
7:00 – 10:00 Thesis/VTX
- Built a new matrix for the coded lit review. I had coded a couple of more papers
- Working on copying over the read papers into a new folder that I can run text analytics over
- After carefully reading through the doc manager list and copying over each paper, I just discovered I could have exported selected.
- Ooops: Exception in thread “JavaFX Application Thread” java.lang.IllegalArgumentException: Invalid column index (16384). Allowable column range for EXCEL2007 is (0..16383) or (‘A’..’XFD’)
- Going to add a limit of
SpreadsheetVersion.EXCEL2007.getMaxColumns()-8
columns for now. Clearly that can be cut down.
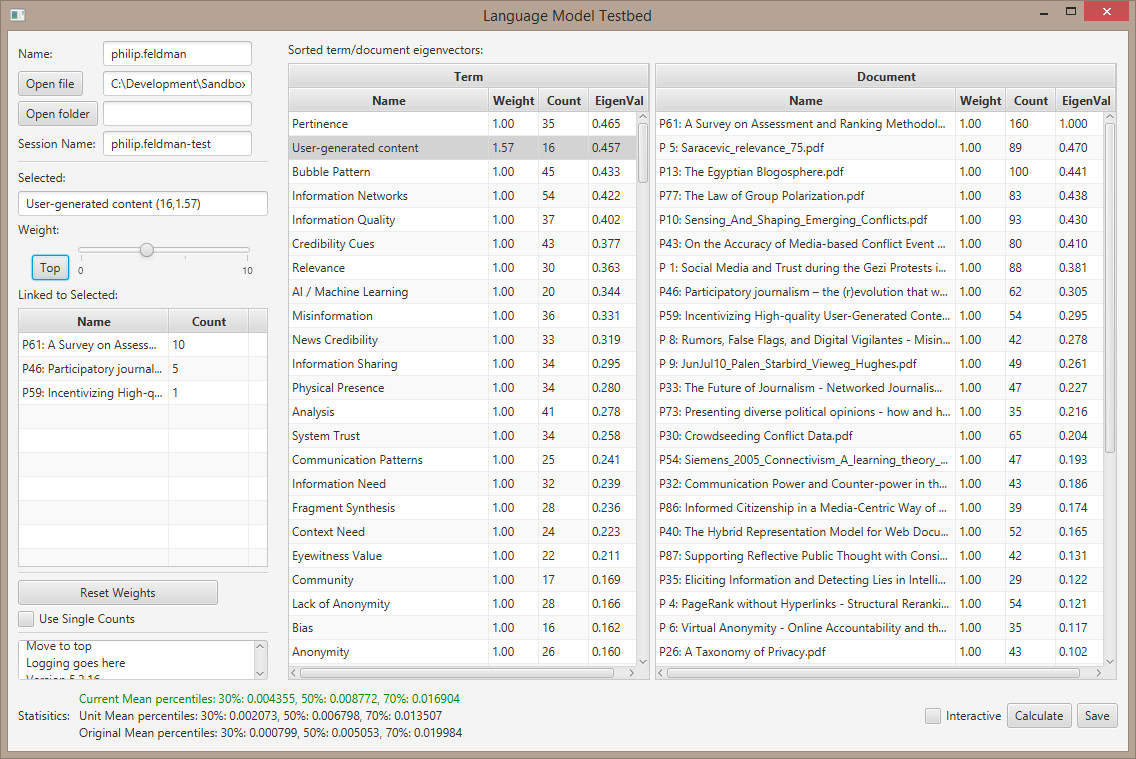
- Figuring out where to cut the terms. I’m summing the columns of the LSI calculation, starting at the highest value and then dividing that by the sum of all values. The top 20% of rank weights gives 280 columns. Going to try that first
- Success! Some initial thoughts
- The coded version is much more ‘crisp’
- There are interesting hints in the LSI version
- Clicking on a term or paper to see the associated items is really nice.
- I think that document subgroups might be good/better, and it might be possible to use the tool to help build those subgroups. This goes back to the ‘hiding’ concept. (hide item / hide item and associated)
- Going to add a limit of



You must be logged in to post a comment.