
- Hadoop Environment
- More fun discussions on our changes to Hadoop development today. Essentially we have a DevOps box with a baby Hadoop cluster we can use for development.
- ClusteringService scaffold / deploy
- I spent a bit of time today building out the scaffold MicroService that will manage clustering requests, dispatch the MapReduce to populate the comparison tensor, and interact with the TensorFlow Python.
- I ran into a few fits and starts with syntax issues where the service name was causing fits because of errant “-“. I resolved those and updated the dockerfile with the new TensorFlow docker image. Once I have a finished list of the packages I need installed for Python integration I’ll have to have them updated to that image.
- Bob said he would look at moving over the scaffold of our MapReduce job launching code from a previous service, and I suggested he not blow away all the work I had just done and copy the as needed pieces in.
- TFRecord output
- Trying to complete the code for outputting MapReduce results as a TFRecord protobuff objects for TensorFlow.
- I created a PythonIntegrationPlayground project with an OutputTFRecord.java class responsible for building a populated test matrix in a format that TensorFlow can view.
- Google supports this with their ecosystem libraries here. The library includes instructions with versions and a working sample for MapReduce as well as Spark.
- The frustrating thing is that presumably to avoid issues with version mismatches, they require you to compile your own .proto files with the protoc compiler, then build your own JAR for the ecosystem.hadoop library. Enough changes have happened with protoc and how it handles the locations of multiple inter-connected proto files that you absolutely HAVE to use the locations they specify for your TensorFlow installation or it will not work. In the old days you could copy the .proto files local to where you wanted to output them to avoid path issues, but that is now a Bad Thing(tm).
- The correct commands to use are:
- protoc –proto_path=%TF_SRC_ROOT% –java_out=src\main\java\ %TF_SRC_ROOT%\tensorflow\core\example\example.proto
- protoc –proto_path=%TF_SRC_ROOT% –java_out=src\main\java\ %TF_SRC_ROOT%\tensorflow\core\example\feature.proto
- After this you will need Apache Maven to build the ecosystem JAR and install so it can be used. I pulled down the latest (v3.3.9) from maven.apache.org.
- Because I’m a sad, sad man developing on a Windows box I had to disable to Maven tests to build the JAR, but it’s finally built and in my repo.
- Java/Python interaction
- I looked at a bunch of options for Java/Python interaction that would be performant enough, and allow two-way communication between Java/Python if necessary. This would allow the service to provide the location in HDFS to the TensorFlow/Sci-Kit Python clustering code and receive success/fail messages at the very least.
- Digging on StackOverflow lead me to a few options.
- Digging a little further I found JPServe, a small library based on PyServe that uses JSON to send complex messages back to Java.
- I think for our immediate needs its most straightforward to use the ProcessBuilder approach:
- ProcessBuilder pb = new ProcessBuilder(“python”,”test1.py”,””+number1,””+number2);
- Process p = pb.start();
- This does allow return codes, although not complex return data, but it avoids having to manage a PyServe instance inside a Java MicroService.
- Cycling
- I’ve been looking forward to a good ride for several days now, as the weather has been awful (snow/ice). Got up to high 30s today, and no visible ice on the roads so Phil and I went out for our ride together.
- It was the first time I’ve been out with Phil on a bike with gears, and its clear how much I’ve been able to abuse him being on a fixie. If he’s hard to keep up with on a fixed gear, its painful on gears. That being said, I think I surprised him a bit when I kept a 9+ mph pace up the first hill next to him and didn’t die.
- My average MPH dropped a bit because I burned out early, but I managed to rally and still clock a ~15 mph average with some hard peddling towards the end.
- I’m really enjoying cycling. It’s not a hobby I would have expected would click with me, but its a really fun combination of self improvement, tenacity, min-maxing geekery, and meditation.
Phil 3.17.17
7:00 – 8:00 Research
- Troll Paper
- Looks interesting: An Intelligent Interface for Organizing Online Opinions on Controversial Topics. From IUI 2017
8:30 – 6:00 BRC
- Use of Genetic Algorithms for Finding Roots of Algebraic Equations
- Matplotlib today
- That is just cool. Interactive, too:
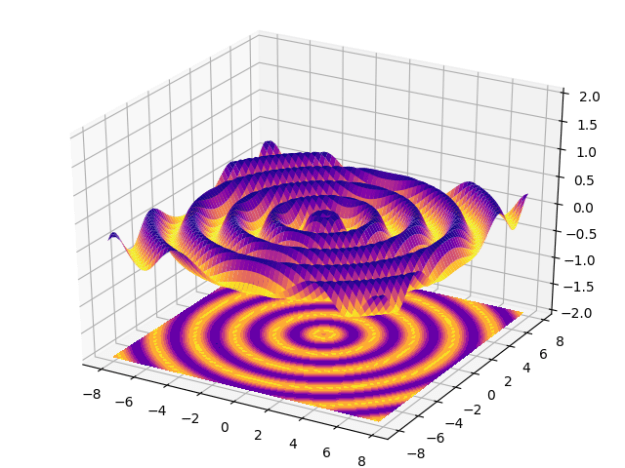
- That is just cool. Interactive, too:
- Scipy next. Done! Local minima finding is awesome. We can have our own functions match the fmin interface and then feed in our clusterer and our minima finder
- Tried installing MayAvi, but it chokes on VTK, which won’t play with python 3.5 yet.Not a huge deal, but frustrating way to end the week.
Phil 3.16.17
7:00 – 8:00, 4:00 – 5:30 Research
- More troll paper
- Meeting with Wayne
- See if I can get this on the schedule: Human Computer Interaction Consortium
- June 25th – 29th
8:30 – 3:30 BRC
- Added subtasks for the clustering optimizer
- Meeting with Aaron and Heath about scalability
- Converting a panda data frame to a numpy ndarray – done
df = createDictFrame(rna, cna) df = df.sort_values(by='sum', ascending=True) mat = df.as_matrix()
- Working on polynomials – done

- Played with the Mandelbrot set as well. Speedy!
- And for going deeper down the rabbit hole (later!!!) – How To Quickly Compute The Mandelbrot Set In Python. This includes direct Cuda and Cython.
- This came across my feed: Scikit-Learn Tutorial Series
Phil 3.15.17
7:00 – 8:00 Research
- Information Wars: A Window into the Alternative Media Ecosystem
- By Kate Starbird, (Scholar)
Professor, Human Centered Design & Engineering, University of Washington
- By Kate Starbird, (Scholar)
- Started reviewing the Tumblr trolling paper. Set up a Tumblr account
8:30 – 5:00 BRC
- Heath was able to upgrade to Python 3.5.2
- Ran array_thoughts. Numbers are better than my laptop
- Attempting just_dbscan: Some hiccups due to compiling from sources. (No module named _bz7). Stalled? Sent many links.
- Success! Heath installed a binary Python rather than compiling from sources. A little faster than my laptop. No GPUs, CPU, not memory bound.
- Continuing my tour of the SciPy Lecture Notes
- Figuring out what a matplotlib backend is
- Looks like there are multiple ways to serve graphics: http://matplotlib.org/faq/howto_faq.html#howto-webapp
- More on typing Python
- Class creation, inheritance and superclass overloading, with type hints:
class Student(object): name = 'noName' age = -1 major = 'unset' def __init__(self, name: str): self.name = name def set_age(self, age: int): self.age = age def set_major(self, major: str): self.major = major def to_string(self) -> str: return "name = {0}\nage = {1}\nmajor = {2}"\ .format(self.name, self.age, self.major) class MasterStudent(Student): internship = 'mandatory, from March to June' def to_string(self) -> str: return "{0}\ninternship = {1}"\ .format(Student.to_string(self), self.internship) anna = MasterStudent('anna') print(anna.to_string()) - Finished the Python part, Numpy next
- Figured out how to to get a matrix shape, (again, with type hints):
import numpy as np def set_array_sequence(mat: np.ndarray): for i in range(mat.shape[0]): for j in range(mat.shape[1]): mat[i, j] = i * 10 + j a = np.zeros([10, 3]) set_array_sequence(a) print(a.shape) print(a)
Phil Pi Day!
Research
- I got accepted into the Collective Intelligence conference!
- Working on LaTex formatting. Slow but steady.
- Ok, the whole doc is in, but the 2 column charts are not locating well. I need to rerig them so that they are single column. Fixed! Not sure about the gray bg. Maybe an outline instead?
Aaron 3.13.17
- Sprint Review
- Covered issues with having customers present with Sprint Reviews; ie. don’t do it, it makes them take 3x as long and cover less.
- Alternative facts presented about design tasks.
- ClusteringService
- Send design content to other MapReduce developer.
- Sent entity model queries out regarding claim data.
- Cycling
- I went out for the 12.5 mile loop today. It was 30 degrees with a 10-12 mph wind, but it was… easy? I didn’t even lose my breath going up “Death Hill”. I guess its about time to move onto the 15 mile loop for lunchtime rides.
- Sprint Grooming / Sprint Planning
- It was decided to roll directly from grooming to planning activities.
Phil 3.13.17
7:00 – 8:00, 5:00 – 7:00 Research
- Back to learning LaTex. Read the docs, which look reasonable, if a little clunkey.
- Working out how to integrate RevEx
- Spent a while looking at Overleaf and ShareLatex, but decided that I like TexStudio better. Used the MikTex package manager to download revtex 4.1.
- Looked for “aiptemplate.tex” and “aipsamp.tex” and found them with all associated files here: ftp://ftp.tug.org/tex/texlive/Contents/live/texmf-dist/doc/latex/revtex/sample/aip. And it pretty much just worked. Now I need to start stuffing text into the correct places.
8:30 – 2:30 BRC
- Got a response from the datapipeline folks about their demo code. sked them to update the kmeans_single_iteration.py and functions.py files.
- The SciKit DBSCAN is very fast
setup duration for 10000 points = 0.003002166748046875 DBSCAN duration for 10000 points = 1.161818265914917
- Drilling down into the documentation. Starting with the SciPy Lecture Notes
- Python has native support for imaginary numbers. Huh.
- Static typing is also coming. This is allowed, but doesn’t seem to do anything yet:
def calcL2Dist(t1:List[float], t2:List[float]) -> float:
- This is really nice:
In [35]: def variable_args(*args, **kwargs): ....: print 'args is', args ....: print 'kwargs is', kwargs ....: In [36]: variable_args('one', 'two', x=1, y=2, z=3) args is ('one', 'two') kwargs is {'y': 2, 'x': 1, 'z': 3}
- in my ongoing urge to have interactive applications, I found Bokeh, which seems to create javascript??? More traditionally, wxPython appears to be a set of bindings to the wxWidgets library. Installed, but I had to grab the compiled wheel from here (as per S.O.). I think I’m going to look closely at Bokeh though, if it can talk to the running Python, then we could have some nice diagnostics. And the research browser could possibly work through this interface as well.
Phil 3.10.17
Elbow Tickets!
7:00 – 8:00 Research
- artisopensource.net
- Accurat is a global, data-driven research, design, and innovation firm with offices in Milan and New York.
- Formatting paper for Phys Rev E. Looks like it’s gotta be LaTex, or more specifically, RevTex. My entry about formats
- Downloaded RevTex
- How to get Google Docs to LaTex
- Introduction to LaTex
- Installing TexX slooooow…

- That literally took hours. Don’t install the normal ‘big!’ default install?
- Installing pandoc
- Tried to just export a PDF, but that choked. reading the manual at C:\texlive\2016\tlpkg\texworks\texworks-help\TeXworks-manual\en
- Compiled the converted doc! Not that I actually know what all this stuff does yet…
- And then I thought, ‘gee, this is more like coding – I wonder if there is a plugin for IntelliJ?’. Yest, but this page ->BEST DEVELOPMENT SETUP FOR LATEX – says to use texStudio. downloading to try. This seems to be very nice. Not sure if it will work without a LaTexInstall, but I’ll tray that on my home box. It would be a much faster install if it did. And it’s been updated very recently – Jan 2017
- Aaaand the answer is no, it needs an install. Trying MikTex this time. Well that’s a LOT faster!
8:30 – 10:30, 11:00 – 2:00 BRC
- This looks very cool: t-SNE algo in R and Python, made with same dataset
Phil 3.9.17
7:00 – 7:30, 4:00-5:30 Research
- Short session this morning. Dr. Appt at 8:00
- Sending Sunstein letter. done!
- Lee Boot visualization
9:30 – 3:30BRC
- Neat thing from Flickr on finding similar images.
- How to install pyLint as an external tool in IntelliJ.
- How to find out where your python modules are installed:
C:\Windows\system32>pip3 show pylint Name: pylint Version: 1.6.5 Summary: python code static checker Home-page: https://github.com/PyCQA/pylint Author: Python Code Quality Authority Author-email: code-quality@python.org License: GPL Location: c:\users\philip.feldman\appdata\local\programs\python\python35\lib\site-packages Requires: colorama, mccabe, astroid, isort, six
- Looking at building scikit DBSCAN clusterer. I think the plan will be to initially use TF as IO. read in the protobuf and eval() out the matrix to scikit. Do the clustering in scikit, and then use TF to write out the results. Since TF and scikit are very similar, that should aid in the transfer from Python to TF, while allowing for debugging and testing in the beginning. And we can then benchmark.
- Working on running the scikit.learn plot_dbscan example, and broke the scipy install. Maybe use the Windows installers? Not sure what that might break. Will try again and follow error messages first.
- This looks like the fix: http://stackoverflow.com/questions/28190534/windows-scipy-install-no-lapack-blas-resources-found
- Sorry to necro, but this is the first google search result. This is the solution that worked for me:
- Download numpy+mkl wheel from http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy. Use the version that is the same as your python version (check using python -V). Eg. if your python is 3.5.2, download the wheel which shows cp35
- Open command prompt and navigate to the folder where you downloaded the wheel. Run the command: pip install [file name of wheel]
- Download the SciPy wheel from: http://www.lfd.uci.edu/~gohlke/pythonlibs/#scipy (similar to the step above).
- As above, pip install [file name of wheel]
- Sorry to necro, but this is the first google search result. This is the solution that worked for me:
- got a new error where
TypeError: unorderable types: str() < int()
- After some searching, here’s the SO answer
- Changed line 406 from fixes.py from:
if np_version < (1, 12, 0):into
if np_version < (1, 12): - Success!!!

- Sprint Review
Phil 3.8.17
7:00 – 8:00 Research
- Tweaking the Sunstein letter
- Trying to decide what to do next. There is a good deal of work that can be done in the model, particularly with antibelief. Totalitarianism may actually go further?
- Arendt says:The advantages of a propaganda that constantly “adds the power of organization”[58] to the feeble and unreliable voice of argument, and thereby realizes, so to speak, on the spur of the moment, whatever it says, are obvious beyond demonstration. Foolproof against arguments based on a reality which the movements promised to change, against a counterpropaganda disqualified by the mere fact that it belongs to or defends a world which the shiftless masses cannot and will not accept, it can be disproved only by another, a stronger or better, reality.
- [58] Hadamovsky, op. cit., p. 21. For totalitarian purposes it is a mistake to propagate their ideology through teaching or persuasion. In the words of Robert Ley, it can be neither “taught” nor “learned,” but only “exercised” and “practiced” (see Der Weg zur Ordensburg, undated).
- On the same page: The moment the movement, that is, the fictitious world which sheltered them, is destroyed, the masses revert to their old status of isolated individuals who either happily accept a new function in a changed world or sink back into their old desperate superfluousness. The members of totalitarian movements, utterly fanatical as long as the movement exists, will not follow the example of religious fanatics and die the death of martyrs (even though they were only too willing to die the death of robots). [59]
- [59] R. Hoehn, one of the outstanding Nazi political theorists, interpreted this lack of a doctrine or even a common set of ideals and beliefs in the movement in his Reichsgemeinschaft and Volksgeme’mschaft, Hamburg, 1935: “From the point of view of a folk community, every community of values is destructive”
- Arendt says:The advantages of a propaganda that constantly “adds the power of organization”[58] to the feeble and unreliable voice of argument, and thereby realizes, so to speak, on the spur of the moment, whatever it says, are obvious beyond demonstration. Foolproof against arguments based on a reality which the movements promised to change, against a counterpropaganda disqualified by the mere fact that it belongs to or defends a world which the shiftless masses cannot and will not accept, it can be disproved only by another, a stronger or better, reality.
- This implies that there a stage where everything outside the cluster is attacked and destroyed, rather than avoided. So there’s actually four behaviors: Explore, Confirm, Avoid, and something like Lie/Destroy/Adhere. This last option cuts the Gordian Knot of game theory – its premise of making decisions with incomplete information – by substituting self-fulfilling fictional information that IS complete. And here, diversity won’t help. It literally is the enemy.
- And this is an emergent phenomenon. From Konrad Heiden’s Der Führer. Hitler’s Rise to Power: Propaganda is not “the art of instilling an opinion in the masses. Actually it is the art of receiving an opinion from the masses.”
8:30 – 6:00 BRC
- Figured out part of my problem. The native python math is sloooooow. Using numpy makes everything acceptably fast. I’m not sure if I’m doing anything more than calculating in numpy and then sticking the result in TensorFlow, but it’s a start. Anyway, here’s the working code:
import time import numpy as np import tensorflow as tf def calcL2Dist(t1, t2): sub = np.subtract(t1, t2) squares = np.square(sub) dist = np.sum(squares) return dist def createCompareMat(sourceMat, rows): resultMat = np.zeros([rows, rows]) for i in range(rows): for j in range(rows): if i != j: t1 = sourceMat[i] t2 = sourceMat[j] dist = calcL2Dist(t1, t2) resultMat[i, j] = dist return resultMat def createSequenceMatrix(rows, cols, scalar=1.0): mat = np.zeros([rows, cols]) for i in range(rows): for j in range(cols): val = (i+1)*10 + j mat[i, j] = val * scalar return mat for t in range(5, 8): side = (t*100) sourceMat = createSequenceMatrix(side, side) resultMat = tf.Variable(sourceMat) # Use variable start = time.time() with tf.Session() as sess: tf.global_variables_initializer().run() # need to initialize all variables distMat = createCompareMat(sourceMat=sourceMat, rows=side) resultMat.assign(distMat).eval() result = resultMat.eval() #print('modified resultMat:\n', result) #print('modified sourceMat:\n', sourceMat) stop = time.time() duration = stop-start print("{0} cells took {1} seconds".format(side*side, duration)) - Working on the Sprint review. I think we’re in a reasonably good place. We can do our clustering using scikit, at speeds that are acceptable even on my laptop. Initially, we’ll use TF mostly for transport between systems, and then backfill capability.
- This is really important for the Research Browser concept:
Phil 3.7.17
7:00 – 8:00 Research
- The meeting with Don went well. We’re going to submit to Physical Review E. I need to fix a chart and then we need to make the paper more ‘Math-y’
- Creating a copy of the paper for PRE – done
- Fix the whisker chart – done
- Compose a letter to Cass Sunstein asking for his input. Drafted. Getting sanity checks
- On Building a “Fake News” Classification Model
8:30 – 6:00 BRC
- Ran into an unexpected problem, the creation of the TF graph for my dictionary is taking exponential time to construct. SAD!
- Debugging TF slides. Includes profiler. Pick up here tomorrow
Aaron 3.6.17
- TensorFlow
- Didn’t get to do much on this today; Phil is churning away learning matrix operations and distance calculations to let us write a DBSCAN plug-in
- Architecture
- Drawing up architecture document with diagram
Phil 3.6.17
6:30 – 7:00 , 4:00 – 6:00 Research
- Meeting with Don
- Something that’s built from agent-based models? Toward a Formal, Visual Framework of Emergent Cognitive Development of Scholars
- Detecting and visualizing emerging trends and transient patterns in scientific literature
- Agent-based computing from multi-agent systems to agent-based models: a visual survey
- Muaz A. Niazi – Complex Adaptive Systems, Agent-based Modeling, Complex Networks, Communication Networks, Cognitive Agent-based Computing
7:30 – 3:30, BRC
- From LearningTensorflow.com: KMeans tutorial. Looks pretty good
- This looks interesting: Large-Scale Evolution of Image Classifiers: Neural networks have proven effective at solving difficult problems but designing their architectures can be challenging, even for image classification problems alone. Evolutionary algorithms provide a technique to discover such networks automatically. Despite significant computational requirements, we show that evolving models that rival large, hand-designed architectures is possible today. We employ simple evolutionary techniques at unprecedented scales to discover models for the CIFAR-10 and CIFAR-100 datasets, starting from trivial initial conditions. To do this, we use novel and intuitive mutation operators that navigate large search spaces. We stress that no human participation is required once evolution starts and that the output is a fully-trained model.
- Working on calculating distance between two vectors. Oddly, these do not seem to be library functions. This seems to be the way to do it:
def calcL2Dist(t1, t2): dist = -1.0 sub = tf.subtract(t1, t2) squares = tf.square(sub) sum = tf.reduce_sum(squares) return sum - Now I’m trying to build a matrix of distances. Got it working after some confusion. Here’s the full code. Note that the ‘source’ matrix is declared as a constant, since it’s immutable(?)
import numpy as np import tensorflow as tf; def calcL2Dist(t1, t2): dist = -1.0 sub = tf.subtract(t1, t2) squares = tf.square(sub) dist = tf.reduce_sum(squares) return dist def initDictRandom(rows = 3, cols = 5, prefix ="doc_"): dict = {} for i in range(rows): name = prefix+'{0}'.format(i) dict[name] = tf.Variable(np.random.rand(cols), tf.float32) return dict def initDictSeries(rows = 3, cols = 5, offset=1, prefix ="doc_"): dict = {} for i in range(rows): name = prefix+'{0}'.format(i) array = [] for j in range(cols): array.append ((i+offset)*10 + j) #dict[name] = tf.Variable(np.random.rand(cols), tf.float32) dict[name] = tf.constant(array, tf.float32) return dict def createCompareDict(sourceDict): distCompareDict = {} keys = sourceDict.keys(); for n1 in keys: for n2 in keys: if n1 != n2: name = "{0}_{1}".format(n1, n2) t1 = sourceDict[n1] t2 = sourceDict[n2] dist = calcL2Dist(t1, t2) distCompareDict[name] = tf.Variable(dist, tf.float32) return distCompareDict sess = tf.InteractiveSession() dict = initDictSeries(cols=3) dict2 = createCompareDict(dict) init = tf.global_variables_initializer() sess.run(init) print("{0}".format(sess.run(dict)).replace("),", ")\n")) print("{0}".format(sess.run(dict2)).replace(",", "])\n")) - Results:
{'doc_0': array([ 10., 11., 12.], dtype=float32) 'doc_2': array([ 30., 31., 32.], dtype=float32) 'doc_1': array([ 20., 21., 22.], dtype=float32)} {'doc_1_doc_2': 300.0]) 'doc_0_doc_2': 1200.0]) 'doc_1_doc_0': 300.0]) 'doc_0_doc_1': 300.0]) 'doc_2_doc_1': 300.0]) 'doc_2_doc_0': 1200.0} - Looks like the data structures that are used in the tutorials are all using panda.
- Successfully installed pandas-0.19.2
Phil 3.4.17
- Helena sent a nice link to Announcing New Research: “A Field Guide to Fake News” it’s from First Draft News, which purports to be Essential resources for reporting and sharing information that emerges online
- Woke up this morning thinking about Pervasive Serendipity, which relates to Cass Sunstein’s musings on a Serendipity bar/button. Added that to the paper
- Also added the Lynch paper on online clustering in Egypt
Aaron 3.3.17
- Architecture Status
- Sent out the reasonably in-depth write-up of the proposed design for complex automatic clustering yesterday and expected to get at least a few questions or comments back; I ended up having to spend far more of my day than I wanted responding.
- The good news is that the overall design is approved and one of our other lead MapReduce developers is up to speed on what we need to do. I’ll begin sending him some links and we’ll follow up on starting to generate code in between the sprints.
- TensorFlow
- I haven’t gotten even a fraction of the time spent researching this that I wanted, so I’m well behind the learning curve as Phil blazes trails. My hope is that his lessons learned can help me come up to speed more quickly.
- I’m going to continue some tutorials/videos today to get caught up so next week I can chase down the Protobuff format I need to generate with the comparison tensor.
- I did get a chance to watch some more tutorials today covering cross-entropy loss method that made a lot of sense.
- Cycling
- I went for a brief ride today (only 5 miles) and managed to fall off my bike for the first time. I went to stop at an intersection and unclipped my left foot fine, when I went to unclip my right foot, the cold-weather boot caught on the pedal and sent me crashing onto the curb. Fortunately I was bundled up enough that I didn’t get badly hurt, just bent my thumbnail back. Got back on the bike and completed the rest of the ride. I was still too sore to do the 12.5 mile today, especially in 20 mph winds.

You must be logged in to post a comment.