
Nice – I can get my notes of the Kindle by plugging it into my computer. I never found that on the help pages.
More than a Million Pro-Repeal Net Neutrality Comments were Likely Faked
- I used natural language processing techniques to analyze net neutrality comments submitted to the FCC from April-October 2017, and the results were disturbing.
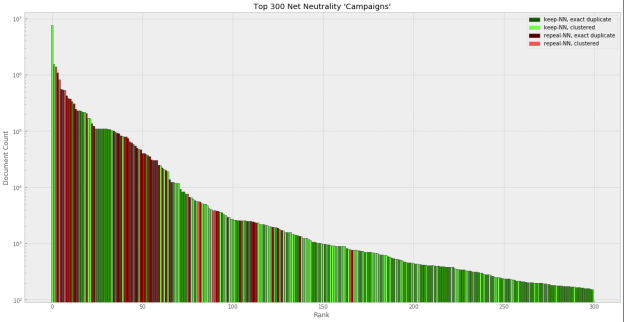 I think that this kind of long-tail distribution is going to be what herding looks like.
I think that this kind of long-tail distribution is going to be what herding looks like.
Speaker–listener neural coupling underlies successful communication
-
- Greg J. Stephens
- Lauren J. Silbert
- Uri Hasson (HassonLab at Princeton)
- Verbal communication is a joint activity; however, speech production and comprehension have primarily been analyzed as independent processes within the boundaries of individual brains. Here, we applied fMRI to record brain activity from both speakers and listeners during natural verbal communication. We used the speaker’s spatiotemporal brain activity to model listeners’ brain activity and found that the speaker’s activity is spatially and temporally coupled with the listener’s activity. This coupling vanishes when participants fail to communicate. Moreover, though on average the listener’s brain activity mirrors the speaker’s activity with a delay, we also find areas that exhibit predictive anticipatory responses. We connected the extent of neural coupling to a quantitative measure of story comprehension and find that the greater the anticipatory speaker–listener coupling, the greater the understanding. We argue that the observed alignment of production- and comprehension-based processes serves as a mechanism by which brains convey information.
- This seems to be the root article for neural coupling. It seems to be an area of vigorous study, with lots of work coming out from the three authors.
- The study design is also really good.
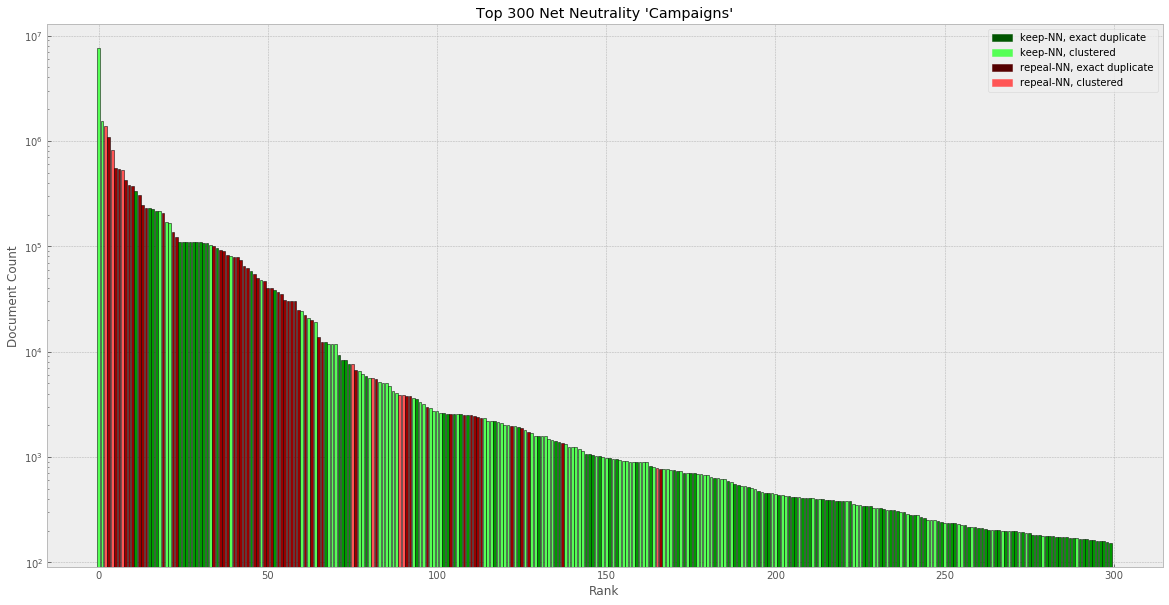
- In this study we directly examine the spatial and temporal coupling between production and comprehension across brains during natural verbal communication. (pp 14425)
- Using fMRI, we recorded the brain activity of a speaker telling an unrehearsed real-life story and the brain activity … (n = 11) of a listener listening to the recorded audio of the spoken story, thereby capturing the time-locked neural dynamics from both sides of the communication. Finally, we used a detailed questionnaire to assess the level of comprehension of each listener. (pp 14425)
- …because communication unfolds over time, this coupling will exhibit important temporal structure. In particular, because the speaker’s production-based processes mostly precede the listener’s comprehension-based processes, the listener’s neural dynamics will mirror the speaker’s neural dynamics with some delay. Conversely, when listeners use their production system to emulate and predict the speaker’s utterances, we expect the opposite: the listener’s dynamics will precede the speaker’s dynamics. (pp 14425)
- To analyze the direct interaction of production and comprehension mechanisms, we considered only spatially local models that measure the degree of speaker–listener coupling within the same Talairach location. (pp 14426)
- we also observed significant speaker–listener coupling in a collection of extralinguistic areas known to be involved in the processing of semantic and social aspects of the story (19), including the precuneus, dorsolateral prefrontal cortex, orbitofrontal cortex, striatum, and medial prefrontal cortex. (pp 14426)
- In agreement with previous work, the story evoked highly reliable activity inmany brain areas across all listeners (8, 11, 12) (Fig. 2B, yellow). We note that the agreement with previous work is far from assured: the story here was both personal and spontaneous, and was recorded in the noisy environment of the scanner. The similarity in the response patterns across all listeners underscores a strong tendency to process incoming verbal information in similar ways. A comparison between the speaker–listener and the listener–listenermaps reveals an extensive overlap (Fig. 2B, orange). These areas include many of the sensory related, classic linguistic-related and extralinguistic-related brain areas, demonstrating that many of the areas involved in speech comprehension (listener–listener coupling) are also aligned during communication (speaker–listener coupling). (pp 14426)
- To test whether the extensive speaker–listener coupling emerges only when information is transferred across interlocutors, we blocked the communication between speaker and listener. We repeated the experiment while recording a Russian speaker telling a story in the scanner, and then played the story to non–Russian speaking listeners (n = 11). In this experimental setup, although the Russian speaker is trying to communicate information, the listeners are unable to extract the information from the incoming acoustic sounds. Using identical analysis methods and statistical thresholds, we found no significant coupling between the speaker and the listeners or among the listeners. At significantly lower thresholds we found that the non–Russian-speaking listener–listener coupling was confined to early auditory cortices. This indicates that the reliable activity in most areas, besides early auditory cortex, depends on a successful processing of the incoming information, and is not driven by the low-level acoustic aspects of the stimuli. (pp 14426)
- In my model, the anticipation is modeled by the alignment and velocity, but others come to similar conclusions. It may be a way of dealing with noisy environments. Which would be another way of saying group dynamics with incomplete information.
- Our analysis also identifies a subset of brain regions in which the activity in the listener’s brain precedes the activity in the speaker’s brain. The listener’s anticipatory responses were localized to areas known to be involved in predictions and value representation (pp 14428)
- Such findings are in agreement with the theory of interactive linguistic alignment (1). According to this theory, production and comprehension become tightly aligned on many different levels during verbal communication, including the phonetic, phonological, lexical, syntactic, and semantic representations. Accordingly, we observed neural coupling during communication at many different processing levels, including low-level auditory areas (induced by the shared input), production-based areas (e.g., Broca’s area), comprehension based areas (e.g., Wernicke’s area and TPJ), and high-order extralinguistic areas (e.g., precuneus and mPFC) that can induce shared contextual model of the situation (34). Interestingly, some of these extralinguistic areas are known to be involved in processing social information crucial for successful communication, including, among others, the capacity to discern the beliefs, desires, and goals of others. (pp 14429)
Brain-to-Brain coupling: A mechanism for creating and sharing a social world
- Cognition materializes in an interpersonal space. The emergence of complex behaviors requires the coordination of actions among individuals according to a shared set of rules. Despite the central role of other individuals in shaping our minds, most cognitive studies focus on processes that occur within a single individual. We call for a shift from a single-brain to a multi-brain frame of reference. We argue that in many cases the neural processes in one brain are coupled to the neural processes in another brain via the transmission of a signal through the environment. Brain-to-brain coupling constrains and simplifies the actions of each individual in a social network, leading to complex joint behaviors that could not have emerged in isolation







You must be logged in to post a comment.