
D20
#COVID Aseel’s docs don’t seem to be in the proper unicode? I tried downloading a version of the Quran from here, and that seems to be working. Hmmm. Trying to train on the Quran with these args:
--output_dir=output --model_type=gpt2 --model_name_or_path=gpt2 --per_gpu_train_batch_size=1 --do_train --train_data_file=..\input\quran-simple.txt
GPT-2 Agents
- Added basic moves for all the pieces. Still need to handle hints
Evaluating move [d4 Nf6] Fred Van der Vliet moves white pawn from d2 to d4. Loek Van Wely moves black knight from g8 to f6. Evaluating move [c4 g6] Fred Van der Vliet moves white pawn from c2 to c4. Loek Van Wely moves black pawn from g7 to g6. Evaluating move [g3 Bg7] Fred Van der Vliet moves white pawn from g2 to g3. Loek Van Wely moves black bishop from f8 to g7. Evaluating move [Bg2 O-O] Fred Van der Vliet moves white bishop from f1 to g2. Loek Van Wely kingside castles.
GOES
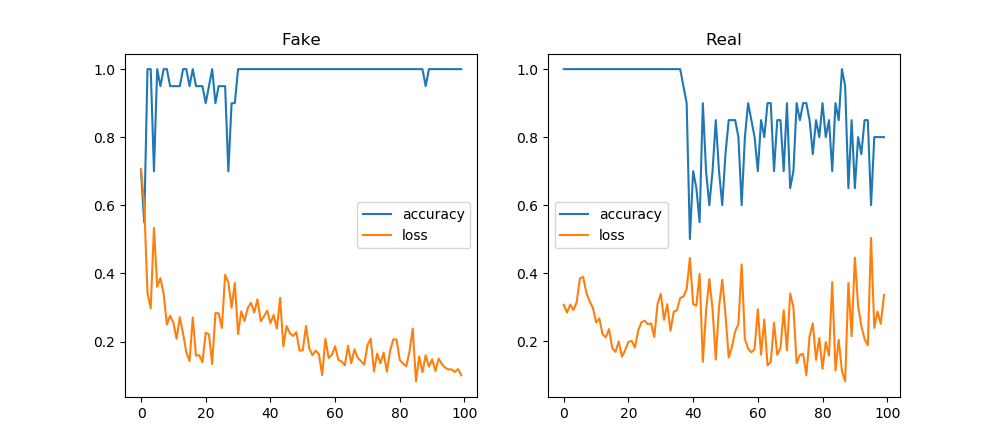
- Working on NoiseGAN
- Seems to be training without blowing up….
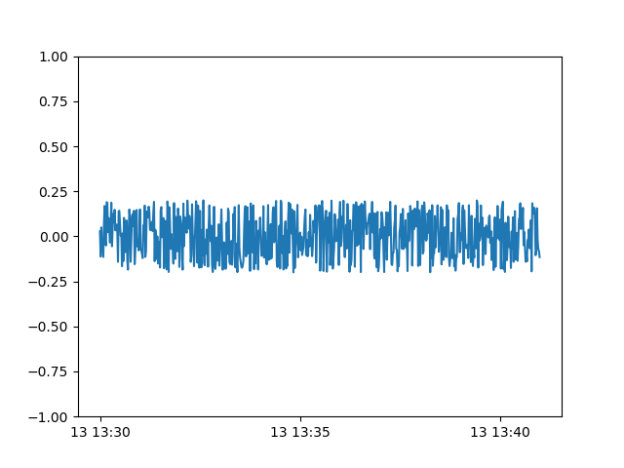
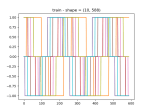
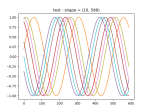
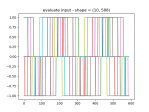
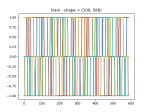
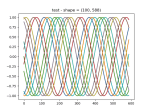
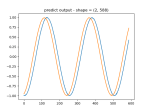
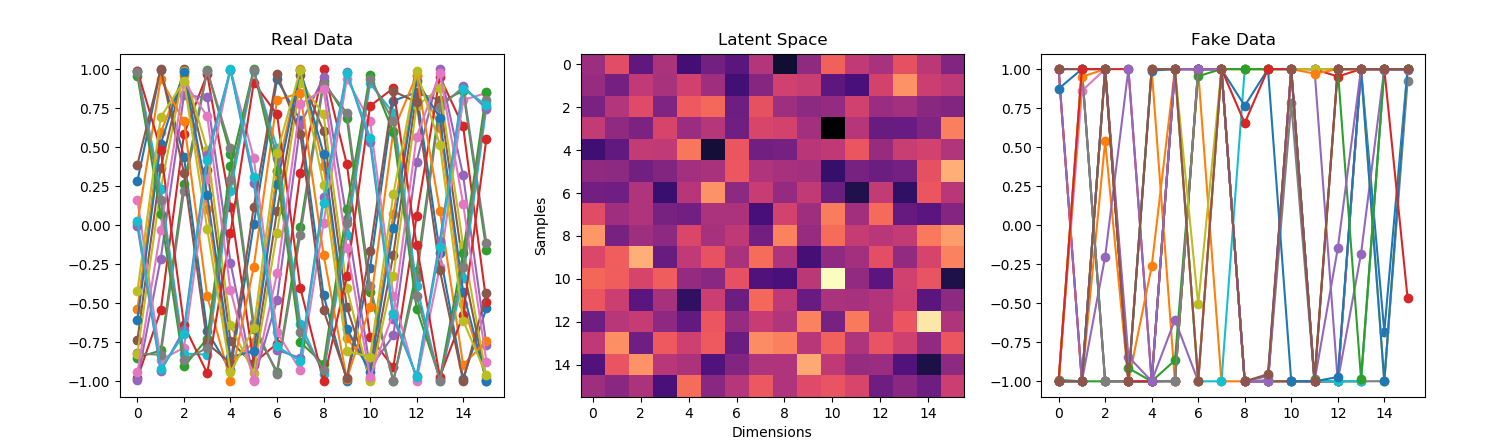
- It ran, but the results are weird.


-
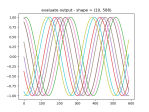
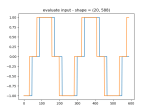
- As you can see, the fake data seems to have learned the noise well, but the scale is wrong.
- It does seem to be able to learn about the scale though:

-
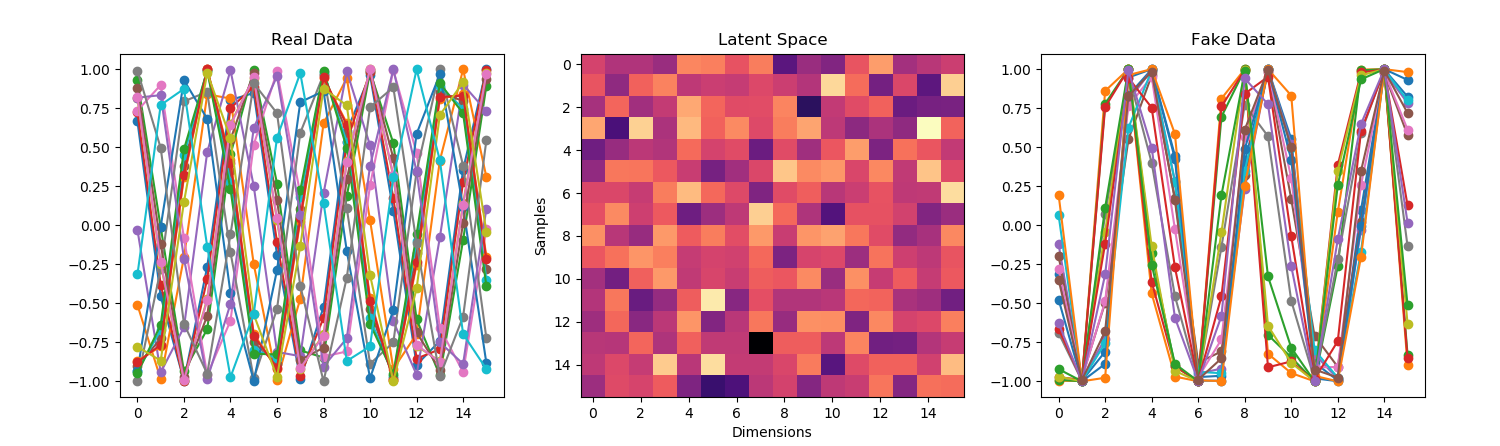
- Adding dropout seems to help:

-
- The discriminator so far:
self.d_model = Sequential() self.d_model.add(Dense(64, activation='relu', kernel_initializer='he_uniform', input_dim=self.vector_size)) self.d_model.add(Dropout(0.2)) self.d_model.add(Dense(25, activation='relu', kernel_initializer='he_uniform', input_dim=self.vector_size)) self.d_model.add(Dropout(0.2)) self.d_model.add(Dense(1, activation='sigmoid')) # compile model self.d_model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
- The discriminator so far:

- Just found out about TF-GAN from this Google course on GANs
- Mode Collapse is why the GAN keeps generating a single waveform
- GANSynth: Making music with GANs
- In this post, we introduce GANSynth, a method for generating high-fidelity audio with Generative Adversarial Networks (GANs).
- 10 Lessons I Learned Training GANs for one Year
- Advanced Topics in GANs
- 10:00 meeting with Vadim – nope
















You must be logged in to post a comment.