
7:00 – 6:00 ASRC
- Continuing with Sociophysics
- Social Phenomena on complex networks
- Loops of nodes behave differently from trees. what to do about that? I think loops drive the echo chamber process? It is, after all, feedback..
- There is also a ‘freezing’ issue, where a stable state is reached where two cliques containing different states are lightly connected, but not enough that the neighbors in one clique can be convinced to change their opinion [Fig. 6.2, pg 135]
- Residual Energy: The difference between the actual energy and the known energy of the perfectly-ordered ground state (full consensus).
- BRC
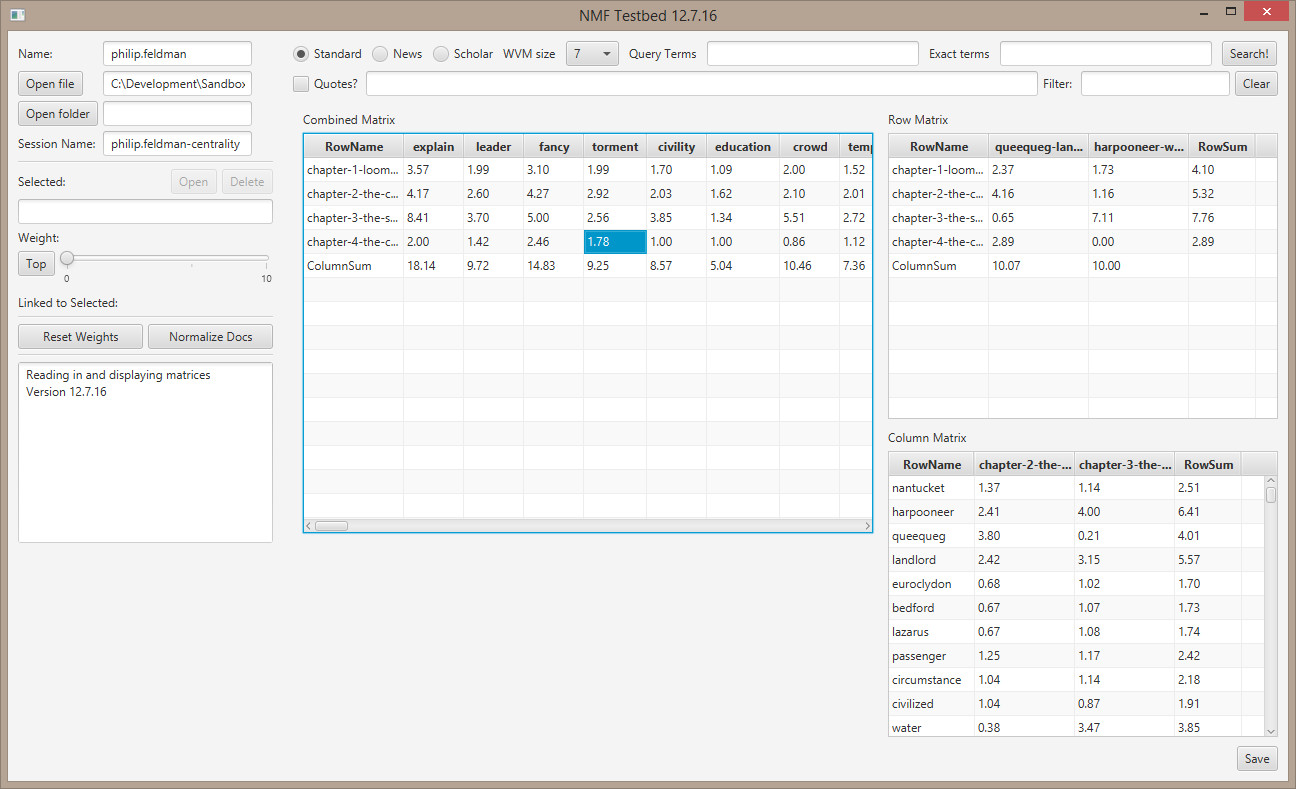
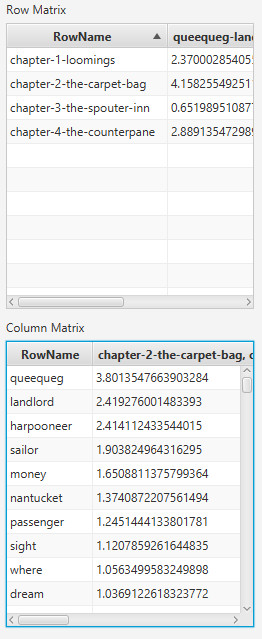
- Need to not split quoted columns
- Generate a matrix where flags that are Yes -> 1 and empty/null -> o
- Retrospective
- Had a thought that NMF might work in tensors as well. I need to rewrite the gradient descent so that it takes an arbitrary number of dimension.
- Meeting with Nir. Sold him on clustering.

You must be logged in to post a comment.