GLM-130B is an open bilingual (English & Chinese) bidirectional dense model with 130 billion parameters, pre-trained using the algorithm of General Language Model (GLM). It is designed to support inference tasks with the 130B parameters on a single A100 (40G * 8) or V100 (32G * 8) server. With INT4 quantization, the hardware requirements can further be reduced to a single server with 4 * RTX 3090 (24G) with almost no performance degradation. As of July 3rd, 2022, GLM-130B has been trained on over 400 billion text tokens (200B each for Chinese and English)
In this video, we will learn how to use the Cohere Embed API endpoint to generate language embeddings using a large language model (LLM) and then index those embeddings in the Pinecone vector database for fast and scalable vector search. Cohere is an AI company that allows us to use state-of-the-art large language models (LLMs) in NLP. The Cohere Embed endpoint we use in this video gives us access to models similar to other popular LLMs like OpenAI’s GPT 3, particularly their recent offerings via OpenAI Embeddings like the text-embedding-ada-002 model. Pinecone is a vector database company allowing us to use state-of-the-art vector search through millions or even billions of data points.
We in the Federal Government developed this Roadmap through sustained discussion across Federal agencies and through numerous consultations with academic researchers, commercial entities, international partners, those adversely affected by corrupted information, former government employees across the political spectrum, and others seeking to address information integrity challenges.
GPT Takes the Bar Exam
Nearly all jurisdictions in the United States require a professional license exam, commonly referred to as “the Bar Exam,” as a precondition for law practice. To even sit for the exam, most jurisdictions require that an applicant completes at least seven years of post-secondary education, including three years at an accredited law school. In addition, most test-takers also undergo weeks to months of further, exam-specific preparation. Despite this significant investment of time and capital, approximately one in five test-takers still score under the rate required to pass the exam on their first try. In the face of a complex task that requires such depth of knowledge, what, then, should we expect of the state of the art in “AI?” In this research, we document our experimental evaluation of the performance of OpenAI’s `text-davinci-003` model, often-referred to as GPT-3.5, on the multistate multiple choice (MBE) section of the exam. While we find no benefit in fine-tuning over GPT-3.5’s zero-shot performance at the scale of our training data, we do find that hyperparameter optimization and prompt engineering positively impacted GPT-3.5’s zero-shot performance. For best prompt and parameters, GPT-3.5 achieves a headline correct rate of 50.3% on a complete NCBE MBE practice exam, significantly in excess of the 25% baseline guessing rate, and performs at a passing rate for both Evidence and Torts. GPT-3.5’s ranking of responses is also highly-correlated with correctness; its top two and top three choices are correct 71% and 88% of the time, respectively, indicating very strong non-entailment performance. While our ability to interpret these results is limited by nascent scientific understanding of LLMs and the proprietary nature of GPT, we believe that these results strongly suggest that an LLM will pass the MBE component of the Bar Exam in the near future.
From the ICML Call for papers:
SBIRs
Meeting with Aaron? Most of the day, actually
Meeting with Rukan? Comment and zip up code with example spreadsheets by Thursday
GPT-Agents
Roll in Shimei’s changes – done
4:00 Meeting. A lot of discussion about students cheating with the GPT. For foreign students in particular, the pressures to succeed and get an advanced degree seem to outweigh the penalties of plagiarism, much less using LLMs to write text. It’s a point that should be added to the essay.
This is a Python project that generates a digest of popular Mastodon posts from your home timeline. The digest is generated locally. The digests present two lists: posts from users you follow, and boosts from your followers. Each list is constructed by respecting your server-side content filters and identifying content that you haven’t yet interacted with. Digests are automatically opened locally in your web browser. You can adjust the digest algorithm to suit your liking (see Command arguments).
Really not feeling motivated. It’s been raining for 36 hours or so, and then it’s going to get cold. By Tuesday, things should be getting back to seasonal, and then even a little nice by Friday
SBIRs
More MORS. Get a first pass through the conclusions – done! Currently at 18 pages with references
In recent years, the number of parameters of one deep learning (DL) model has been growing much faster than the growth of GPU memory space. People who are inaccessible to a large number of GPUs resort to heterogeneous training systems for storing model parameters in CPU memory. Existing heterogeneous systems are based on parallelization plans in the scope of the whole model. They apply a consistent parallel training method for all the operators in the computation. Therefore, engineers need to pay a huge effort to incorporate a new type of model parallelism and patch its compatibility with other parallelisms. For example, Mixture-of-Experts (MoE) is still incompatible with ZeRO-3 in Deepspeed. Also, current systems face efficiency problems on small scale, since they are designed and tuned for large-scale training. In this paper, we propose Elixir, a new parallel heterogeneous training system, which is designed for efficiency and flexibility. Elixir utilizes memory resources and computing resources of both GPU and CPU. For flexibility, Elixir generates parallelization plans in the granularity of operators. Any new type of model parallelism can be incorporated by assigning a parallel pattern to the operator. For efficiency, Elixir implements a hierarchical distributed memory management scheme to accelerate inter-GPU communications and CPU-GPU data transmissions. As a result, Elixir can train a 30B OPT model on an A100 with 40GB CUDA memory, meanwhile reaching 84% efficiency of Pytorch GPU training. With its super-linear scalability, the training efficiency becomes the same as Pytorch GPU training on multiple GPUs. Also, large MoE models can be trained 5.3x faster than dense models of the same size. Now Elixir is integrated into ColossalAI and is available on its main branch.
I think the ChatGPT article should be on teaching critical thinking with large language models
Generating a chain of thought (CoT) can increase large language model (LLM) performance on a wide range of tasks. Zero-shot CoT evaluations, however, have been conducted primarily on logical tasks (e.g. arithmetic, commonsense QA). In this paper, we perform a controlled evaluation of zero-shot CoT across two sensitive domains: harmful questions and stereotype benchmarks. We find that using zero-shot CoT reasoning in a prompt can significantly increase a model’s likelihood to produce undesirable output. Without future advances in alignment or explicit mitigation instructions, zero-shot CoT should be avoided on tasks where models can make inferences about marginalized groups or harmful topics.
Read Fair Use chapter from The Librarian’s Guide to Intellectual Property in the Digital Age. Done. It makes me think that I can redraw the images as sketches and should be ok.
SBIRs
Sprint planning, looks like make videos and work on JMOR paper
Let this be my personal notice to Twitter developers: The team is gone; the investment has been undone. Love does not live here anymore.
Twitter is banning journalists and links to Mastodon instances. I did discover that you can follow a particular instance, which is very nice, but not supported in the API. All you have to do though is create a browser tab for the local timeline for that instance. For example
I need to code up a web page that can do that in a tweetdeck format and handle replies from your particular account. I think that it should be pretty easy. Something for January. Regardless, here’s the basics of accessing any instance timeline:
import json
import requests
# A playground for exploring the Mastodon REST interface (https://docs.joinmastodon.org/client/public/)
# Mastodon API: https://docs.joinmastodon.org/api/
# Mastodon client getting started with the API: https://docs.joinmastodon.org/client/intro/
def create_timeline_url(instance:str = "mastodon.social", limit:int=10):
url = "https://{}/api/v1/timelines/public?limit={}".format(instance, limit)
print("create_timeline_url(): {}".format(url))
return url
def connect_to_endpoint(url) -> json:
response = requests.request("GET", url)
print("Status code = : {}".format(response.status_code))
if response.status_code != 200:
raise Exception(
"Request returned an error: {} {}".format(
response.status_code, response.text
)
)
return response.json()
def print_response(title:str, j:json):
json_str = json.dumps(j, indent=4, sort_keys=True)
print("\n------------ Begin '{}':\nresponse:\n{}\n------------ End '{}'\n".format(title, json_str, title))
def main():
print("post_lookup")
instance_list = ["fediscience.org", "sigmoid.social"]
for instance in instance_list:
url = create_timeline_url(instance, 1)
rsp = connect_to_endpoint(url)
print_response("{} test:".format(instance), rsp)
if __name__ == "__main__":
main()
Book
Finish copyright spreadsheet?
SBIRs
Scan more of War Elephants – done
Add history.tex and put the applicable quotes and thoughts
Finish the first pass at interfaces – done
Meeting with Ron? Two, in fact
GPT Agents
Partial pull on item 19. Need to retry later. The API crashed, apparently but came back up. Need to add some exception handling for that next time
Update proposal with latest numbers. Also reference Amir Shevat’s tech crunch article about his expectation that the API will fail
This is what I mean when I talk about the power of social communication vs monolithic models. The idea of using models to generate IP-protected work moved quickly through the artist community, while the process of producing models that won’t generate these images will be harder. Either the models have to be re-trained or filtered.
We are excited to announce a new embedding model which is significantly more capable, cost effective, and simpler to use. The new model, text-embedding-ada-002, replaces five separate models for text search, text similarity, and code search, and outperforms our previous most capable model, Davinci, at most tasks, while being priced 99.8% lower.
We analyze the storage and recall of factual associations in autoregressive transformer language models, finding evidence that these associations correspond to localized, directly-editable computations. We first develop a causal intervention for identifying neuron activations that are decisive in a model’s factual predictions. This reveals a distinct set of steps in middle-layer feed-forward modules that mediate factual predictions while processing subject tokens. To test our hypothesis that these computations correspond to factual association recall, we modify feed-forward weights to update specific factual associations using Rank-One Model Editing (ROME). We find that ROME is effective on a standard zero-shot relation extraction (zsRE) model-editing task, comparable to existing methods. To perform a more sensitive evaluation, we also evaluate ROME on a new dataset of counterfactual assertions, on which it simultaneously maintains both specificity and generalization, whereas other methods sacrifice one or another. Our results confirm an important role for mid-layer feed-forward modules in storing factual associations and suggest that direct manipulation of computational mechanisms may be a feasible approach for model editing. The code, dataset, visualizations, and an interactive demo notebook are available at this https URL
Changing how pre-trained models behave — e.g., improving their performance on a downstream task or mitigating biases learned during pre-training — is a common practice when developing machine learning systems. In this work, we propose a new paradigm for steering the behavior of neural networks, centered around \textit{task vectors}. A task vector specifies a direction in the weight space of a pre-trained model, such that movement in that direction improves performance on the task. We build task vectors by subtracting the weights of a pre-trained model from the weights of the same model after fine-tuning on a task. We show that these task vectors can be modified and combined together through arithmetic operations such as negation and addition, and the behavior of the resulting model is steered accordingly. Negating a task vector decreases performance on the target task, with little change in model behavior on control tasks. Moreover, adding task vectors together can improve performance on multiple tasks at once. Finally, when tasks are linked by an analogy relationship of the form “A is to B as C is to D”, combining task vectors from three of the tasks can improve performance on the fourth, even when no data from the fourth task is used for training. Overall, our experiments with several models, modalities and tasks show that task arithmetic is a simple, efficient and effective way of editing models.
Large, text-conditioned generative diffusion models have recently gained a lot of attention for their impressive performance in generating high-fidelity images from text alone. However, achieving high-quality results is almost unfeasible in a one-shot fashion. On the contrary, text-guided image generation involves the user making many slight changes to inputs in order to iteratively carve out the envisioned image. However, slight changes to the input prompt often lead to entirely different images being generated, and thus the control of the artist is limited in its granularity. To provide flexibility, we present the Stable Artist, an image editing approach enabling fine-grained control of the image generation process. The main component is semantic guidance (SEGA) which steers the diffusion process along variable numbers of semantic directions. This allows for subtle edits to images, changes in composition and style, as well as optimization of the overall artistic conception. Furthermore, SEGA enables probing of latent spaces to gain insights into the representation of concepts learned by the model, even complex ones such as ‘carbon emission’. We demonstrate the Stable Artist on several tasks, showcasing high-quality image editing and composition.
More MORS. Going to have to add some things to reflect this:
GPT Agents
Continue downloads
Jason’s back!
4:00 Meeting
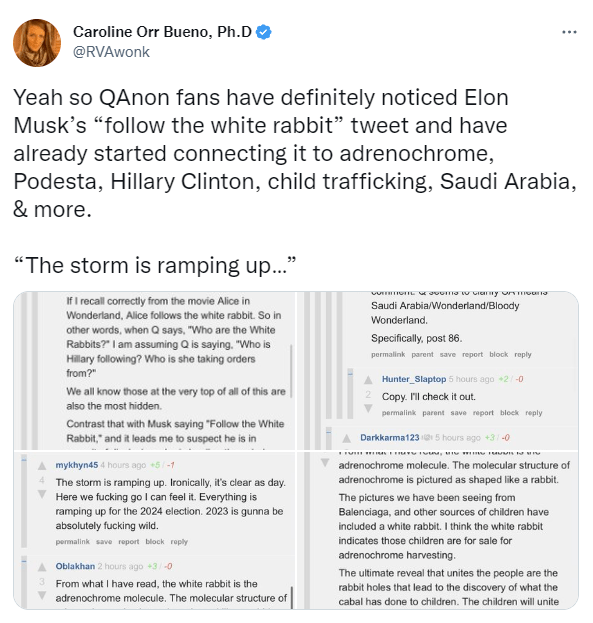
Just realized that I need to do a set of pulls over the last two months or so with variations of Elon Musk. Then we can see if anything has changed pre and post acquisition.
Jefferson Cowie’s powerful and sobering new history, “Freedom’s Dominion,” traces the close association between the rhetoric of liberty in an Alabama county and the politics of white supremacy.












You must be logged in to post a comment.