
Reading Clockwork Muse. Machines don’t really have a desire for novelty directly. But they do have the derivative of arousal potential. That comes from us, their creators. Machines on their own won’t change. Yet. This is a manifestation of their non-evolutionary history. When machines can seek novelty and become bored is when they will become recognizable as entities.
Listening to Hidden Brain – One Head, Two Brains: How The Brain’s Hemispheres Shape The World We See (transcript)
- This week on Hidden Brain, we dive into Iain’s research on how the left and right hemispheres shape our perceptions. Iain argues that differences in the brain — and Western society’s preference for what one hemisphere has to offer — have had enormous effects on our lives.
- VEDANTAM: One of the important differences you point out is sort of understanding the role of metaphor in language. For example, which is that the left hemisphere really is incapable of understanding what metaphor is or how it works.
- MCGILCHRIST: Yes. And that’s no small thing because as some philosophers have pointed out, metaphor is how we understand everything. And they point out that, actually, particularly scientific and philosophical understanding is mediated by metaphors. In other words, the only way we can understand something is in terms of something else that we think we already understand. And it’s making the analogy, which is what a metaphor does, that enables us to go, I see, I get it. Now, if you think that metaphor is just one of those dispensable decorations that you could add to meaning – it’s kind of nice but probably a distraction from the real meaning – you’ve got it upside down. Because if you don’t understand the metaphor, you haven’t understood the meaning. Literal meaning, however, is a peripheral, diminished version of the richness of metaphorical understanding. And what we know is the right hemisphere understands those implicit meanings, those connections of meanings, what we call connotations, as well as just denotations. It understands imagery. It understands humor. It understands all of that.
- VEDANTAM: Have you ever wondered whether you, yourself, might be captive to your left hemisphere and you, potentially, now can’t see the problems with your own model?
- MCGILCHRIST: That’s a very good point. And it’s not – I’m not critical of models, actually, in themselves. I’m critical of particular models because, in fact, we can’t understand anything – this is one of my basic points – except by having a model with which we compare it. So that is always a limitation. We don’t move from a world in which we have models to a better one in which we don’t. We move from a bad model to a better one. So every model has its limitations, but some form, simply, a better fit. And that is what the progress of science is.
This thread is wild. It’s how to force a stampede: 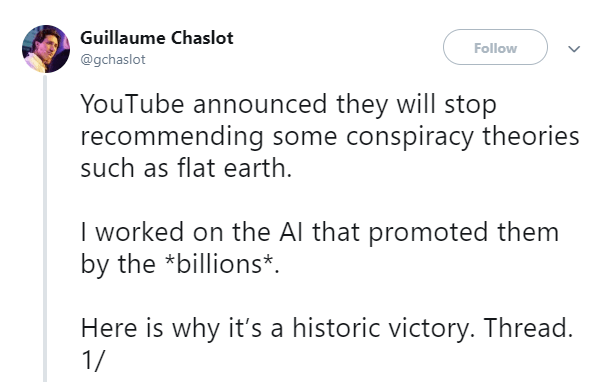










You must be logged in to post a comment.