is consistent across all columns. In my test code, the eigenvector stabilizes after 5 iterations:
initial
, col1, col2, col3, col4,
row1, 11, 21, 31, 41,
row2, 12, 22, 32, 42,
row3, 13, 23, 33, 43,
derived
, row1, row2, row3, col1, col2, col3, col4,
row1, 1, 0, 0, 0.26, 0.49, 0.72, 0.95,
row2, 0, 1, 0, 0.28, 0.51, 0.74, 0.98,
row3, 0, 0, 1, 0.3, 0.53, 0.77, 1,
col1, 0.26, 0.28, 0.3, 1, 0, 0, 0,
col2, 0.49, 0.51, 0.53, 0, 1, 0, 0,
col3, 0.72, 0.74, 0.77, 0, 0, 1, 0,
col4, 0.95, 0.98, 1, 0, 0, 0, 1,
rank
, row1, row2, row3, col1, col2, col3, col4,
row1, 0.61, 0.62, 0.64, 0.22, 0.41, 0.59, 0.78,
row2, 0.62, 0.65, 0.67, 0.23, 0.42, 0.61, 0.8,
row3, 0.64, 0.67, 0.69, 0.24, 0.43, 0.63, 0.83,
col1, 0.22, 0.23, 0.24, 0.08, 0.15, 0.22, 0.29,
col2, 0.41, 0.42, 0.43, 0.15, 0.27, 0.4, 0.52,
col3, 0.59, 0.61, 0.63, 0.22, 0.4, 0.58, 0.76,
col4, 0.78, 0.8, 0.83, 0.29, 0.52, 0.76, 1,
EigenVec
row1, 1, 0.71, 0.62, 0.61, 0.61, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
row2, 0, 0.46, 0.61, 0.62, 0.62, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
row3, 0, 0.48, 0.63, 0.64, 0.64, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
col1, 0.26, 0.13, 0.21, 0.22, 0.22, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
col2, 0.49, 0.25, 0.38, 0.41, 0.41, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
col3, 0.72, 0.37, 0.55, 0.59, 0.59, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
col4, 0.95, 0.49, 0.73, 0.78, 0.78, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,