Ok, so we’re still in the middle of a pandemic, it looks like around 400 people might be charged with sedition for the Jan 6 attack on the Capitol, and the GOP doesn’t want to have anything to do with impeachment, but the crazy seems to be much lower.
Vaccines are rolling out, and we’ll probably be at closer to 200M vaccinations by April. The government appears to be doing things again. It feels like we are past the turning point in whatever metaphor you’d like to use here, and now entering the mopping up phase.
The Fairness Doctrine sounds a lot better than it actually was
- What America needs instead is a creative, comprehensive effort by both the private sector and the government to disincentivize conspiracies and misinformation on the many platforms on which they flourish. Some social media companies have begun this work, clearing out QAnon sites and banning some far-right and White power users and communities who pose a threat. That work needs to continue, with careful attention to the biggest offenders who game algorithms and media structures to spread misinformation. But sources of misinformation also need to be demonetized, whether they are YouTube channels or national cable networks, and algorithms tweaked to slow down the spread of extreme content.
Book
- More conclusions. I’m tempted to look at antisemitism through the dominance hierarchy lens. To show that if you truly feel that you are at the top of the hierarchy (just under your God), and use the Bible as the scaffolding for that understanding, then the fact that the same bible says that the Jews are chosen by God must really require some mental gymnastics. And for some, those gymnastics lead to genocide, since once the Jews are gone, then there is no one between you and God, and the rightful order is restored.
- I think this is related to slavery and racism in the US. To be able to treat people as property requires that they be less than people, otherwise dominance makes no sense. The hierarchy of God -> slave holder -> slave justifies any dominance behavior. And in the end the mental gymnastics that are required for that are the same as those required by anti-Semites. These are both co-created fictional social realities that exist in the communities that believe themselves righteously superior to those they oppress. And as we now understand, that process of creating hierarchical social realities can often stampede to the worst possible places.
NOAA
- SEVEN trainings by Feb 1! But I can’t get to my email, so that’s going nowhere
GOES
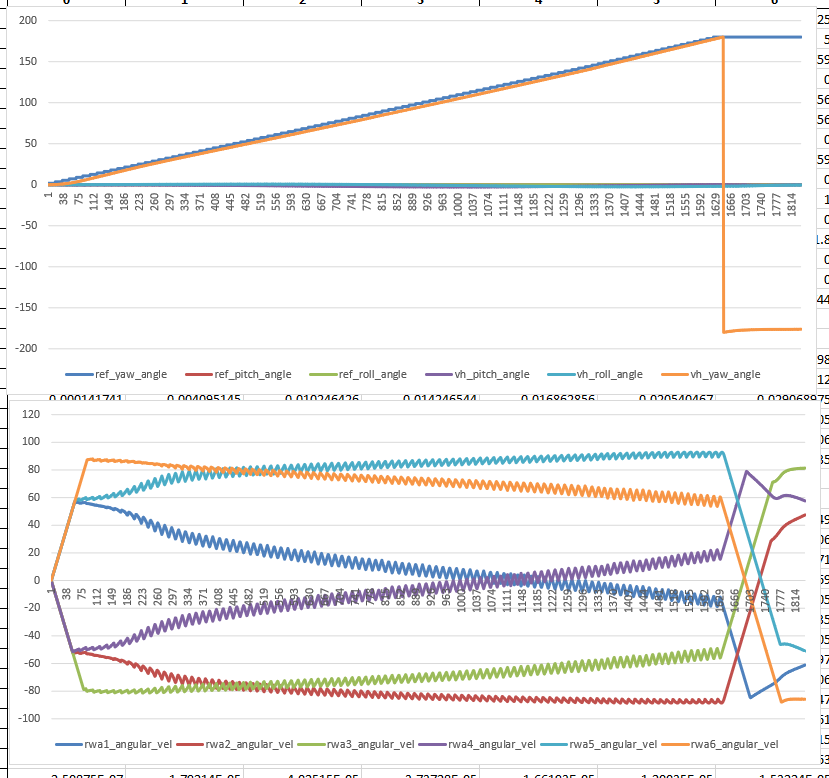
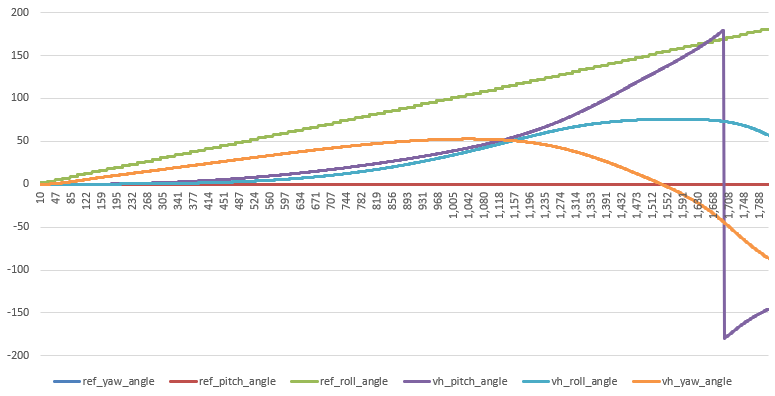
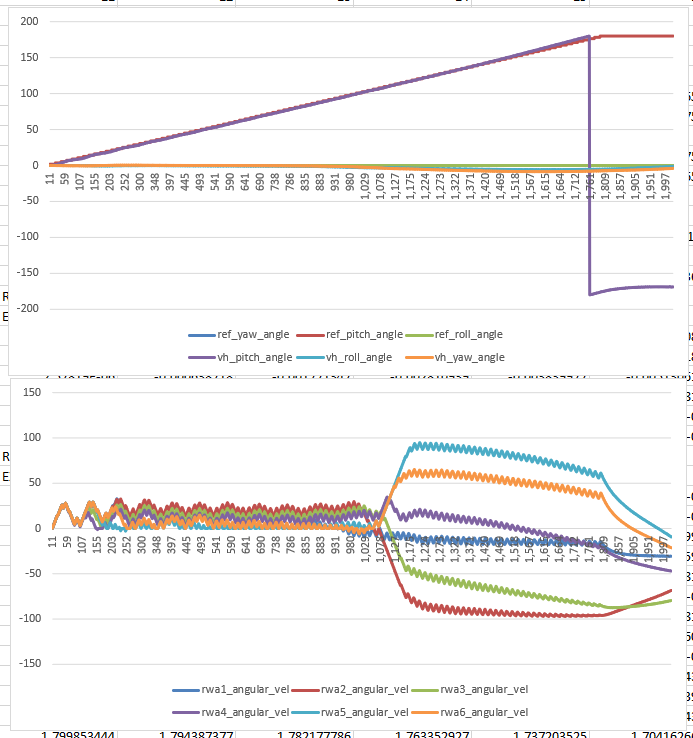
- 11:00 Meeting with Vadim. He has most of the changes in. Waiting for some final work and then I’ll start rolling in the new TopController
JuryRoom








You must be logged in to post a comment.